 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoClinician: A Self-Evolving Agent for Multi-Turn Medical Diagnosis via Test-Time Evolutionary Learning
Jan 30, 2026Prevailing medical AI operates on an unrealistic ''one-shot'' model, diagnosing from a complete patient file. However, real-world diagnosis is an iterative inquiry where Clinicians sequentially ask questions and order tests to strategically gather information while managing cost and time. To address this, we first propose Med-Inquire, a new benchmark designed to evaluate an agent's ability to perform multi-turn diagnosis. Built upon a dataset of real-world clinical cases, Med-Inquire simulates the diagnostic process by hiding a complete patient file behind specialized Patient and Examination agents. They force the agent to proactively ask questions and order tests to gather information piece by piece. To tackle the challenges posed by Med-Inquire, we then introduce EvoClinician, a self-evolving agent that learns efficient diagnostic strategies at test time. Its core is a ''Diagnose-Grade-Evolve'' loop: an Actor agent attempts a diagnosis; a Process Grader agent performs credit assignment by evaluating each action for both clinical yield and resource efficiency; finally, an Evolver agent uses this feedback to update the Actor's strategy by evolving its prompt and memory. Our experiments show EvoClinician outperforms continual learning baselines and other self-evolving agents like memory agents. The code is available at https://github.com/yf-he/EvoClinician
Conversation for Non-verifiable Learning: Self-Evolving LLMs through Meta-Evaluation
Jan 29, 2026Training large language models (LLMs) for non-verifiable tasks, such as creative writing, dialogue, and ethical reasoning, remains challenging due to the absence of ground-truth labels. While LLM-as-Judge approaches offer a scalable alternative to human feedback, they face a fundamental limitation: performance is constrained by the evaluator's own quality. If the judge cannot recognize good solutions, it cannot provide useful training signals, and evaluation biases (e.g., favoring verbosity over quality) remain unaddressed. This motivates meta-evaluation: the ability to evaluate and improve the evaluator itself. We introduce CoNL, a framework that unifies generation, evaluation, and meta-evaluation through multi-agent self-play. Our key insight: critique quality can be measured by whether it helps others improve their solutions. In CoNL, multiple agents sharing the same policy engage in structured conversations to propose, critique, and revise solutions. Critiques that enable solution improvements earn a diagnostic reward, creating explicit supervision for meta-evaluation and enabling joint optimization of generation and judging capabilities through self-play, without external judges or ground truth. Experiments on five benchmarks show that CoNL achieves consistent improvements over self-rewarding baselines while maintaining stable training.
What-If Analysis of Large Language Models: Explore the Game World Using Proactive Thinking
Sep 05, 2025Large language models (LLMs) excel at processing information reactively but lack the ability to systemically explore hypothetical futures. They cannot ask, "what if we take this action? how will it affect the final outcome" and forecast its potential consequences before acting. This critical gap limits their utility in dynamic, high-stakes scenarios like strategic planning, risk assessment, and real-time decision making. To bridge this gap, we propose WiA-LLM, a new paradigm that equips LLMs with proactive thinking capabilities. Our approach integrates What-If Analysis (WIA), a systematic approach for evaluating hypothetical scenarios by changing input variables. By leveraging environmental feedback via reinforcement learning, WiA-LLM moves beyond reactive thinking. It dynamically simulates the outcomes of each potential action, enabling the model to anticipate future states rather than merely react to the present conditions. We validate WiA-LLM in Honor of Kings (HoK), a complex multiplayer game environment characterized by rapid state changes and intricate interactions. The game's real-time state changes require precise multi-step consequence prediction, making it an ideal testbed for our approach. Experimental results demonstrate WiA-LLM achieves a remarkable 74.2% accuracy in forecasting game-state changes (up to two times gain over baselines). The model shows particularly significant gains in high-difficulty scenarios where accurate foresight is critical. To our knowledge, this is the first work to formally explore and integrate what-if analysis capabilities within LLMs. WiA-LLM represents a fundamental advance toward proactive reasoning in LLMs, providing a scalable framework for robust decision-making in dynamic environments with broad implications for strategic applications.
Enabling Self-Improving Agents to Learn at Test Time With Human-In-The-Loop Guidance
Jul 23, 2025Large language model (LLM) agents often struggle in environments where rules and required domain knowledge frequently change, such as regulatory compliance and user risk screening. Current approaches, like offline fine-tuning and standard prompting, are insufficient because they cannot effectively adapt to new knowledge during actual operation. To address this limitation, we propose the Adaptive Reflective Interactive Agent (ARIA), an LLM agent framework designed specifically to continuously learn updated domain knowledge at test time. ARIA assesses its own uncertainty through structured self-dialogue, proactively identifying knowledge gaps and requesting targeted explanations or corrections from human experts. It then systematically updates an internal, timestamped knowledge repository with provided human guidance, detecting and resolving conflicting or outdated knowledge through comparisons and clarification queries. We evaluate ARIA on the realistic customer due diligence name screening task on TikTok Pay, alongside publicly available dynamic knowledge tasks. Results demonstrate significant improvements in adaptability and accuracy compared to baselines using standard offline fine-tuning and existing self-improving agents. ARIA is deployed within TikTok Pay serving over 150 million monthly active users, confirming its practicality and effectiveness for operational use in rapidly evolving environments.
Meta-Reasoner: Dynamic Guidance for Optimized Inference-time Reasoning in Large Language Models
Feb 27, 2025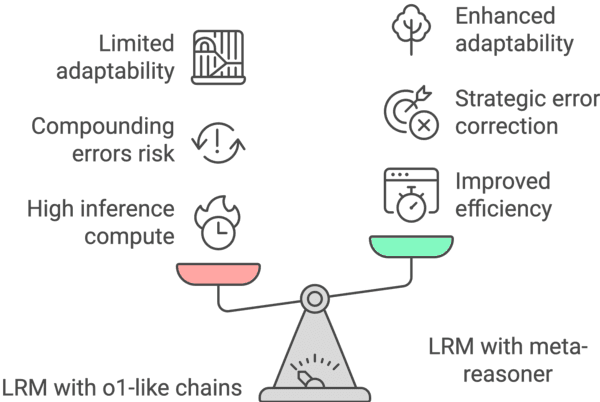
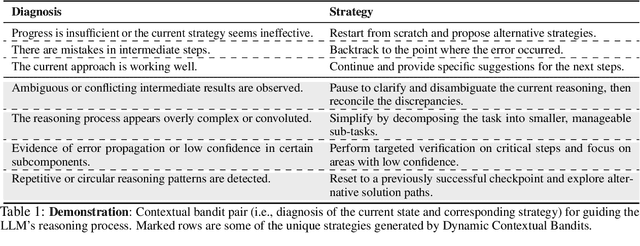
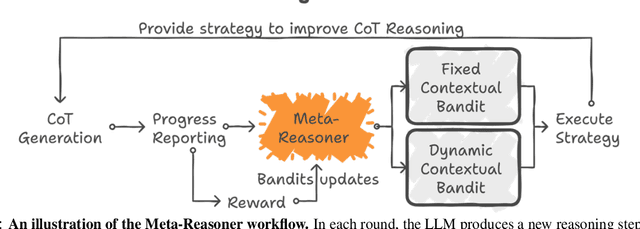
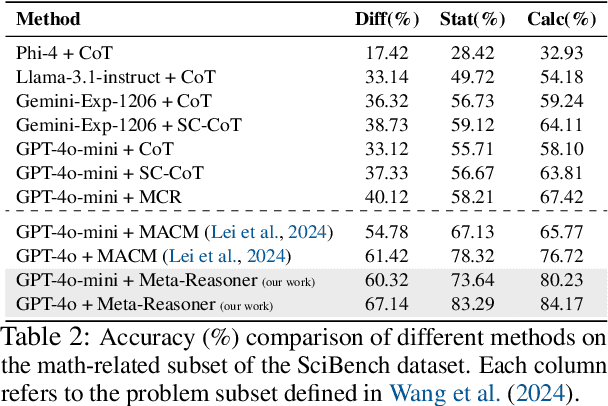
Large Language Models (LLMs) increasingly rely on prolonged reasoning chains to solve complex tasks. However, this trial-and-error approach often leads to high computational overhead and error propagation, where early mistakes can derail subsequent steps. To address these issues, we introduce Meta-Reasoner, a framework that dynamically optimizes inference-time reasoning by enabling LLMs to "think about how to think." Drawing inspiration from human meta-cognition and dual-process theory, Meta-Reasoner operates as a strategic advisor, decoupling high-level guidance from step-by-step generation. It employs "contextual multi-armed bandits" to iteratively evaluate reasoning progress, and select optimal strategies (e.g., backtrack, clarify ambiguity, restart from scratch, or propose alternative approaches), and reallocates computational resources toward the most promising paths. Our evaluations on mathematical reasoning and puzzles highlight the potential of dynamic reasoning chains to overcome inherent challenges in the LLM reasoning process and also show promise in broader applications, offering a scalable and adaptable solution for reasoning-intensive tasks.
UniGraph2: Learning a Unified Embedding Space to Bind Multimodal Graphs
Feb 02, 2025



Existing foundation models, such as CLIP, aim to learn a unified embedding space for multimodal data, enabling a wide range of downstream web-based applications like search, recommendation, and content classification. However, these models often overlook the inherent graph structures in multimodal datasets, where entities and their relationships are crucial. Multimodal graphs (MMGs) represent such graphs where each node is associated with features from different modalities, while the edges capture the relationships between these entities. On the other hand, existing graph foundation models primarily focus on text-attributed graphs (TAGs) and are not designed to handle the complexities of MMGs. To address these limitations, we propose UniGraph2, a novel cross-domain graph foundation model that enables general representation learning on MMGs, providing a unified embedding space. UniGraph2 employs modality-specific encoders alongside a graph neural network (GNN) to learn a unified low-dimensional embedding space that captures both the multimodal information and the underlying graph structure. We propose a new cross-domain multi-graph pre-training algorithm at scale to ensure effective transfer learning across diverse graph domains and modalities. Additionally, we adopt a Mixture of Experts (MoE) component to align features from different domains and modalities, ensuring coherent and robust embeddings that unify the information across modalities. Extensive experiments on a variety of multimodal graph tasks demonstrate that UniGraph2 significantly outperforms state-of-the-art models in tasks such as representation learning, transfer learning, and multimodal generative tasks, offering a scalable and flexible solution for learning on MMGs.
Can Knowledge Graphs Make Large Language Models More Trustworthy? An Empirical Study over Open-ended Question Answering
Oct 10, 2024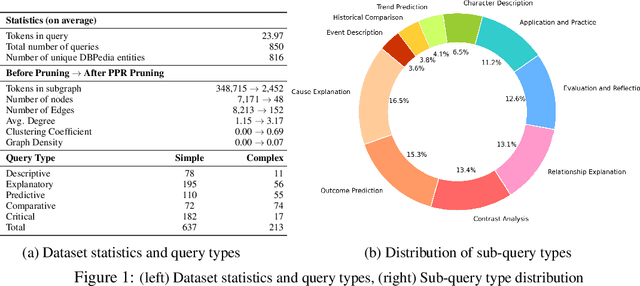
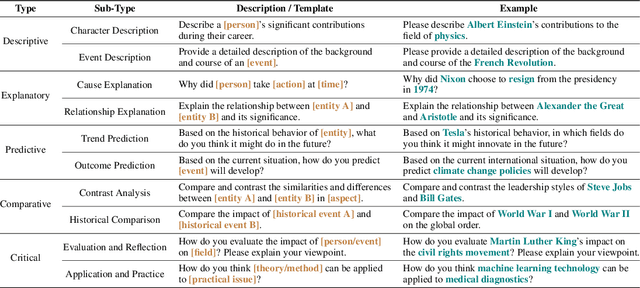
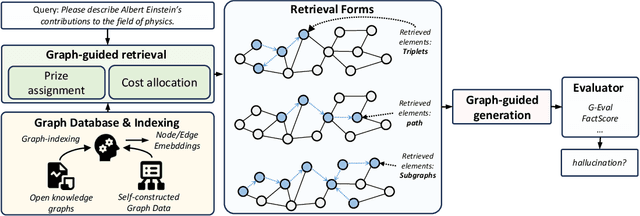
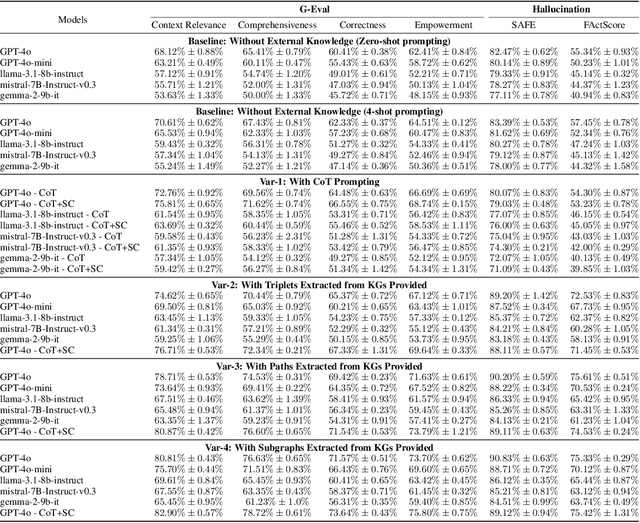
Recent works integrating Knowledge Graphs (KGs) have led to promising improvements in enhancing reasoning accuracy of Large Language Models (LLMs). However, current benchmarks mainly focus on closed tasks, leaving a gap in the assessment of more complex, real-world scenarios. This gap has also obscured the evaluation of KGs' potential to mitigate the problem of hallucination in LLMs. To fill the gap, we introduce OKGQA, a new benchmark specifically designed to assess LLMs enhanced with KGs under open-ended, real-world question answering scenarios. OKGQA is designed to closely reflect the complexities of practical applications using questions from different types, and incorporates specific metrics to measure both the reduction in hallucinations and the enhancement in reasoning capabilities. To consider the scenario in which KGs may have varying levels of mistakes, we further propose another experiment setting OKGQA-P to assess model performance when the semantics and structure of KGs are deliberately perturbed and contaminated. OKGQA aims to (1) explore whether KGs can make LLMs more trustworthy in an open-ended setting, and (2) conduct a comparative analysis to shed light on methods and future directions for leveraging KGs to reduce LLMs' hallucination. We believe that this study can facilitate a more complete performance comparison and encourage continuous improvement in integrating KGs with LLMs.
FiDeLiS: Faithful Reasoning in Large Language Model for Knowledge Graph Question Answering
May 22, 2024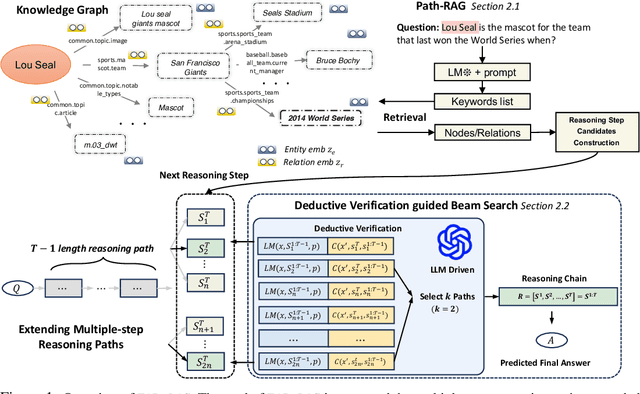



While large language models (LLMs) have achieved significant success in various applications, they often struggle with hallucinations, especially in scenarios that require deep and responsible reasoning. These issues could be partially mitigate by integrating external knowledge graphs (KG) in LLM reasoning. However, the method of their incorporation is still largely unexplored. In this paper, we propose a retrieval-exploration interactive method, FiDelis to handle intermediate steps of reasoning grounded by KGs. Specifically, we propose Path-RAG module for recalling useful intermediate knowledge from KG for LLM reasoning. We incorporate the logic and common-sense reasoning of LLMs and topological connectivity of KGs into the knowledge retrieval process, which provides more accurate recalling performance. Furthermore, we propose to leverage deductive reasoning capabilities of LLMs as a better criterion to automatically guide the reasoning process in a stepwise and generalizable manner. Deductive verification serve as precise indicators for when to cease further reasoning, thus avoiding misleading the chains of reasoning and unnecessary computation. Extensive experiments show that our method, as a training-free method with lower computational cost and better generality outperforms the existing strong baselines in three benchmarks.
TAP4LLM: Table Provider on Sampling, Augmenting, and Packing Semi-structured Data for Large Language Model Reasoning
Dec 14, 2023



Table reasoning has shown remarkable progress in a wide range of table-based tasks. These challenging tasks require reasoning over both free-form natural language (NL) questions and semi-structured tabular data. However, previous table reasoning solutions suffer from significant performance degradation on "huge" tables. In addition, most existing methods struggle to reason over complex questions since they lack essential information or they are scattered in different places. To alleviate these challenges, we exploit a table provider, namely TAP4LLM, on versatile sampling, augmentation, and packing methods to achieve effective semi-structured data reasoning using large language models (LLMs), which 1) decompose raw tables into sub-tables with specific rows or columns based on the rules or semantic similarity; 2) augment table information by extracting semantic and statistical metadata from raw tables while retrieving relevant knowledge from trustworthy knowledge sources (e.g., Wolfram Alpha, Wikipedia); 3) pack sampled tables with augmented knowledge into sequence prompts for LLMs reasoning while balancing the token allocation trade-off. We show that TAP4LLM allows for different components as plug-ins, enhancing LLMs' understanding of structured data in diverse tabular tasks.
Evaluating and Enhancing Structural Understanding Capabilities of Large Language Models on Tables via Input Designs
May 22, 2023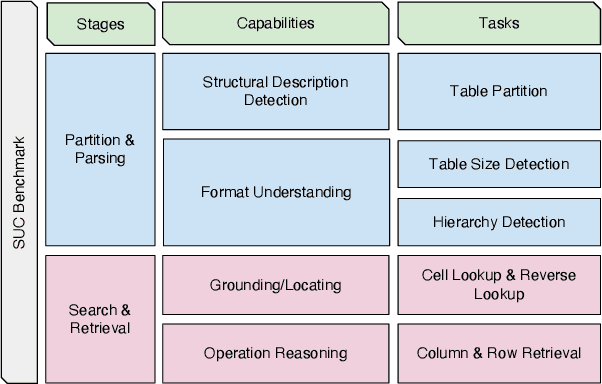
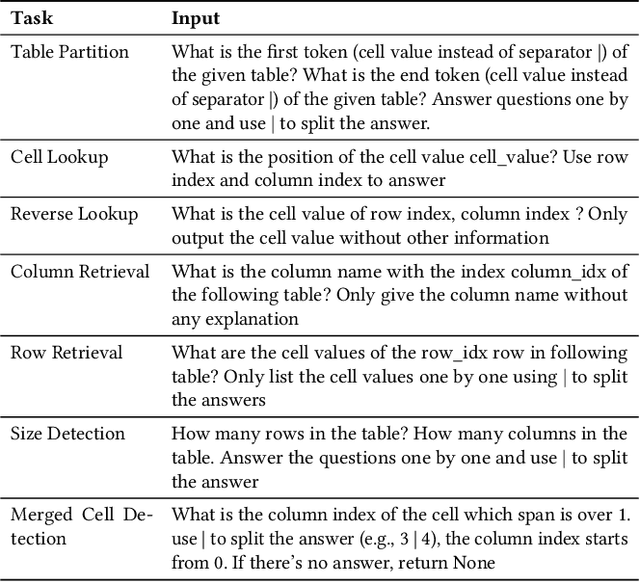
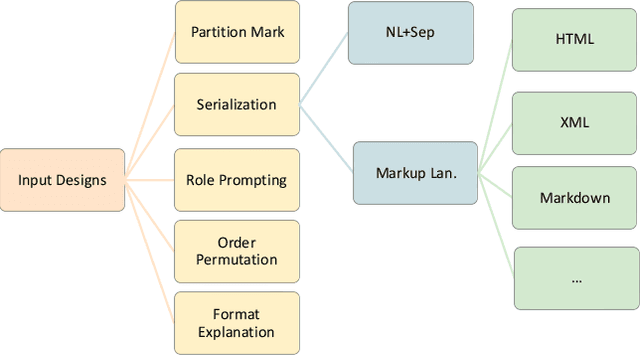

Large language models (LLMs) are becoming attractive as few-shot reasoners to solve NL-related tasks. However, there is still much to be learned about how well LLMs understand structured data, such as tables. While it is true that tables can be used as inputs to LLMs with serialization, there lack comprehensive studies examining whether LLMs can truly comprehend such data. In this paper we try to understand this by designing a benchmark to evaluate structural understanding capabilities (SUC) of LLMs. The benchmark we create includes seven tasks, each with their own unique challenges, e.g,, cell lookup, row retrieval and size detection. We run a series of evaluations on GPT-3 family models (e.g., text-davinci-003). We discover that the performance varied depending on a number of input choices, including table input format, content order, role prompting and partition marks. Drawing from the insights gained through the benchmark evaluations, we then propose self-augmentation for effective structural prompting, e.g., critical value / range identification using LLMs' internal knowledge. When combined with carefully chosen input choices, these structural prompting methods lead to promising improvements in LLM performance on a variety of tabular tasks, e.g., TabFact($\uparrow2.31\%$), HybridQA($\uparrow2.13\%$), SQA($\uparrow2.72\%$), Feverous($\uparrow0.84\%$), and ToTTo($\uparrow5.68\%$). We believe our benchmark and proposed prompting methods can serve as a simple yet generic selection for future research. The code and data are released in https://anonymous.4open.science/r/StructuredLLM-76F3.