 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Knowledge Graphs Make Large Language Models More Trustworthy? An Empirical Study over Open-ended Question Answering
Paper and Code
Oct 10, 2024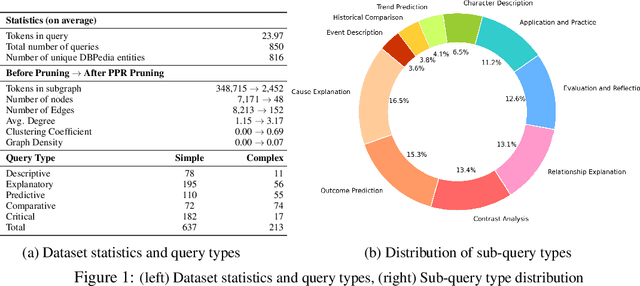
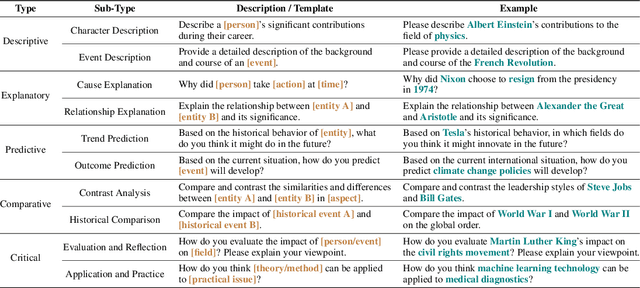
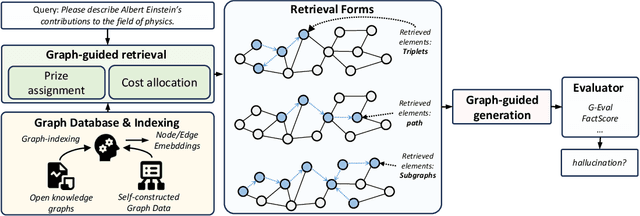
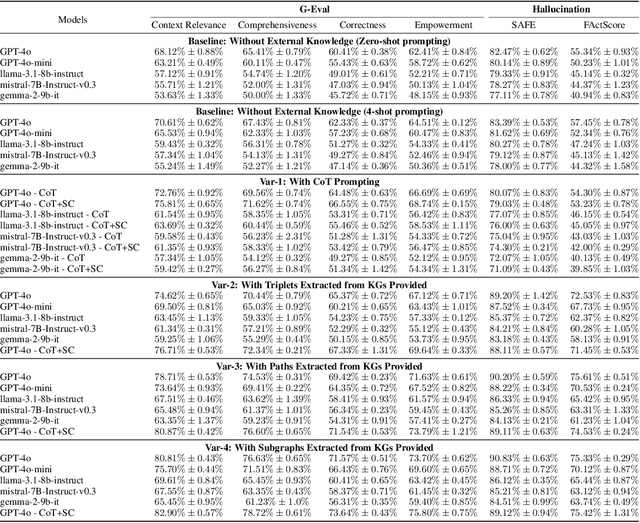
Recent works integrating Knowledge Graphs (KGs) have led to promising improvements in enhancing reasoning accuracy of Large Language Models (LLMs). However, current benchmarks mainly focus on closed tasks, leaving a gap in the assessment of more complex, real-world scenarios. This gap has also obscured the evaluation of KGs' potential to mitigate the problem of hallucination in LLMs. To fill the gap, we introduce OKGQA, a new benchmark specifically designed to assess LLMs enhanced with KGs under open-ended, real-world question answering scenarios. OKGQA is designed to closely reflect the complexities of practical applications using questions from different types, and incorporates specific metrics to measure both the reduction in hallucinations and the enhancement in reasoning capabilities. To consider the scenario in which KGs may have varying levels of mistakes, we further propose another experiment setting OKGQA-P to assess model performance when the semantics and structure of KGs are deliberately perturbed and contaminated. OKGQA aims to (1) explore whether KGs can make LLMs more trustworthy in an open-ended setting, and (2) conduct a comparative analysis to shed light on methods and future directions for leveraging KGs to reduce LLMs' hallucination. We believe that this study can facilitate a more complete performance comparison and encourage continuous improvement in integrating KGs with LLMs.