 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason via Mixture-of-Thought for Logical Reasoning
May 21, 2025Human beings naturally utilize multiple reasoning modalities to learn and solve logical problems, i.e., different representational formats such as natural language, code, and symbolic logic. In contrast, most existing LLM-based approaches operate with a single reasoning modality during training, typically natural language. Although some methods explored modality selection or augmentation at inference time, the training process remains modality-blind, limiting synergy among modalities. To fill in this gap, we propose Mixture-of-Thought (MoT), a framework that enables LLMs to reason across three complementary modalities: natural language, code, and a newly introduced symbolic modality, truth-table, which systematically enumerates logical cases and partially mitigates key failure modes in natural language reasoning. MoT adopts a two-phase design: (1) self-evolving MoT training, which jointly learns from filtered, self-generated rationales across modalities; and (2) MoT inference, which fully leverages the synergy of three modalities to produce better predictions. Experiments on logical reasoning benchmarks including FOLIO and ProofWriter demonstrate that our MoT framework consistently and significantly outperforms strong LLM baselines with single-modality chain-of-thought approaches, achieving up to +11.7pp average accuracy gain. Further analyses show that our MoT framework benefits both training and inference stages; that it is particularly effective on harder logical reasoning problems; and that different modalities contribute complementary strengths, with truth-table reasoning helping to overcome key bottlenecks in natural language inference.
Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models
May 16, 2025
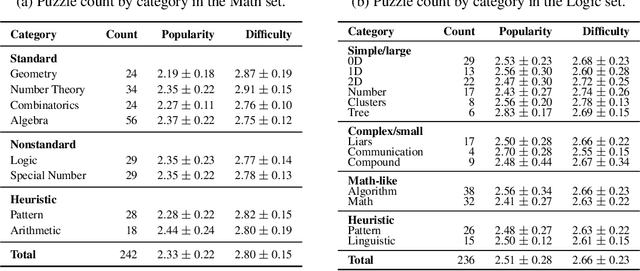

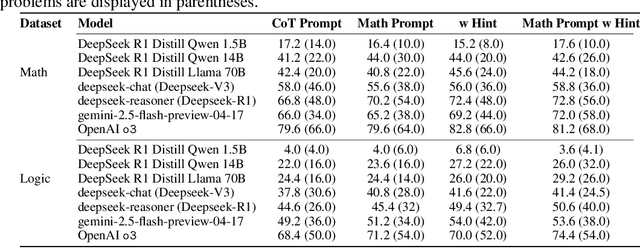
Accuracy remains a standard metric for evaluating AI systems, but it offers limited insight into how models arrive at their solutions. In this work, we introduce a benchmark based on brainteasers written in long narrative form to probe more deeply into the types of reasoning strategies that models use. Brainteasers are well-suited for this goal because they can be solved with multiple approaches, such as a few-step solution that uses a creative insight or a longer solution that uses more brute force. We investigate large language models (LLMs) across multiple layers of reasoning, focusing not only on correctness but also on the quality and creativity of their solutions. We investigate many aspects of the reasoning process: (1) semantic parsing of the brainteasers into precise mathematical competition style formats; (2) generating solutions from these mathematical forms; (3) self-correcting solutions based on gold solutions; (4) producing step-by-step sketches of solutions; and (5) making use of hints. We find that LLMs are in many cases able to find creative, insightful solutions to brainteasers, suggesting that they capture some of the capacities needed to solve novel problems in creative ways. Nonetheless, there also remain situations where they rely on brute force despite the availability of more efficient, creative solutions, highlighting a potential direction for improvement in the reasoning abilities of LLMs.
Towards Artificial Intelligence Research Assistant for Expert-Involved Learning
May 03, 2025Large Language Models (LLMs) and Large Multi-Modal Models (LMMs) have emerged as transformative tools in scientific research, yet their reliability and specific contributions to biomedical applications remain insufficiently characterized. In this study, we present \textbf{AR}tificial \textbf{I}ntelligence research assistant for \textbf{E}xpert-involved \textbf{L}earning (ARIEL), a multimodal dataset designed to benchmark and enhance two critical capabilities of LLMs and LMMs in biomedical research: summarizing extensive scientific texts and interpreting complex biomedical figures. To facilitate rigorous assessment, we create two open-source sets comprising biomedical articles and figures with designed questions. We systematically benchmark both open- and closed-source foundation models, incorporating expert-driven human evaluations conducted by doctoral-level experts. Furthermore, we improve model performance through targeted prompt engineering and fine-tuning strategies for summarizing research papers, and apply test-time computational scaling to enhance the reasoning capabilities of LMMs, achieving superior accuracy compared to human-expert corrections. We also explore the potential of using LMM Agents to generate scientific hypotheses from diverse multimodal inputs. Overall, our results delineate clear strengths and highlight significant limitations of current foundation models, providing actionable insights and guiding future advancements in deploying large-scale language and multi-modal models within biomedical research.
Meta-Reasoner: Dynamic Guidance for Optimized Inference-time Reasoning in Large Language Models
Feb 27, 2025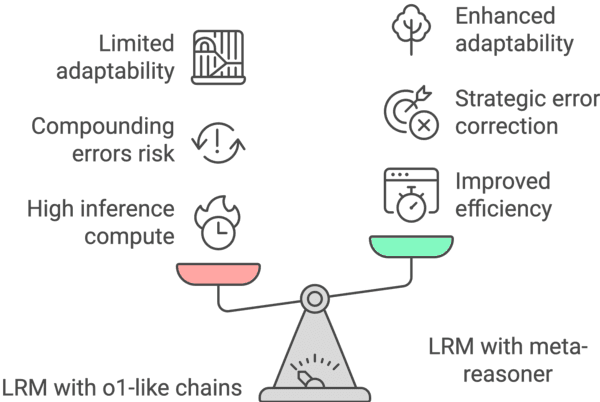
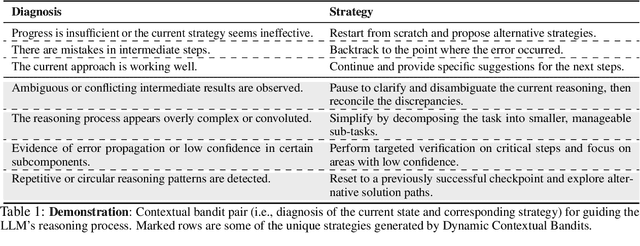
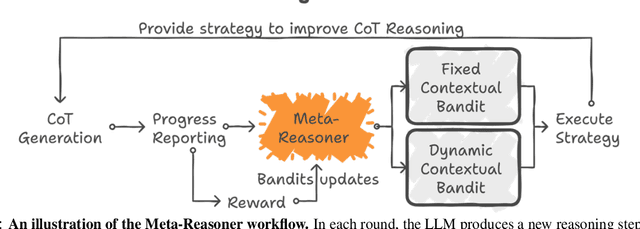
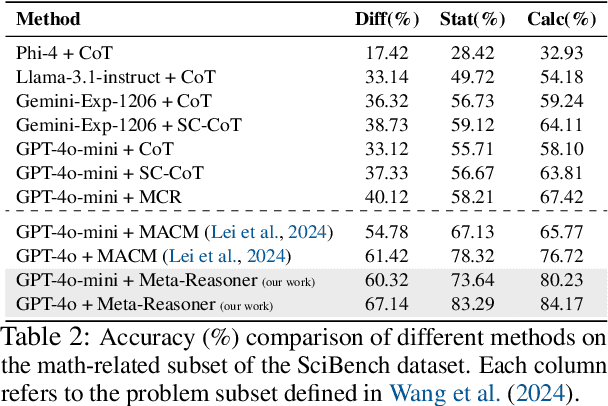
Large Language Models (LLMs) increasingly rely on prolonged reasoning chains to solve complex tasks. However, this trial-and-error approach often leads to high computational overhead and error propagation, where early mistakes can derail subsequent steps. To address these issues, we introduce Meta-Reasoner, a framework that dynamically optimizes inference-time reasoning by enabling LLMs to "think about how to think." Drawing inspiration from human meta-cognition and dual-process theory, Meta-Reasoner operates as a strategic advisor, decoupling high-level guidance from step-by-step generation. It employs "contextual multi-armed bandits" to iteratively evaluate reasoning progress, and select optimal strategies (e.g., backtrack, clarify ambiguity, restart from scratch, or propose alternative approaches), and reallocates computational resources toward the most promising paths. Our evaluations on mathematical reasoning and puzzles highlight the potential of dynamic reasoning chains to overcome inherent challenges in the LLM reasoning process and also show promise in broader applications, offering a scalable and adaptable solution for reasoning-intensive tasks.
ATEB: Evaluating and Improving Advanced NLP Tasks for Text Embedding Models
Feb 24, 2025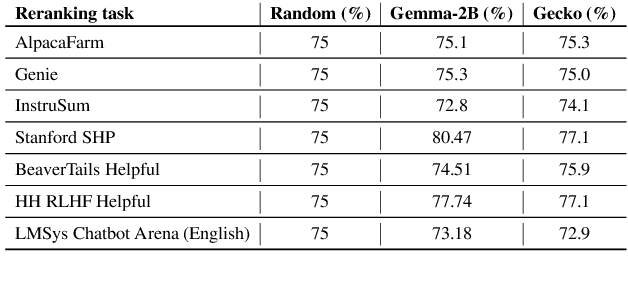
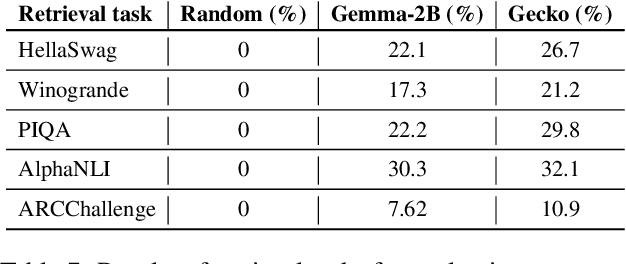
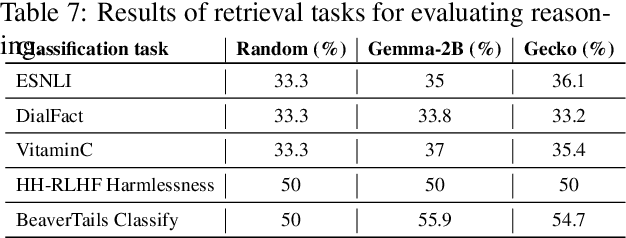

Traditional text embedding benchmarks primarily evaluate embedding models' capabilities to capture semantic similarity. However, more advanced NLP tasks require a deeper understanding of text, such as safety and factuality. These tasks demand an ability to comprehend and process complex information, often involving the handling of sensitive content, or the verification of factual statements against reliable sources. We introduce a new benchmark designed to assess and highlight the limitations of embedding models trained on existing information retrieval data mixtures on advanced capabilities, which include factuality, safety, instruction following, reasoning and document-level understanding. This benchmark includes a diverse set of tasks that simulate real-world scenarios where these capabilities are critical and leads to identification of the gaps of the currently advanced embedding models. Furthermore, we propose a novel method that reformulates these various tasks as retrieval tasks. By framing tasks like safety or factuality classification as retrieval problems, we leverage the strengths of retrieval models in capturing semantic relationships while also pushing them to develop a deeper understanding of context and content. Using this approach with single-task fine-tuning, we achieved performance gains of 8\% on factuality classification and 13\% on safety classification. Our code and data will be publicly available.
P-FOLIO: Evaluating and Improving Logical Reasoning with Abundant Human-Written Reasoning Chains
Oct 11, 2024



Existing methods on understanding the capabilities of LLMs in logical reasoning rely on binary entailment classification or synthetically derived rationales, which are not sufficient for proper investigation of model's capabilities. We present P-FOLIO, a human-annotated dataset consisting of diverse and complex reasoning chains for a set of realistic logical reasoning stories also written by humans. P-FOLIO is collected with an annotation protocol that facilitates humans to annotate well-structured natural language proofs for first-order logic reasoning problems in a step-by-step manner. The number of reasoning steps in P-FOLIO span from 0 to 20. We further use P-FOLIO to evaluate and improve large-language-model (LLM) reasoning capabilities. We evaluate LLM reasoning capabilities at a fine granularity via single-step inference rule classification, with more diverse inference rules of more diverse and higher levels of complexities than previous works. Given that a single model-generated reasoning chain could take a completely different path than the human-annotated one, we sample multiple reasoning chains from a model and use pass@k metrics for evaluating the quality of model-generated reasoning chains. We show that human-written reasoning chains significantly boost the logical reasoning capabilities of LLMs via many-shot prompting and fine-tuning. Furthermore, fine-tuning Llama3-7B on P-FOLIO improves the model performance by 10% or more on three other out-of-domain logical reasoning datasets. We also conduct detailed analysis to show where most powerful LLMs fall short in reasoning. We will release the dataset and code publicly.
GraphIC: A Graph-Based In-Context Example Retrieval Model for Multi-Step Reasoning
Oct 03, 2024
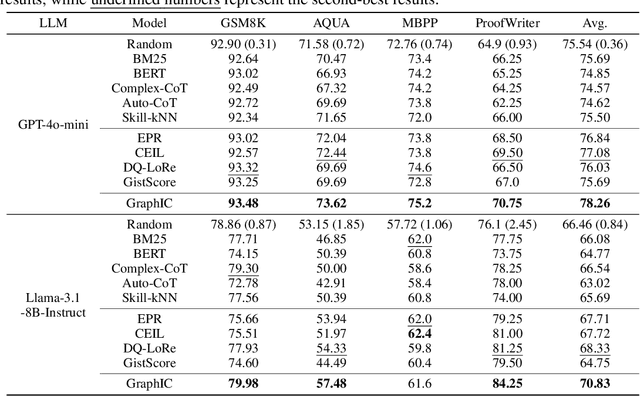
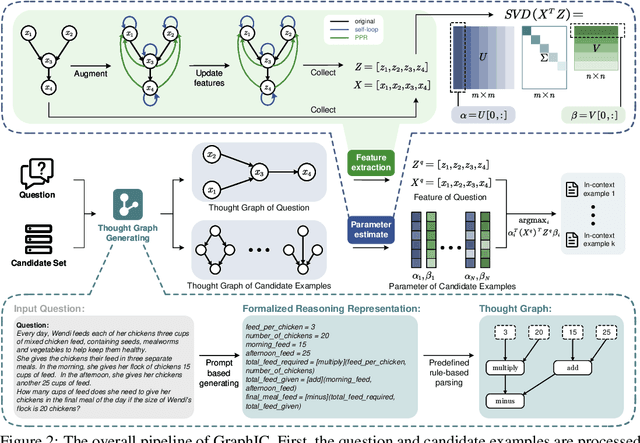

In-context learning (ICL) enables large language models (LLMs) to generalize to new tasks by incorporating a few in-context examples (ICEs) directly in the input, without updating parameters. However, the effectiveness of ICL heavily relies on the selection of ICEs, and conventional text-based embedding methods are often inadequate for tasks that require multi-step reasoning, such as mathematical and logical problem solving. This is due to the bias introduced by shallow semantic similarities that fail to capture the deeper reasoning structures required for these tasks. We present GraphIC, a novel approach that leverages graph-based representations of reasoning processes, coupled with Bayesian Networks (BNs) to select ICEs. Graph structures inherently filter out shallow semantics while preserving the core reasoning structure. Importantly, BNs capture the dependency of a node's attributes on its parent nodes, closely mirroring the hierarchical nature of human cognition-where each thought is shaped by preceding ones. This makes BNs particularly well-suited for multi-step reasoning tasks, aligning the process more closely with human-like reasoning. Extensive experiments across three types of reasoning tasks (mathematical reasoning, code generation, and logical reasoning) demonstrate that GraphIC outperforms both training-free and training-based models in selecting ICEs, excelling in terms of both effectiveness and efficiency. We show that GraphIC enhances ICL's performance and interoperability, significantly advancing ICE selection for multi-step reasoning tasks.
MetaMath: Integrating Natural Language and Code for Enhanced Mathematical Reasoning in Large Language Models
Sep 28, 2024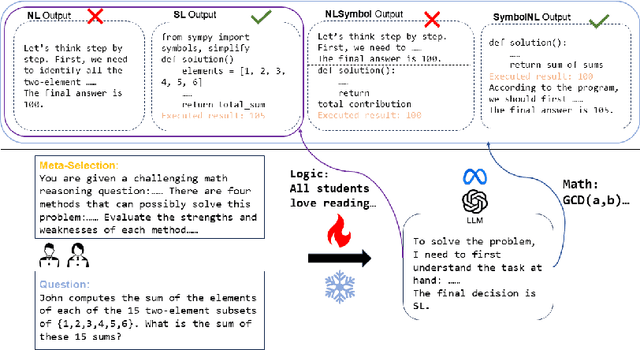


Large Language Models (LLMs) are commonly used to generate solutions for mathematical reasoning problems in the following formats: natural language, code, or a combination of both. In this paper, we explore fundamental questions related to solving mathematical reasoning problems using natural language and code with state-of-the-art LLMs, including GPT-4o-mini and LLama-3.1-8b-Turbo. Our findings show that LLMs are better at reasoning in natural language compared to code. Additionally, although natural language and code serve as complementary forms of reasoning, they can affect each other in a negative way in certain scenarios. These insights motivate our development of a new prompting method, MetaMath, which leverages an LLM to dynamically select the most appropriate reasoning form, resulting in improved performance over comparable baselines with GPT-4o-mini.
Optimizing Language Model's Reasoning Abilities with Weak Supervision
May 07, 2024



While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present \textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of \textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on \texttt{Anonymity Link}.
Benchmarking Generation and Evaluation Capabilities of Large Language Models for Instruction Controllable Summarization
Nov 15, 2023While large language models (LLMs) already achieve strong performance on standard generic summarization benchmarks, their performance on more complex summarization task settings is less studied. Therefore, we benchmark LLMs on instruction controllable text summarization, where the model input consists of both a source article and a natural language requirement for the desired summary characteristics. To this end, we curate an evaluation-only dataset for this task setting and conduct human evaluation on 5 LLM-based summarization systems. We then benchmark LLM-based automatic evaluation for this task with 4 different evaluation protocols and 11 LLMs, resulting in 40 evaluation methods in total. Our study reveals that instruction controllable text summarization remains a challenging task for LLMs, since (1) all LLMs evaluated still make factual and other types of errors in their summaries; (2) all LLM-based evaluation methods cannot achieve a strong alignment with human annotators when judging the quality of candidate summaries; (3) different LLMs show large performance gaps in summary generation and evaluation. We make our collected benchmark, InstruSum, publicly available to facilitate future research in this direction.