 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Mitigating Overrefusal in LLMs from an Unveiling Perspective of Safety Decision Boundary
May 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet they often refuse to answer legitimate queries-a phenomenon known as overrefusal. Overrefusal typically stems from over-conservative safety alignment, causing models to treat many reasonable prompts as potentially risky. To systematically understand this issue, we probe and leverage the models'safety decision boundaries to analyze and mitigate overrefusal. Our findings reveal that overrefusal is closely tied to misalignment at these boundary regions, where models struggle to distinguish subtle differences between benign and harmful content. Building on these insights, we present RASS, an automated framework for prompt generation and selection that strategically targets overrefusal prompts near the safety boundary. By harnessing steering vectors in the representation space, RASS efficiently identifies and curates boundary-aligned prompts, enabling more effective and targeted mitigation of overrefusal. This approach not only provides a more precise and interpretable view of model safety decisions but also seamlessly extends to multilingual scenarios.We have explored the safety decision boundaries of various LLMs and construct the MORBench evaluation set to facilitate robust assessment of model safety and helpfulness across multiple languages. Code and datasets will be released at https://anonymous.4open.science/r/RASS-80D3.
REWARD CONSISTENCY: Improving Multi-Objective Alignment from a Data-Centric Perspective
Apr 15, 2025
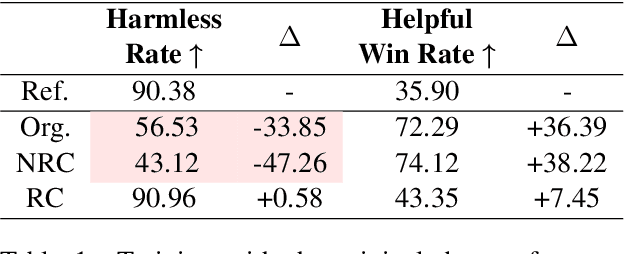


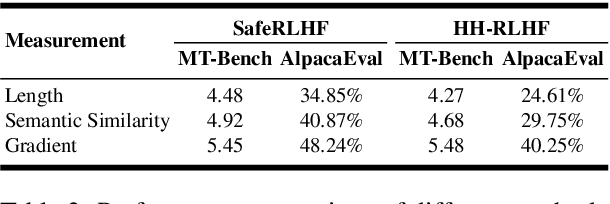
Multi-objective preference alignment in language models often encounters a challenging trade-off: optimizing for one human preference (e.g., helpfulness) frequently compromises others (e.g., harmlessness) due to the inherent conflicts between competing objectives. While prior work mainly focuses on algorithmic solutions, we explore a novel data-driven approach to uncover the types of data that can effectively mitigate these conflicts. Specifically, we propose the concept of Reward Consistency (RC), which identifies samples that align with multiple preference objectives, thereby reducing conflicts during training. Through gradient-based analysis, we demonstrate that RC-compliant samples inherently constrain performance degradation during multi-objective optimization. Building on these insights, we further develop Reward Consistency Sampling, a framework that automatically constructs preference datasets that effectively mitigate conflicts during multi-objective alignment. Our generated data achieves an average improvement of 13.37% in both the harmless rate and helpfulness win rate when optimizing harmlessness and helpfulness, and can consistently resolve conflicts in varying multi-objective scenarios.
BPO: Towards Balanced Preference Optimization between Knowledge Breadth and Depth in Alignment
Nov 16, 2024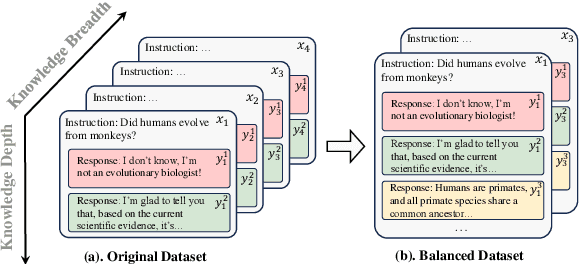
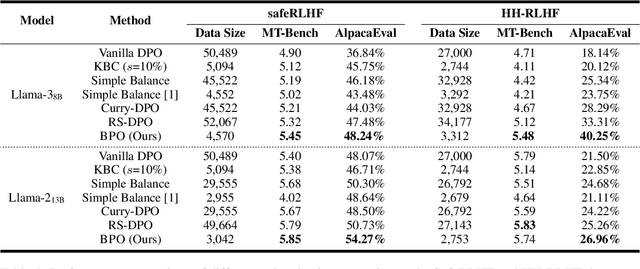
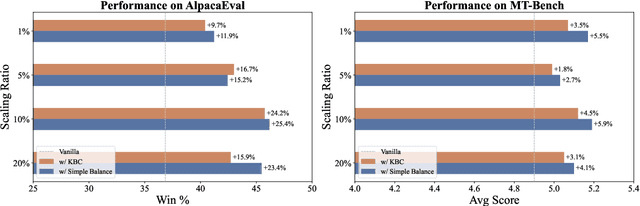
Reinforcement Learning with Human Feedback (RLHF) is the key to the success of large language models (LLMs) in recent years. In this work, we first introduce the concepts of knowledge breadth and knowledge depth, which measure the comprehensiveness and depth of an LLM or knowledge source respectively. We reveal that the imbalance in the number of prompts and responses can lead to a potential disparity in breadth and depth learning within alignment tuning datasets by showing that even a simple uniform method for balancing the number of instructions and responses can lead to significant improvements. Building on this, we further propose Balanced Preference Optimization (BPO), designed to dynamically augment the knowledge depth of each sample. BPO is motivated by the observation that the usefulness of knowledge varies across samples, necessitating tailored learning of knowledge depth. To achieve this, we introduce gradient-based clustering, estimating the knowledge informativeness and usefulness of each augmented sample based on the model's optimization direction. Our experimental results across various benchmarks demonstrate that BPO outperforms other baseline methods in alignment tuning while maintaining training efficiency. Furthermore, we conduct a detailed analysis of each component of BPO, providing guidelines for future research in preference data optimization.
Optimizing Language Model's Reasoning Abilities with Weak Supervision
May 07, 2024



While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present \textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of \textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on \texttt{Anonymity Link}.
Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost for Reasoning
Mar 29, 2024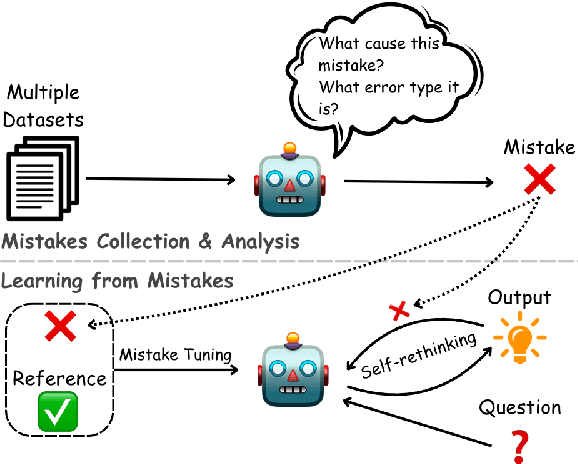

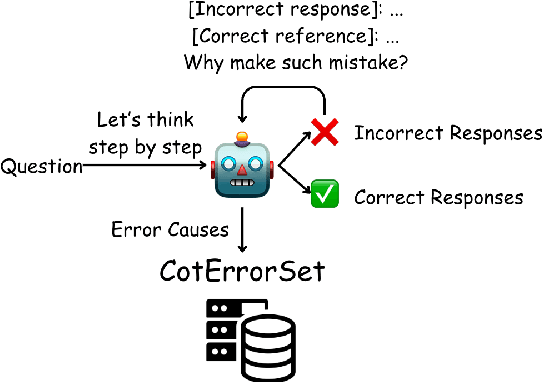

Recent works have shown the benefits to LLMs from fine-tuning golden-standard Chain-of-Thought (CoT) rationales or using them as correct examples in few-shot prompting. While humans can indeed imitate correct examples, learning from our mistakes is another vital aspect of human cognition. Hence, a question naturally arises: \textit{can LLMs learn and benefit from their mistakes, especially for their reasoning? } This study investigates this problem from both the prompting and model-tuning perspectives. We begin by introducing \textsc{CoTErrorSet}, a new benchmark with 609,432 questions, each designed with both correct and error references, and demonstrating the types and reasons for making such mistakes. To explore the effectiveness of those mistakes, we design two methods: (1) \textbf{Self-rethinking} prompting guides LLMs to rethink whether they have made similar previous mistakes; and (2) \textbf{Mistake tuning} involves finetuning models in both correct and incorrect reasoning domains, rather than only tuning models to learn ground truth in traditional methodology. We conduct a series of experiments to prove LLMs can obtain benefits from mistakes in both directions. Our two methods offer potentially cost-effective strategies by leveraging errors to enhance reasoning capabilities, which costs significantly less than creating meticulously hand-crafted golden references. We ultimately make a thorough analysis of the reasons behind LLMs' errors, which provides directions that future research needs to overcome. \textsc{CoTErrorSet} will be published soon on \texttt{Anonymity Link}.
ToxicChat: Unveiling Hidden Challenges of Toxicity Detection in Real-World User-AI Conversation
Oct 26, 2023Despite remarkable advances that large language models have achieved in chatbots, maintaining a non-toxic user-AI interactive environment has become increasingly critical nowadays. However, previous efforts in toxicity detection have been mostly based on benchmarks derived from social media content, leaving the unique challenges inherent to real-world user-AI interactions insufficiently explored. In this work, we introduce ToxicChat, a novel benchmark based on real user queries from an open-source chatbot. This benchmark contains the rich, nuanced phenomena that can be tricky for current toxicity detection models to identify, revealing a significant domain difference compared to social media content. Our systematic evaluation of models trained on existing toxicity datasets has shown their shortcomings when applied to this unique domain of ToxicChat. Our work illuminates the potentially overlooked challenges of toxicity detection in real-world user-AI conversations. In the future, ToxicChat can be a valuable resource to drive further advancements toward building a safe and healthy environment for user-AI interactions.
Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking
Oct 18, 2023Chain-of-Thought(CoT) prompting and its variants explore equipping large language models (LLMs) with high-level reasoning abilities by emulating human-like linear cognition and logic. However, the human mind is complicated and mixed with both linear and nonlinear thinking. In this work, we propose \textbf{I}nferential \textbf{E}xclusion \textbf{P}rompting (IEP), a novel prompting that combines the principles of elimination and inference in order to guide LLMs to think non-linearly. IEP guides LLMs to plan and then utilize Natural Language Inference (NLI) to deduce each possible solution's entailment relation with context, commonsense, or facts, therefore yielding a broader perspective by thinking back for inferring. This forward planning and backward eliminating process allows IEP to better simulate the complex human thinking processes compared to other CoT-based methods, which only reflect linear cognitive processes. We conducted a series of empirical studies and have corroborated that IEP consistently outperforms CoT across various tasks. Additionally, we observe that integrating IEP and CoT further improves the LLMs' performance on certain tasks, highlighting the necessity of equipping LLMs with mixed logic processes. Moreover, to better evaluate comprehensive features inherent in human logic, we introduce \textbf{M}ental-\textbf{A}bility \textbf{R}easoning \textbf{B}enchmark (MARB). The benchmark comprises six novel subtasks with a total of 9,115 questions, among which 1,685 are developed with hand-crafted rationale references. We believe both \textsc{IEP} and \textsc{MARB} can serve as a promising direction for unveiling LLMs' logic and verbal reasoning abilities and drive further advancements. \textsc{MARB} will be available at ~\texttt{anonymity link} soon.
Pretrained Language Encoders are Natural Tagging Frameworks for Aspect Sentiment Triplet Extraction
Aug 20, 2022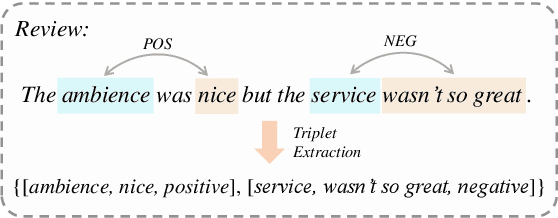
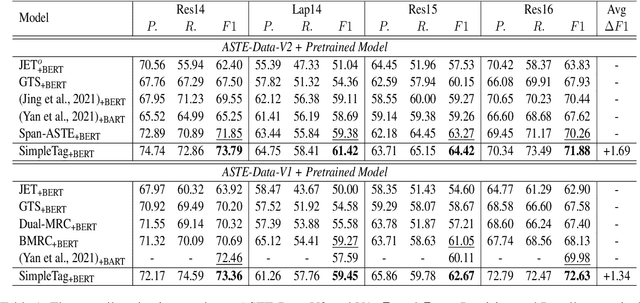
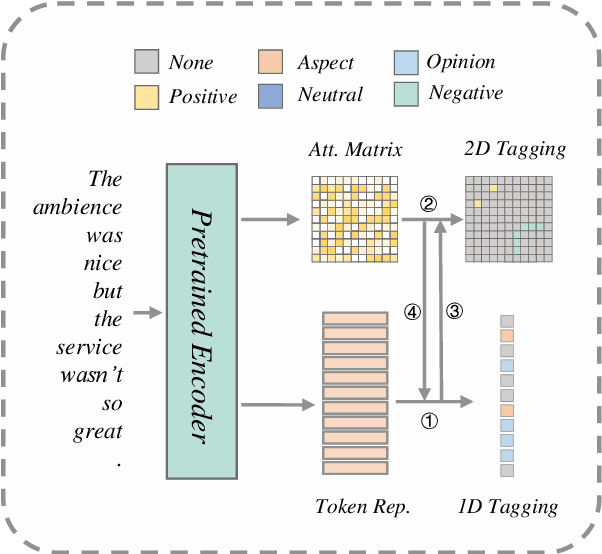
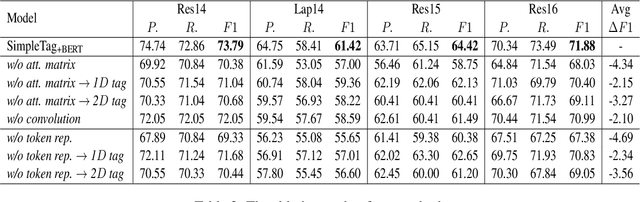
Aspect Sentiment Triplet Extraction (ASTE) aims to extract the spans of aspect, opinion, and their sentiment relations as sentiment triplets. Existing works usually formulate the span detection as a 1D token tagging problem, and model the sentiment recognition with a 2D tagging matrix of token pairs. Moreover, by leveraging the token representation of Pretrained Language Encoders (PLEs) like BERT, they can achieve better performance. However, they simply leverage PLEs as feature extractors to build their modules but never have a deep look at what specific knowledge does PLEs contain. In this paper, we argue that instead of further designing modules to capture the inductive bias of ASTE, PLEs themselves contain "enough" features for 1D and 2D tagging: (1) The token representation contains the contextualized meaning of token itself, so this level feature carries necessary information for 1D tagging. (2) The attention matrix of different PLE layers can further capture multi-level linguistic knowledge existing in token pairs, which benefits 2D tagging. (3) Furthermore, with simple transformations, these two features can also be easily converted to the 2D tagging matrix and 1D tagging sequence, respectively. That will further boost the tagging results. By doing so, PLEs can be natural tagging frameworks and achieve a new state of the art, which is verified by extensive experiments and deep analyses.