 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREWARD CONSISTENCY: Improving Multi-Objective Alignment from a Data-Centric Perspective
Paper and Code
Apr 15, 2025
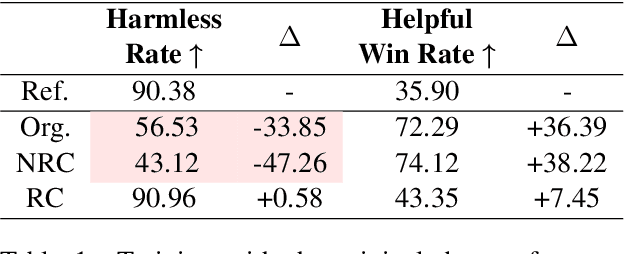


Multi-objective preference alignment in language models often encounters a challenging trade-off: optimizing for one human preference (e.g., helpfulness) frequently compromises others (e.g., harmlessness) due to the inherent conflicts between competing objectives. While prior work mainly focuses on algorithmic solutions, we explore a novel data-driven approach to uncover the types of data that can effectively mitigate these conflicts. Specifically, we propose the concept of Reward Consistency (RC), which identifies samples that align with multiple preference objectives, thereby reducing conflicts during training. Through gradient-based analysis, we demonstrate that RC-compliant samples inherently constrain performance degradation during multi-objective optimization. Building on these insights, we further develop Reward Consistency Sampling, a framework that automatically constructs preference datasets that effectively mitigate conflicts during multi-objective alignment. Our generated data achieves an average improvement of 13.37% in both the harmless rate and helpfulness win rate when optimizing harmlessness and helpfulness, and can consistently resolve conflicts in varying multi-objective scenarios.