 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evaluating the Integration of Reasoning and Action in LLM Agents with Database Question Answering
Nov 16, 2023



This study introduces a new long-form database question answering dataset designed to evaluate how Large Language Models (LLMs) interact with a SQL interpreter. The task necessitates LLMs to strategically generate multiple SQL queries to retrieve sufficient data from a database, to reason with the acquired context, and to synthesize them into a comprehensive analytical narrative. Our findings highlight that this task poses great challenges even for the state-of-the-art GPT-4 model. We propose and evaluate two interaction strategies, and provide a fine-grained analysis of the individual stages within the interaction. A key discovery is the identification of two primary bottlenecks hindering effective interaction: the capacity for planning and the ability to generate multiple SQL queries. To address the challenge of accurately assessing answer quality, we introduce a multi-agent evaluation framework that simulates the academic peer-review process, enhancing the precision and reliability of our evaluations. This framework allows for a more nuanced understanding of the strengths and limitations of current LLMs in complex retrieval and reasoning tasks.
QTSumm: A New Benchmark for Query-Focused Table Summarization
May 23, 2023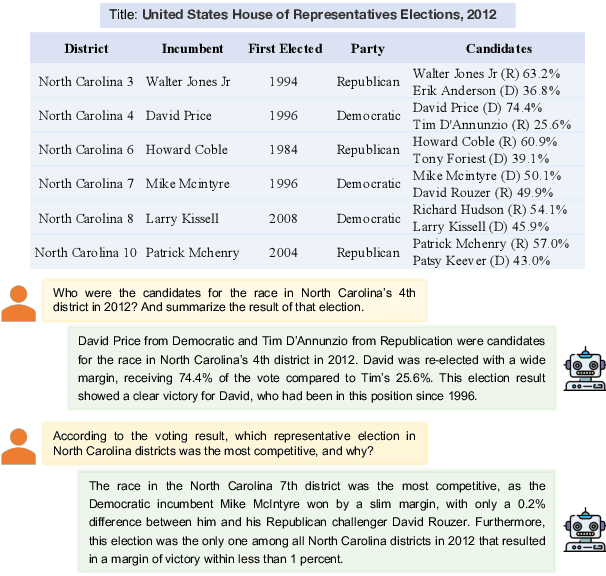
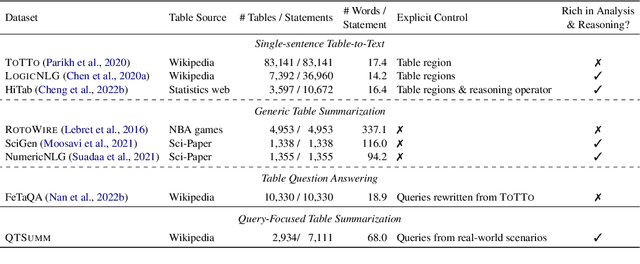

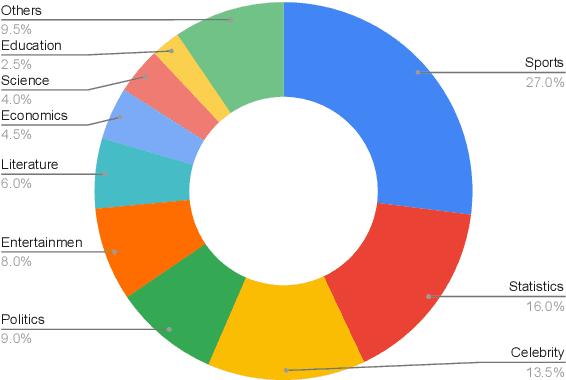
People primarily consult tables to conduct data analysis or answer specific questions. Text generation systems that can provide accurate table summaries tailored to users' information needs can facilitate more efficient access to relevant data insights. However, existing table-to-text generation studies primarily focus on converting tabular data into coherent statements, rather than addressing information-seeking purposes. In this paper, we define a new query-focused table summarization task, where text generation models have to perform human-like reasoning and analysis over the given table to generate a tailored summary, and we introduce a new benchmark named QTSumm for this task. QTSumm consists of 5,625 human-annotated query-summary pairs over 2,437 tables on diverse topics. Moreover, we investigate state-of-the-art models (i.e., text generation, table-to-text generation, and large language models) on the QTSumm dataset. Experimental results and manual analysis reveal that our benchmark presents significant challenges in table-to-text generation for future research.
Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
May 21, 2023In-context learning (ICL) has emerged as a new approach to various natural language processing tasks, utilizing large language models (LLMs) to make predictions based on context that has been supplemented with a few examples or task-specific instructions. In this paper, we aim to extend this method to question answering tasks that utilize structured knowledge sources, and improve Text-to-SQL systems by exploring various prompt design strategies for employing LLMs. We conduct a systematic investigation into different demonstration selection methods and optimal instruction formats for prompting LLMs in the Text-to-SQL task. Our approach involves leveraging the syntactic structure of an example's SQL query to retrieve demonstrations, and we demonstrate that pursuing both diversity and similarity in demonstration selection leads to enhanced performance. Furthermore, we show that LLMs benefit from database-related knowledge augmentations. Our most effective strategy outperforms the state-of-the-art system by 2.5 points (Execution Accuracy) and the best fine-tuned system by 5.1 points on the Spider dataset. These results highlight the effectiveness of our approach in adapting LLMs to the Text-to-SQL task, and we present an analysis of the factors contributing to the success of our strategy.
R2D2: Robust Data-to-Text with Replacement Detection
May 25, 2022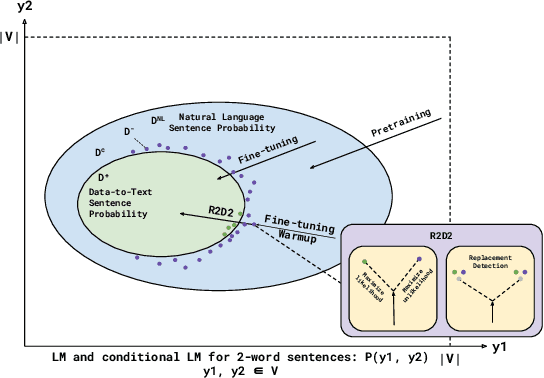

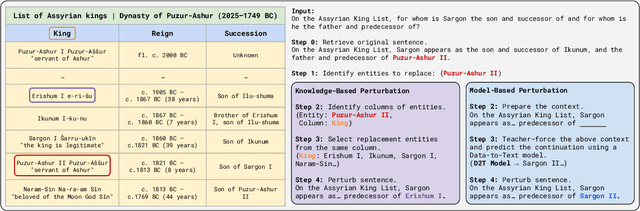
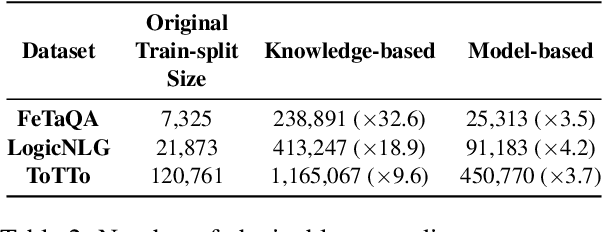
Unfaithful text generation is a common problem for text generation systems. In the case of Data-to-Text (D2T) systems, the factuality of the generated text is particularly crucial for any real-world applications. We introduce R2D2, a training framework that addresses unfaithful Data-to-Text generation by training a system both as a generator and a faithfulness discriminator with additional replacement detection and unlikelihood learning tasks. To facilitate such training, we propose two methods for sampling unfaithful sentences. We argue that the poor entity retrieval capability of D2T systems is one of the primary sources of unfaithfulness, so in addition to the existing metrics, we further propose NER-based metrics to evaluate the fidelity of D2T generations. Our experimental results show that R2D2 systems could effectively mitigate the unfaithful text generation, and they achieve new state-of-the-art results on FeTaQA, LogicNLG, and ToTTo, all with significant improvements.