 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiology as Language: Translating Respiration to Sleep EEG
Jan 31, 2026This paper introduces a novel cross-physiology translation task: synthesizing sleep electroencephalography (EEG) from respiration signals. To address the significant complexity gap between the two modalities, we propose a waveform-conditional generative framework that preserves fine-grained respiratory dynamics while constraining the EEG target space through discrete tokenization. Trained on over 28,000 individuals, our model achieves a 7% Mean Absolute Error in EEG spectrogram reconstruction. Beyond reconstruction, the synthesized EEG supports downstream tasks with performance comparable to ground truth EEG on age estimation (MAE 5.0 vs. 5.1 years), sex detection (AUROC 0.81 vs. 0.82), and sleep staging (Accuracy 0.84 vs. 0.88), significantly outperforming baselines trained directly on breathing. Finally, we demonstrate that the framework generalizes to contactless sensing by synthesizing EEG from wireless radio-frequency reflections, highlighting the feasibility of remote, non-contact neurological assessment during sleep.
Factorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
Exploring the Manifold of Neural Networks Using Diffusion Geometry
Nov 19, 2024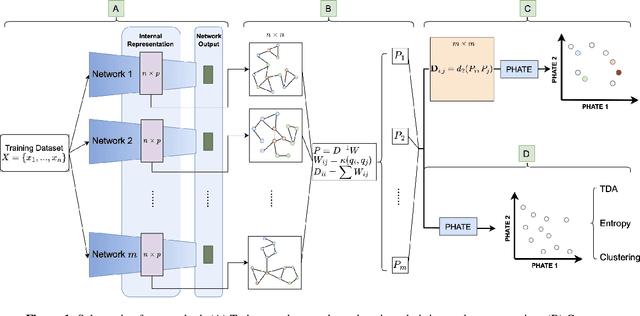

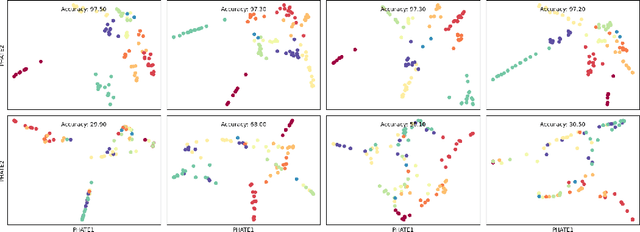
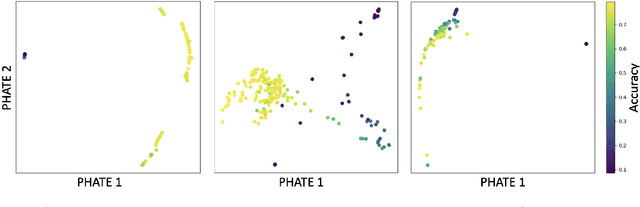
Drawing motivation from the manifold hypothesis, which posits that most high-dimensional data lies on or near low-dimensional manifolds, we apply manifold learning to the space of neural networks. We learn manifolds where datapoints are neural networks by introducing a distance between the hidden layer representations of the neural networks. These distances are then fed to the non-linear dimensionality reduction algorithm PHATE to create a manifold of neural networks. We characterize this manifold using features of the representation, including class separation, hierarchical cluster structure, spectral entropy, and topological structure. Our analysis reveals that high-performing networks cluster together in the manifold, displaying consistent embedding patterns across all these features. Finally, we demonstrate the utility of this approach for guiding hyperparameter optimization and neural architecture search by sampling from the manifold.
On Evaluating the Integration of Reasoning and Action in LLM Agents with Database Question Answering
Nov 16, 2023



This study introduces a new long-form database question answering dataset designed to evaluate how Large Language Models (LLMs) interact with a SQL interpreter. The task necessitates LLMs to strategically generate multiple SQL queries to retrieve sufficient data from a database, to reason with the acquired context, and to synthesize them into a comprehensive analytical narrative. Our findings highlight that this task poses great challenges even for the state-of-the-art GPT-4 model. We propose and evaluate two interaction strategies, and provide a fine-grained analysis of the individual stages within the interaction. A key discovery is the identification of two primary bottlenecks hindering effective interaction: the capacity for planning and the ability to generate multiple SQL queries. To address the challenge of accurately assessing answer quality, we introduce a multi-agent evaluation framework that simulates the academic peer-review process, enhancing the precision and reliability of our evaluations. This framework allows for a more nuanced understanding of the strengths and limitations of current LLMs in complex retrieval and reasoning tasks.
Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
May 21, 2023In-context learning (ICL) has emerged as a new approach to various natural language processing tasks, utilizing large language models (LLMs) to make predictions based on context that has been supplemented with a few examples or task-specific instructions. In this paper, we aim to extend this method to question answering tasks that utilize structured knowledge sources, and improve Text-to-SQL systems by exploring various prompt design strategies for employing LLMs. We conduct a systematic investigation into different demonstration selection methods and optimal instruction formats for prompting LLMs in the Text-to-SQL task. Our approach involves leveraging the syntactic structure of an example's SQL query to retrieve demonstrations, and we demonstrate that pursuing both diversity and similarity in demonstration selection leads to enhanced performance. Furthermore, we show that LLMs benefit from database-related knowledge augmentations. Our most effective strategy outperforms the state-of-the-art system by 2.5 points (Execution Accuracy) and the best fine-tuned system by 5.1 points on the Spider dataset. These results highlight the effectiveness of our approach in adapting LLMs to the Text-to-SQL task, and we present an analysis of the factors contributing to the success of our strategy.