 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Manifold of Neural Networks Using Diffusion Geometry
Paper and Code
Nov 19, 2024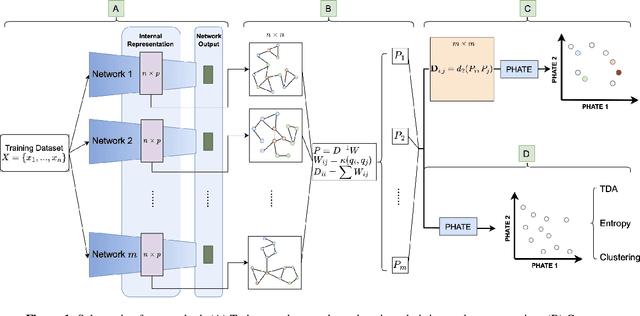

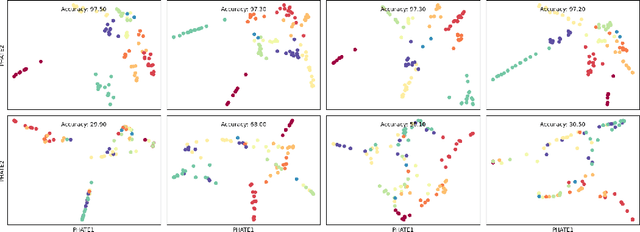
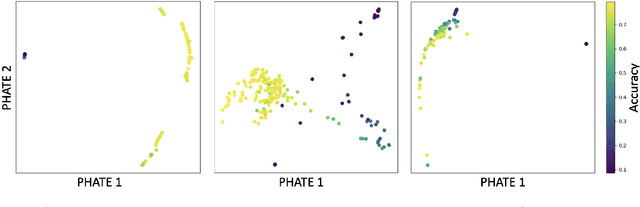
Drawing motivation from the manifold hypothesis, which posits that most high-dimensional data lies on or near low-dimensional manifolds, we apply manifold learning to the space of neural networks. We learn manifolds where datapoints are neural networks by introducing a distance between the hidden layer representations of the neural networks. These distances are then fed to the non-linear dimensionality reduction algorithm PHATE to create a manifold of neural networks. We characterize this manifold using features of the representation, including class separation, hierarchical cluster structure, spectral entropy, and topological structure. Our analysis reveals that high-performing networks cluster together in the manifold, displaying consistent embedding patterns across all these features. Finally, we demonstrate the utility of this approach for guiding hyperparameter optimization and neural architecture search by sampling from the manifold.