 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTESS 2: A Large-Scale Generalist Diffusion Language Model
Feb 19, 2025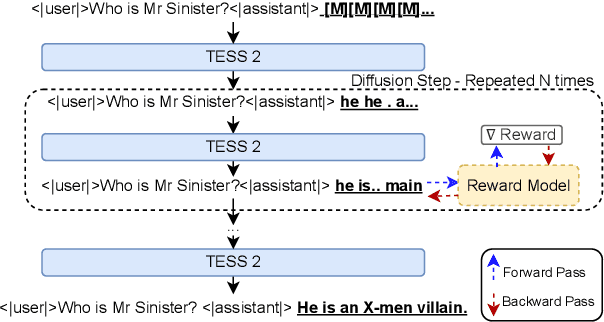
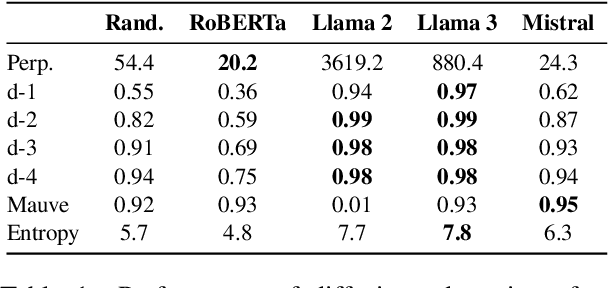
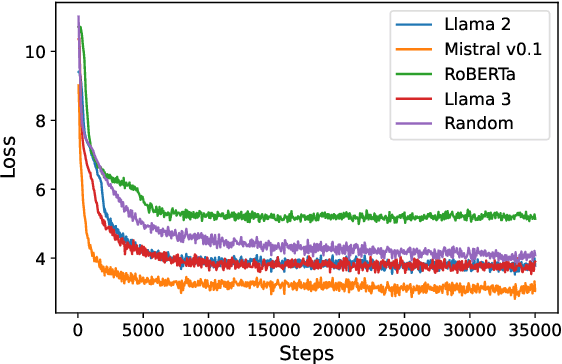
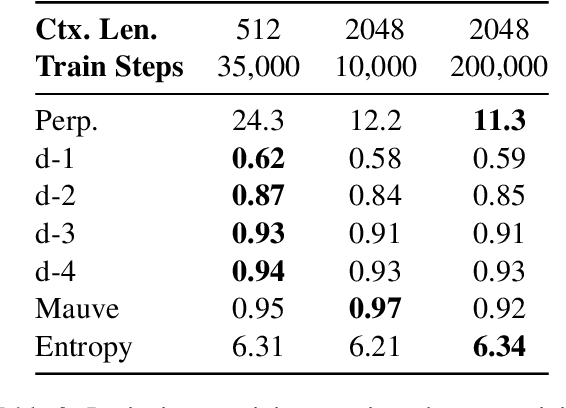
We introduce TESS 2, a general instruction-following diffusion language model that outperforms contemporary instruction-tuned diffusion models, as well as matches and sometimes exceeds strong autoregressive (AR) models. We train TESS 2 by first adapting a strong AR model via continued pretraining with the usual cross-entropy as diffusion loss, and then performing further instruction tuning. We find that adaptation training as well as the choice of the base model is crucial for training good instruction-following diffusion models. We further propose reward guidance, a novel and modular inference-time guidance procedure to align model outputs without needing to train the underlying model. Finally, we show that TESS 2 further improves with increased inference-time compute, highlighting the utility of diffusion LMs in having fine-grained controllability over the amount of compute used at inference time. Code and models are available at https://github.com/hamishivi/tess-2.
Mirror Diffusion Models
Aug 18, 2023Diffusion models have successfully been applied to generative tasks in various continuous domains. However, applying diffusion to discrete categorical data remains a non-trivial task. Moreover, generation in continuous domains often requires clipping in practice, which motivates the need for a theoretical framework for adapting diffusion to constrained domains. Inspired by the mirror Langevin algorithm for the constrained sampling problem, in this theoretical report we propose Mirror Diffusion Models (MDMs). We demonstrate MDMs in the context of simplex diffusion and propose natural extensions to popular domains such as image and text generation.
Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
May 21, 2023In-context learning (ICL) has emerged as a new approach to various natural language processing tasks, utilizing large language models (LLMs) to make predictions based on context that has been supplemented with a few examples or task-specific instructions. In this paper, we aim to extend this method to question answering tasks that utilize structured knowledge sources, and improve Text-to-SQL systems by exploring various prompt design strategies for employing LLMs. We conduct a systematic investigation into different demonstration selection methods and optimal instruction formats for prompting LLMs in the Text-to-SQL task. Our approach involves leveraging the syntactic structure of an example's SQL query to retrieve demonstrations, and we demonstrate that pursuing both diversity and similarity in demonstration selection leads to enhanced performance. Furthermore, we show that LLMs benefit from database-related knowledge augmentations. Our most effective strategy outperforms the state-of-the-art system by 2.5 points (Execution Accuracy) and the best fine-tuned system by 5.1 points on the Spider dataset. These results highlight the effectiveness of our approach in adapting LLMs to the Text-to-SQL task, and we present an analysis of the factors contributing to the success of our strategy.
TESS: Text-to-Text Self-Conditioned Simplex Diffusion
May 15, 2023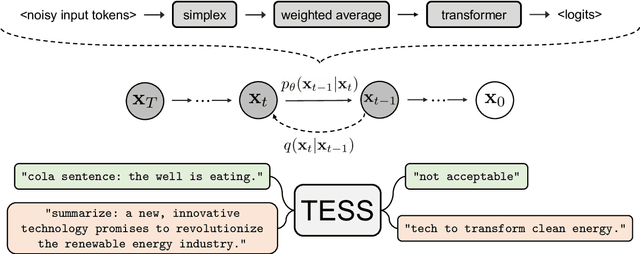
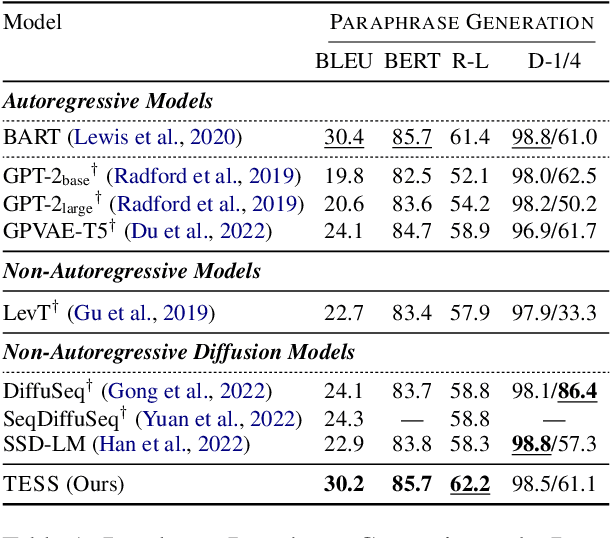

Diffusion models have emerged as a powerful paradigm for generation, obtaining strong performance in various domains with continuous-valued inputs. Despite the promises of fully non-autoregressive text generation, applying diffusion models to natural language remains challenging due to its discrete nature. In this work, we propose Text-to-text Self-conditioned Simplex Diffusion (TESS), a text diffusion model that is fully non-autoregressive, employs a new form of self-conditioning, and applies the diffusion process on the logit simplex space rather than the typical learned embedding space. Through extensive experiments on natural language understanding and generation tasks including summarization, text simplification, paraphrase generation, and question generation, we demonstrate that TESS outperforms state-of-the-art non-autoregressive models and is competitive with pretrained autoregressive sequence-to-sequence models.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
What Language Model to Train if You Have One Million GPU Hours?
Nov 08, 2022



The crystallization of modeling methods around the Transformer architecture has been a boon for practitioners. Simple, well-motivated architectural variations can transfer across tasks and scale, increasing the impact of modeling research. However, with the emergence of state-of-the-art 100B+ parameters models, large language models are increasingly expensive to accurately design and train. Notably, it can be difficult to evaluate how modeling decisions may impact emergent capabilities, given that these capabilities arise mainly from sheer scale alone. In the process of building BLOOM--the Big Science Large Open-science Open-access Multilingual language model--our goal is to identify an architecture and training setup that makes the best use of our 1,000,000 A100-GPU-hours budget. Specifically, we perform an ablation study at the billion-parameter scale comparing different modeling practices and their impact on zero-shot generalization. In addition, we study the impact of various popular pre-training corpora on zero-shot generalization. We also study the performance of a multilingual model and how it compares to the English-only one. Finally, we consider the scaling behaviour of Transformers to choose the target model size, shape, and training setup. All our models and code are open-sourced at https://huggingface.co/bigscience .
Surfer100: Generating Surveys From Web Resources on Wikipedia-style
Dec 13, 2021

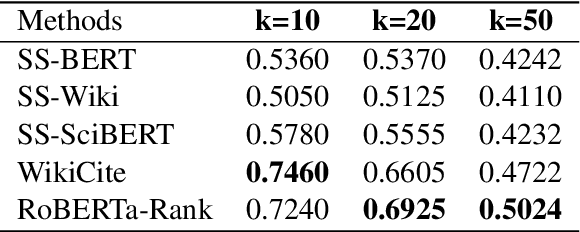
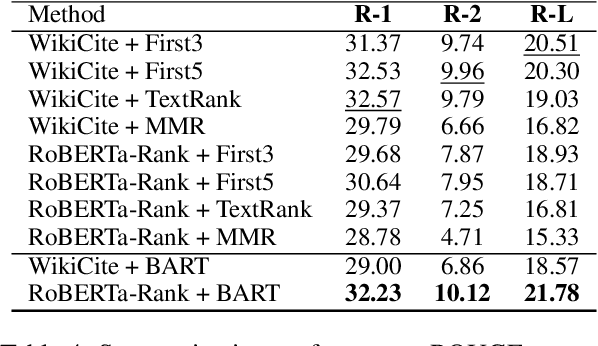
Fast-developing fields such as Artificial Intelligence (AI) often outpace the efforts of encyclopedic sources such as Wikipedia, which either do not completely cover recently-introduced topics or lack such content entirely. As a result, methods for automatically producing content are valuable tools to address this information overload. We show that recent advances in pretrained language modeling can be combined for a two-stage extractive and abstractive approach for Wikipedia lead paragraph generation. We extend this approach to generate longer Wikipedia-style summaries with sections and examine how such methods struggle in this application through detailed studies with 100 reference human-collected surveys. This is the first study on utilizing web resources for long Wikipedia-style summaries to the best of our knowledge.
EdiTTS: Score-based Editing for Controllable Text-to-Speech
Oct 06, 2021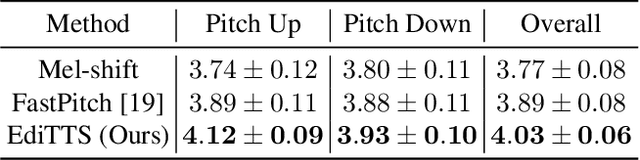
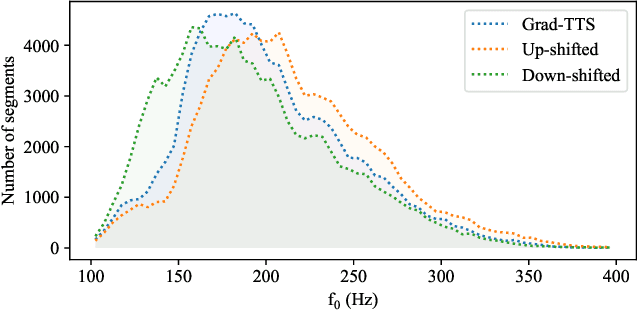
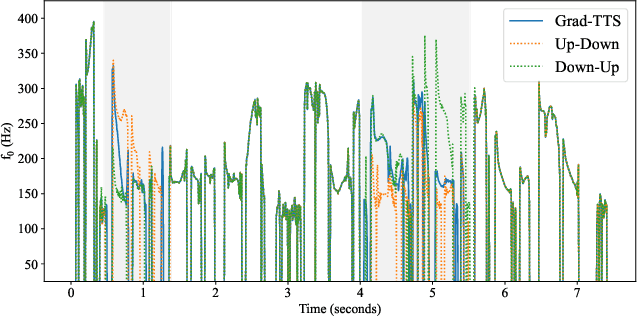
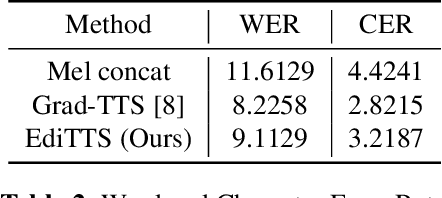
We present EdiTTS, an off-the-shelf speech editing methodology based on score-based generative modeling for text-to-speech synthesis. EdiTTS allows for targeted, granular editing of audio, both in terms of content and pitch, without the need for any additional training, task-specific optimization, or architectural modifications to the score-based model backbone. Specifically, we apply coarse yet deliberate perturbations in the Gaussian prior space to induce desired behavior from the diffusion model, while applying masks and softening kernels to ensure that iterative edits are applied only to the target region. Listening tests demonstrate that EdiTTS is capable of reliably generating natural-sounding audio that satisfies user-imposed requirements.