 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Benefits of Fine-Grained Loss Truncation: A Case Study on Factuality in Summarization
Mar 09, 2024
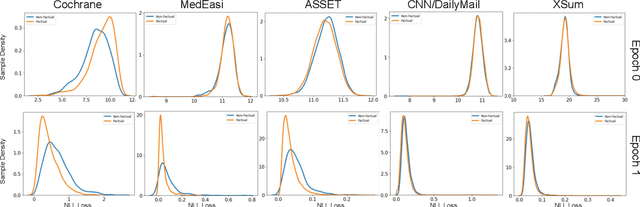


Text summarization and simplification are among the most widely used applications of AI. However, models developed for such tasks are often prone to hallucination, which can result from training on unaligned data. One efficient approach to address this issue is Loss Truncation (LT) (Kang and Hashimoto, 2020), an approach to modify the standard log loss to adaptively remove noisy examples during training. However, we find that LT alone yields a considerable number of hallucinated entities on various datasets. We study the behavior of the underlying losses between factual and non-factual examples, to understand and refine the performance of LT. We demonstrate that LT's performance is limited when the underlying assumption that noisy targets have higher NLL loss is not satisfied, and find that word-level NLL among entities provides better signal for distinguishing factuality. We then leverage this to propose a fine-grained NLL loss and fine-grained data cleaning strategies, and observe improvements in hallucination reduction across some datasets. Our work is available at https://https://github.com/yale-nlp/fine-grained-lt.
Medical Text Simplification: Optimizing for Readability with Unlikelihood Training and Reranked Beam Search Decoding
Oct 26, 2023Text simplification has emerged as an increasingly useful application of AI for bridging the communication gap in specialized fields such as medicine, where the lexicon is often dominated by technical jargon and complex constructs. Despite notable progress, methods in medical simplification sometimes result in the generated text having lower quality and diversity. In this work, we explore ways to further improve the readability of text simplification in the medical domain. We propose (1) a new unlikelihood loss that encourages generation of simpler terms and (2) a reranked beam search decoding method that optimizes for simplicity, which achieve better performance on readability metrics on three datasets. This study's findings offer promising avenues for improving text simplification in the medical field.
LoFT: Enhancing Faithfulness and Diversity for Table-to-Text Generation via Logic Form Control
Feb 06, 2023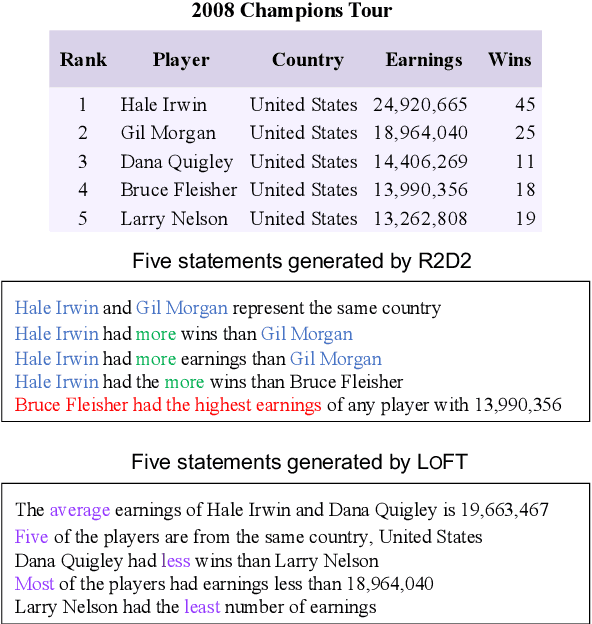
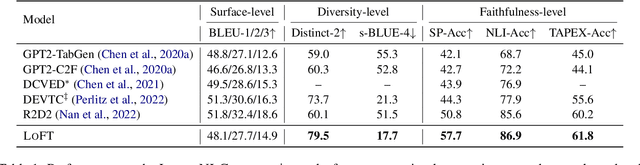
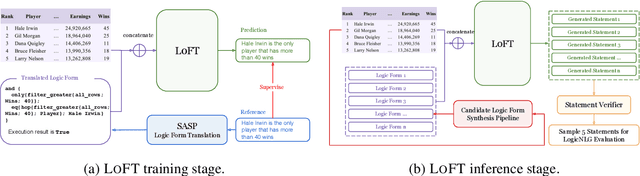
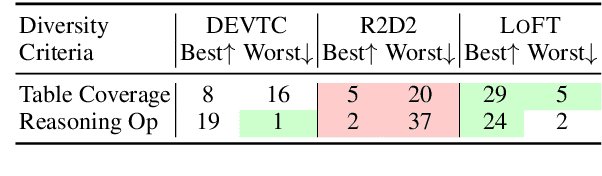
Logical Table-to-Text (LT2T) generation is tasked with generating logically faithful sentences from tables. There currently exists two challenges in the field: 1) Faithfulness: how to generate sentences that are factually correct given the table content; 2) Diversity: how to generate multiple sentences that offer different perspectives on the table. This work proposes LoFT, which utilizes logic forms as fact verifiers and content planners to control LT2T generation. Experimental results on the LogicNLG dataset demonstrate that LoFT is the first model that addresses unfaithfulness and lack of diversity issues simultaneously. Our code is publicly available at https://github.com/Yale-LILY/LoFT.
Look Ma, Only 400 Samples! Revisiting the Effectiveness of Automatic N-Gram Rule Generation for Spelling Normalization in Filipino
Oct 06, 2022
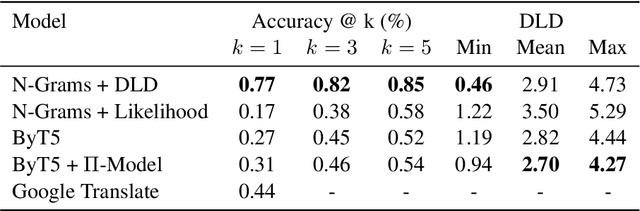
With 84.75 million Filipinos online, the ability for models to process online text is crucial for developing Filipino NLP applications. To this end, spelling correction is a crucial preprocessing step for downstream processing. However, the lack of data prevents the use of language models for this task. In this paper, we propose an N-Gram + Damerau Levenshtein distance model with automatic rule extraction. We train the model on 300 samples, and show that despite limited training data, it achieves good performance and outperforms other deep learning approaches in terms of accuracy and edit distance. Moreover, the model (1) requires little compute power, (2) trains in little time, thus allowing for retraining, and (3) is easily interpretable, allowing for direct troubleshooting, highlighting the success of traditional approaches over more complex deep learning models in settings where data is unavailable.
R2D2: Robust Data-to-Text with Replacement Detection
May 25, 2022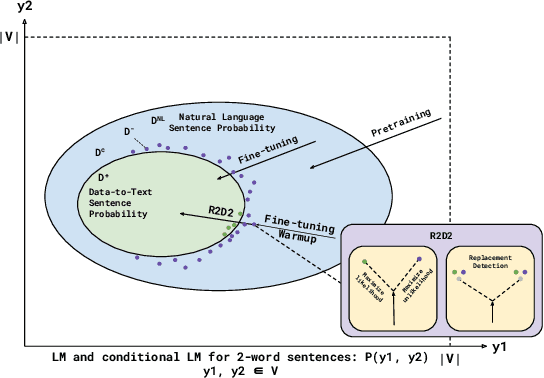

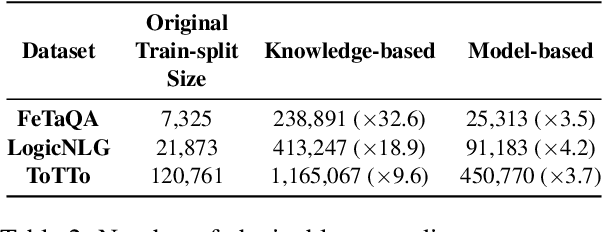
Unfaithful text generation is a common problem for text generation systems. In the case of Data-to-Text (D2T) systems, the factuality of the generated text is particularly crucial for any real-world applications. We introduce R2D2, a training framework that addresses unfaithful Data-to-Text generation by training a system both as a generator and a faithfulness discriminator with additional replacement detection and unlikelihood learning tasks. To facilitate such training, we propose two methods for sampling unfaithful sentences. We argue that the poor entity retrieval capability of D2T systems is one of the primary sources of unfaithfulness, so in addition to the existing metrics, we further propose NER-based metrics to evaluate the fidelity of D2T generations. Our experimental results show that R2D2 systems could effectively mitigate the unfaithful text generation, and they achieve new state-of-the-art results on FeTaQA, LogicNLG, and ToTTo, all with significant improvements.
An Adversarial Benchmark for Fake News Detection Models
Jan 03, 2022


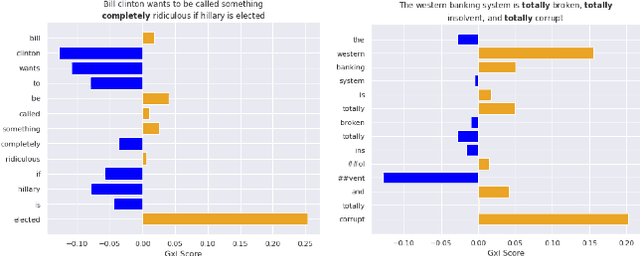
With the proliferation of online misinformation, fake news detection has gained importance in the artificial intelligence community. In this paper, we propose an adversarial benchmark that tests the ability of fake news detectors to reason about real-world facts. We formulate adversarial attacks that target three aspects of "understanding": compositional semantics, lexical relations, and sensitivity to modifiers. We test our benchmark using BERT classifiers fine-tuned on the LIAR arXiv:arch-ive/1705648 and Kaggle Fake-News datasets, and show that both models fail to respond to changes in compositional and lexical meaning. Our results strengthen the need for such models to be used in conjunction with other fact checking methods.