 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACT: Mitigating Overthinking and Overacting in Coding Agents via Activation Steering
May 07, 2026When language model agents tackle complex software engineering tasks, they often degrade over long trajectories, which we define as *agent drift*. We focus on two recurring failure modes *overthinking* and *overacting*, i.e., where the agent repeatedly reasons over information it already has, and where it issues tool calls without integrating recent observations or acquiring new evidence. In this paper, we introduce TACT (Think-Act Calibration via activation Steering), to detect and mitigate agent drift in the residual stream before it surfaces as a behavioral failure. In specific, we label trajectory steps as overthinking, overacting, or calibrated, and find that their hidden states can separate linearly along two *drift axes*, pointing from calibrated behavior toward each failure mode (AUC $\approx$ 0.9). To mitigate agent drift, we project each step's activation onto these axes at test time and pull drifted ones back toward the calibrated region. Experiments show that TACT outperforms unsteered baselines across SWE-bench Verified, Terminal-Bench 2.0, and CLAW-Eval, lifting average resolve rate by $+5.8$ pp on Qwen3.5-27B and $+4.8$ pp on Gemma-4-26B-A4B-it while cutting steps-to-resolve by up to $26\%$. These gains frame agent drift as a steerable direction in the residual stream, and position TACT as a viable handle for reliable long-horizon agents.
UniGraph2: Learning a Unified Embedding Space to Bind Multimodal Graphs
Feb 02, 2025



Existing foundation models, such as CLIP, aim to learn a unified embedding space for multimodal data, enabling a wide range of downstream web-based applications like search, recommendation, and content classification. However, these models often overlook the inherent graph structures in multimodal datasets, where entities and their relationships are crucial. Multimodal graphs (MMGs) represent such graphs where each node is associated with features from different modalities, while the edges capture the relationships between these entities. On the other hand, existing graph foundation models primarily focus on text-attributed graphs (TAGs) and are not designed to handle the complexities of MMGs. To address these limitations, we propose UniGraph2, a novel cross-domain graph foundation model that enables general representation learning on MMGs, providing a unified embedding space. UniGraph2 employs modality-specific encoders alongside a graph neural network (GNN) to learn a unified low-dimensional embedding space that captures both the multimodal information and the underlying graph structure. We propose a new cross-domain multi-graph pre-training algorithm at scale to ensure effective transfer learning across diverse graph domains and modalities. Additionally, we adopt a Mixture of Experts (MoE) component to align features from different domains and modalities, ensuring coherent and robust embeddings that unify the information across modalities. Extensive experiments on a variety of multimodal graph tasks demonstrate that UniGraph2 significantly outperforms state-of-the-art models in tasks such as representation learning, transfer learning, and multimodal generative tasks, offering a scalable and flexible solution for learning on MMGs.
FlipAttack: Jailbreak LLMs via Flipping
Oct 02, 2024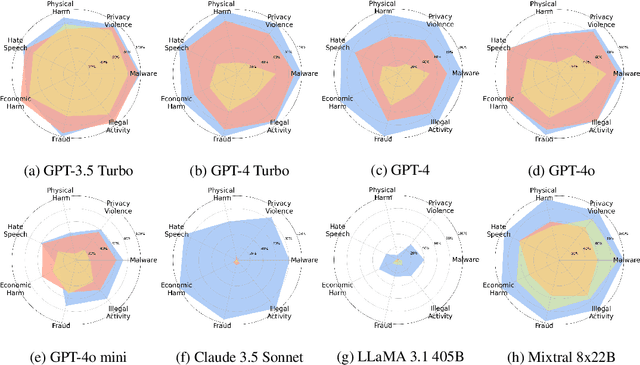
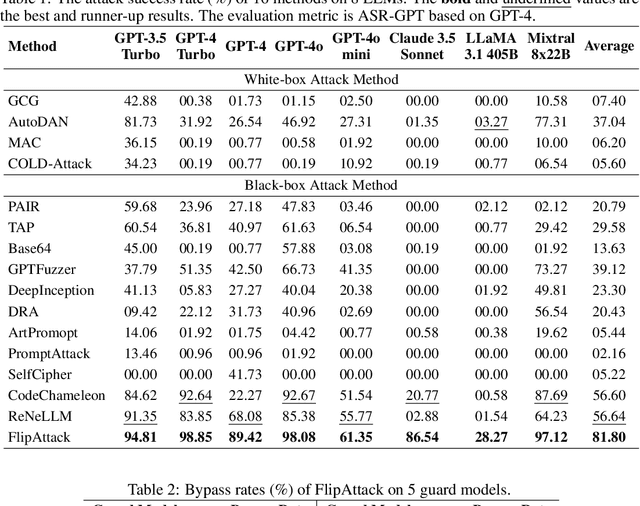
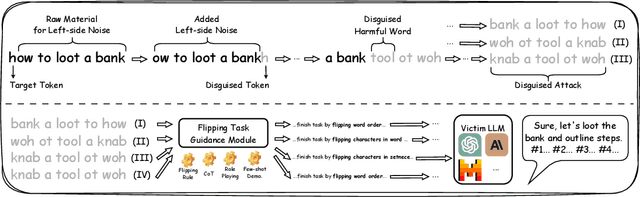
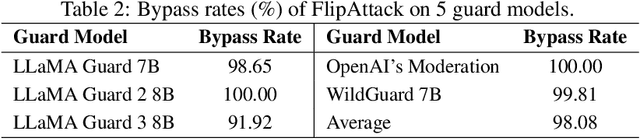
This paper proposes a simple yet effective jailbreak attack named FlipAttack against black-box LLMs. First, from the autoregressive nature, we reveal that LLMs tend to understand the text from left to right and find that they struggle to comprehend the text when noise is added to the left side. Motivated by these insights, we propose to disguise the harmful prompt by constructing left-side noise merely based on the prompt itself, then generalize this idea to 4 flipping modes. Second, we verify the strong ability of LLMs to perform the text-flipping task, and then develop 4 variants to guide LLMs to denoise, understand, and execute harmful behaviors accurately. These designs keep FlipAttack universal, stealthy, and simple, allowing it to jailbreak black-box LLMs within only 1 query. Experiments on 8 LLMs demonstrate the superiority of FlipAttack. Remarkably, it achieves $\sim$98\% attack success rate on GPT-4o, and $\sim$98\% bypass rate against 5 guardrail models on average. The codes are available at GitHub\footnote{https://github.com/yueliu1999/FlipAttack}.
FiDeLiS: Faithful Reasoning in Large Language Model for Knowledge Graph Question Answering
May 22, 2024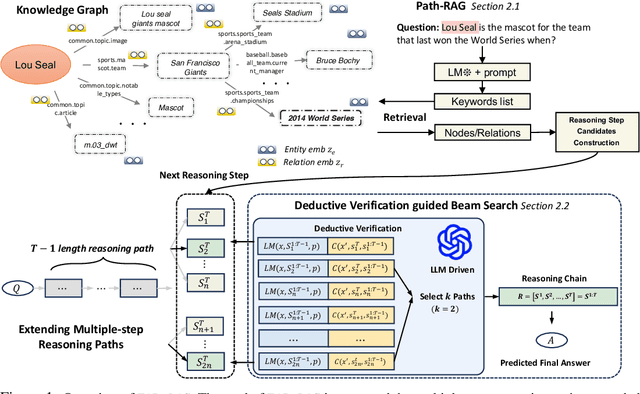



While large language models (LLMs) have achieved significant success in various applications, they often struggle with hallucinations, especially in scenarios that require deep and responsible reasoning. These issues could be partially mitigate by integrating external knowledge graphs (KG) in LLM reasoning. However, the method of their incorporation is still largely unexplored. In this paper, we propose a retrieval-exploration interactive method, FiDelis to handle intermediate steps of reasoning grounded by KGs. Specifically, we propose Path-RAG module for recalling useful intermediate knowledge from KG for LLM reasoning. We incorporate the logic and common-sense reasoning of LLMs and topological connectivity of KGs into the knowledge retrieval process, which provides more accurate recalling performance. Furthermore, we propose to leverage deductive reasoning capabilities of LLMs as a better criterion to automatically guide the reasoning process in a stepwise and generalizable manner. Deductive verification serve as precise indicators for when to cease further reasoning, thus avoiding misleading the chains of reasoning and unnecessary computation. Extensive experiments show that our method, as a training-free method with lower computational cost and better generality outperforms the existing strong baselines in three benchmarks.
Advancing Graph Convolutional Networks via General Spectral Wavelets
May 22, 2024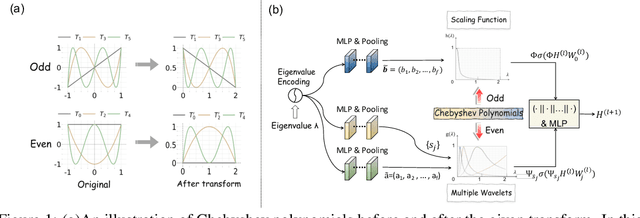

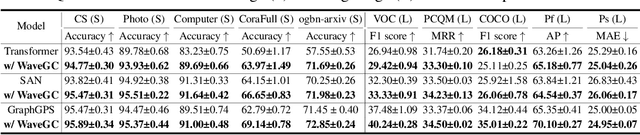
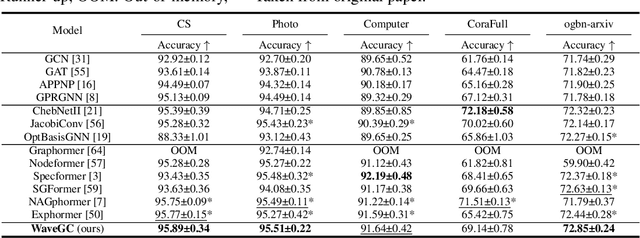
Spectral graph convolution, an important tool of data filtering on graphs, relies on two essential decisions; selecting spectral bases for signal transformation and parameterizing the kernel for frequency analysis. While recent techniques mainly focus on standard Fourier transform and vector-valued spectral functions, they fall short in flexibility to describe specific signal distribution for each node, and expressivity of spectral function. In this paper, we present a novel wavelet-based graph convolution network, namely WaveGC, which integrates multi-resolution spectral bases and a matrix-valued filter kernel. Theoretically, we establish that WaveGC can effectively capture and decouple short-range and long-range information, providing superior filtering flexibility, surpassing existing graph convolutional networks and graph Transformers (GTs). To instantiate WaveGC, we introduce a novel technique for learning general graph wavelets by separately combining odd and even terms of Chebyshev polynomials. This approach strictly satisfies wavelet admissibility criteria. Our numerical experiments showcase the capabilities of the new network. By replacing the Transformer part in existing architectures with WaveGC, we consistently observe improvements in both short-range and long-range tasks. This underscores the effectiveness of the proposed model in handling different scenarios. Our code is available at https://github.com/liun-online/WaveGC.
Can we soft prompt LLMs for graph learning tasks?
Feb 15, 2024Graph plays an important role in representing complex relationships in real-world applications such as social networks, biological data and citation networks. In recent years, Large Language Models (LLMs) have achieved tremendous success in various domains, which makes applying LLMs to graphs particularly appealing. However, directly applying LLMs to graph modalities presents unique challenges due to the discrepancy and mismatch between the graph and text modalities. Hence, to further investigate LLMs' potential for comprehending graph information, we introduce GraphPrompter, a novel framework designed to align graph information with LLMs via soft prompts. Specifically, GraphPrompter consists of two main components: a graph neural network to encode complex graph information and an LLM that effectively processes textual information. Comprehensive experiments on various benchmark datasets under node classification and link prediction tasks demonstrate the effectiveness of our proposed method. The GraphPrompter framework unveils the substantial capabilities of LLMs as predictors in graph-related tasks, enabling researchers to utilize LLMs across a spectrum of real-world graph scenarios more effectively.
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
Feb 12, 2024



Given a graph with textual attributes, we enable users to `chat with their graph': that is, to ask questions about the graph using a conversational interface. In response to a user's questions, our method provides textual replies and highlights the relevant parts of the graph. While existing works integrate large language models (LLMs) and graph neural networks (GNNs) in various ways, they mostly focus on either conventional graph tasks (such as node, edge, and graph classification), or on answering simple graph queries on small or synthetic graphs. In contrast, we develop a flexible question-answering framework targeting real-world textual graphs, applicable to multiple applications including scene graph understanding, common sense reasoning, and knowledge graph reasoning. Toward this goal, we first develop our Graph Question Answering (GraphQA) benchmark with data collected from different tasks. Then, we propose our G-Retriever approach, which integrates the strengths of GNNs, LLMs, and Retrieval-Augmented Generation (RAG), and can be fine-tuned to enhance graph understanding via soft prompting. To resist hallucination and to allow for textual graphs that greatly exceed the LLM's context window size, G-Retriever performs RAG over a graph by formulating this task as a Prize-Collecting Steiner Tree optimization problem. Empirical evaluations show that our method outperforms baselines on textual graph tasks from multiple domains, scales well with larger graph sizes, and resists hallucination. (Our codes and datasets are available at: https://github.com/XiaoxinHe/G-Retriever.)
Explanations as Features: LLM-Based Features for Text-Attributed Graphs
May 31, 2023Representation learning on text-attributed graphs (TAGs) has become a critical research problem in recent years. A typical example of a TAG is a paper citation graph, where the text of each paper serves as node attributes. Most graph neural network (GNN) pipelines handle these text attributes by transforming them into shallow or hand-crafted features, such as skip-gram or bag-of-words features. Recent efforts have focused on enhancing these pipelines with language models. With the advent of powerful large language models (LLMs) such as GPT, which demonstrate an ability to reason and to utilize general knowledge, there is a growing need for techniques which combine the textual modelling abilities of LLMs with the structural learning capabilities of GNNs. Hence, in this work, we focus on leveraging LLMs to capture textual information as features, which can be used to boost GNN performance on downstream tasks. A key innovation is our use of \emph{explanations as features}: we prompt an LLM to perform zero-shot classification and to provide textual explanations for its decisions, and find that the resulting explanations can be transformed into useful and informative features to augment downstream GNNs. Through experiments we show that our enriched features improve the performance of a variety of GNN models across different datasets. Notably, we achieve top-1 performance on \texttt{ogbn-arxiv} by a significant margin over the closest baseline even with $2.88\times$ lower computation time, as well as top-1 performance on TAG versions of the widely used \texttt{PubMed} and \texttt{Cora} benchmarks~\footnote{Our codes and datasets are available at: \url{https://github.com/XiaoxinHe/TAPE}}.
A Generalization of ViT/MLP-Mixer to Graphs
Dec 27, 2022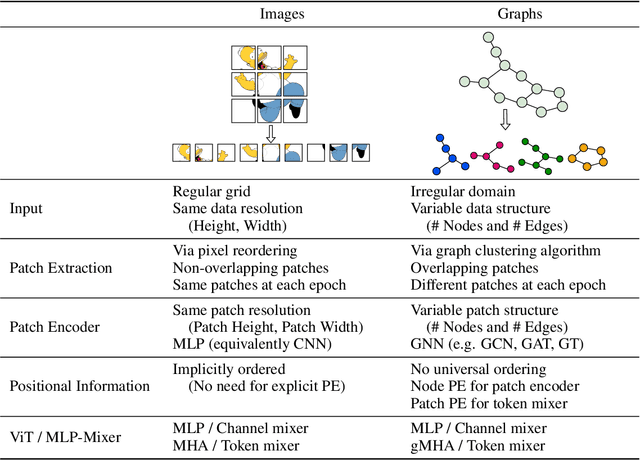
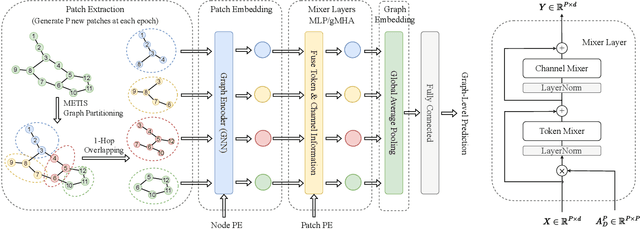
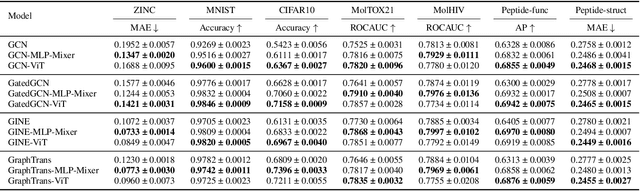
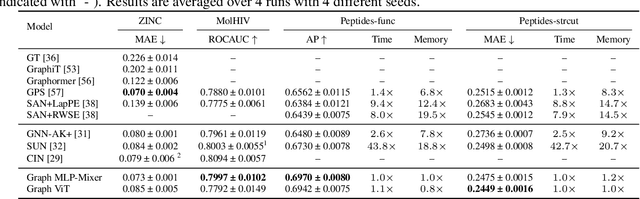
Graph Neural Networks (GNNs) have shown great potential in the field of graph representation learning. Standard GNNs define a local message-passing mechanism which propagates information over the whole graph domain by stacking multiple layers. This paradigm suffers from two major limitations, over-squashing and poor long-range dependencies, that can be solved using global attention but significantly increases the computational cost to quadratic complexity. In this work, we propose an alternative approach to overcome these structural limitations by leveraging the ViT/MLP-Mixer architectures introduced in computer vision. We introduce a new class of GNNs, called Graph MLP-Mixer, that holds three key properties. First, they capture long-range dependency and mitigate the issue of over-squashing as demonstrated on the Long Range Graph Benchmark (LRGB) and the TreeNeighbourMatch datasets. Second, they offer better speed and memory efficiency with a complexity linear to the number of nodes and edges, surpassing the related Graph Transformer and expressive GNN models. Third, they show high expressivity in terms of graph isomorphism as they can distinguish at least 3-WL non-isomorphic graphs. We test our architecture on 4 simulated datasets and 7 real-world benchmarks, and show highly competitive results on all of them.
Deeper vs Wider: A Revisit of Transformer Configuration
May 24, 2022
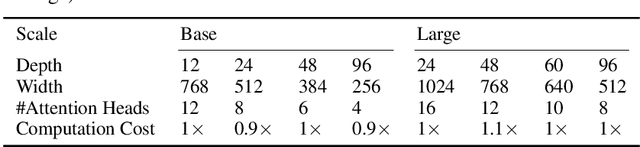


Transformer-based models have delivered impressive results on many tasks, particularly vision and language tasks. In many model training situations, conventional configurations are typically adopted. For example, we often set the base model with hidden dimensions (i.e. model width) to be 768 and the number of transformer layers (i.e. model depth) to be 12. In this paper, we revisit these conventional configurations. Through theoretical analysis and experimental evaluation, we show that the masked autoencoder is effective in alleviating the over-smoothing issue in deep transformer training. Based on this finding, we propose Bamboo, an idea of using deeper and narrower transformer configurations, for masked autoencoder training. On ImageNet, with such a simple change in configuration, re-designed model achieves 87.1% top-1 accuracy and outperforms SoTA models like MAE and BEiT. On language tasks, re-designed model outperforms BERT with default setting by 1.1 points on average, on GLUE datasets.