 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Steering Works: Toward a Unified View of Language Model Parameter Dynamics
Feb 02, 2026Methods for controlling large language models (LLMs), including local weight fine-tuning, LoRA-based adaptation, and activation-based interventions, are often studied in isolation, obscuring their connections and making comparison difficult. In this work, we present a unified view that frames these interventions as dynamic weight updates induced by a control signal, placing them within a single conceptual framework. Building on this view, we propose a unified preference-utility analysis that separates control effects into preference, defined as the tendency toward a target concept, and utility, defined as coherent and task-valid generation, and measures both on a shared log-odds scale using polarity-paired contrastive examples. Across methods, we observe a consistent trade-off between preference and utility: stronger control increases preference while predictably reducing utility. We further explain this behavior through an activation manifold perspective, in which control shifts representations along target-concept directions to enhance preference, while utility declines primarily when interventions push representations off the model's valid-generation manifold. Finally, we introduce a new steering approach SPLIT guided by this analysis that improves preference while better preserving utility. Code is available at https://github.com/zjunlp/EasyEdit/blob/main/examples/SPLIT.md.
Illusions of Confidence? Diagnosing LLM Truthfulness via Neighborhood Consistency
Jan 09, 2026As Large Language Models (LLMs) are increasingly deployed in real-world settings, correctness alone is insufficient. Reliable deployment requires maintaining truthful beliefs under contextual perturbations. Existing evaluations largely rely on point-wise confidence like Self-Consistency, which can mask brittle belief. We show that even facts answered with perfect self-consistency can rapidly collapse under mild contextual interference. To address this gap, we propose Neighbor-Consistency Belief (NCB), a structural measure of belief robustness that evaluates response coherence across a conceptual neighborhood. To validate the efficiency of NCB, we introduce a new cognitive stress-testing protocol that probes outputs stability under contextual interference. Experiments across multiple LLMs show that the performance of high-NCB data is relatively more resistant to interference. Finally, we present Structure-Aware Training (SAT), which optimizes context-invariant belief structure and reduces long-tail knowledge brittleness by approximately 30%. Code will be available at https://github.com/zjunlp/belief.
Retrieval-augmented Prompt Learning for Pre-trained Foundation Models
Dec 23, 2025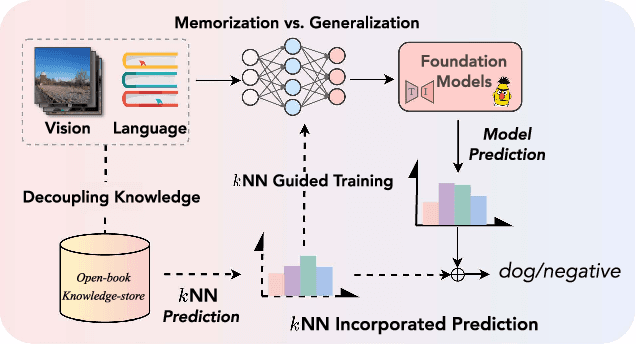
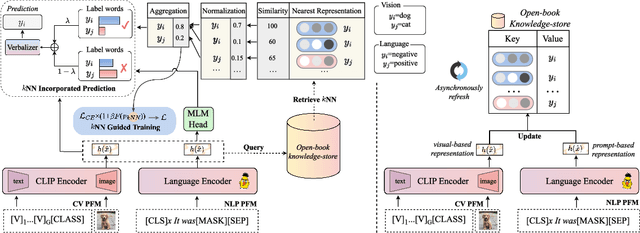
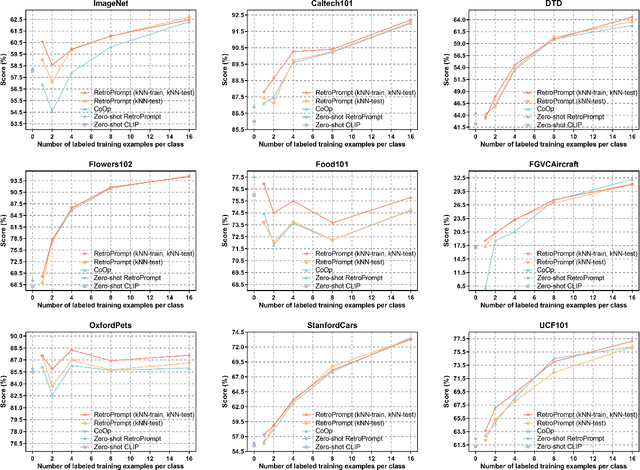
The pre-trained foundation models (PFMs) have become essential for facilitating large-scale multimodal learning. Researchers have effectively employed the ``pre-train, prompt, and predict'' paradigm through prompt learning to induce improved few-shot performance. However, prompt learning approaches for PFMs still follow a parametric learning paradigm. As such, the stability of generalization in memorization and rote learning can be compromised. More specifically, conventional prompt learning might face difficulties in fully utilizing atypical instances and avoiding overfitting to shallow patterns with limited data during the process of fully-supervised training. To overcome these constraints, we present our approach, named RetroPrompt, which aims to achieve a balance between memorization and generalization by decoupling knowledge from mere memorization. Unlike traditional prompting methods, RetroPrompt leverages a publicly accessible knowledge base generated from the training data and incorporates a retrieval mechanism throughout the input, training, and inference stages. This enables the model to actively retrieve relevant contextual information from the corpus, thereby enhancing the available cues. We conduct comprehensive experiments on a variety of datasets across natural language processing and computer vision tasks to demonstrate the superior performance of our proposed approach, RetroPrompt, in both zero-shot and few-shot scenarios. Through detailed analysis of memorization patterns, we observe that RetroPrompt effectively reduces the reliance on rote memorization, leading to enhanced generalization.
LightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025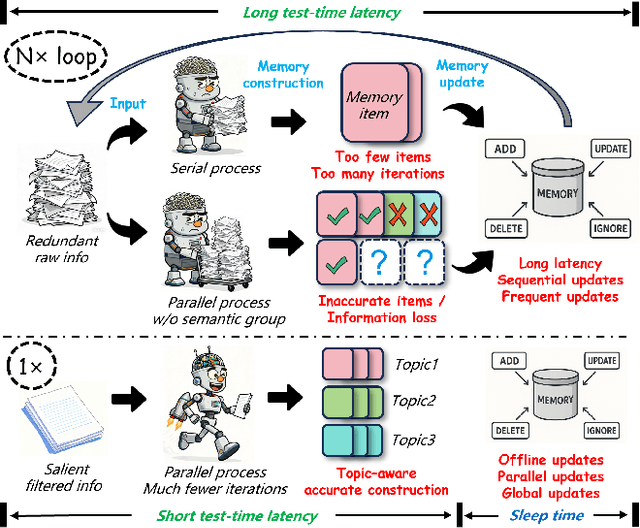
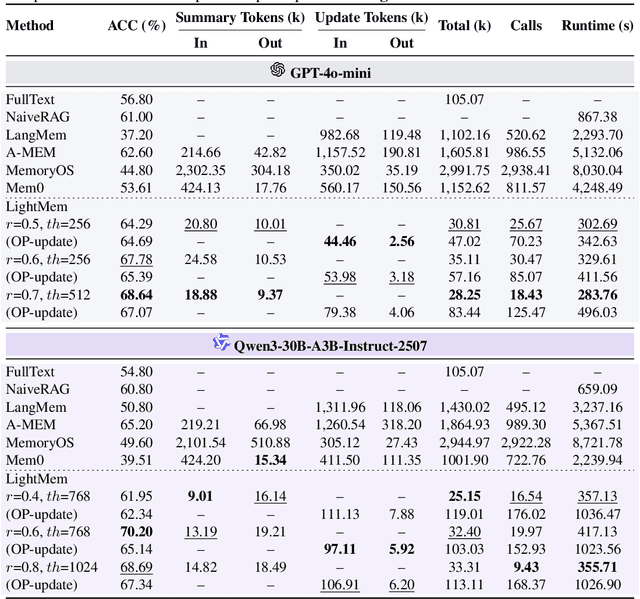
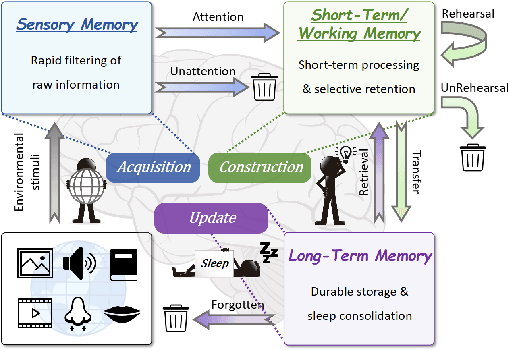
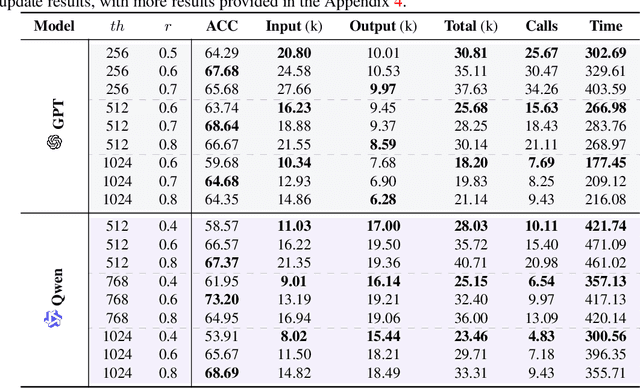
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
OceanGym: A Benchmark Environment for Underwater Embodied Agents
Sep 30, 2025We introduce OceanGym, the first comprehensive benchmark for ocean underwater embodied agents, designed to advance AI in one of the most demanding real-world environments. Unlike terrestrial or aerial domains, underwater settings present extreme perceptual and decision-making challenges, including low visibility, dynamic ocean currents, making effective agent deployment exceptionally difficult. OceanGym encompasses eight realistic task domains and a unified agent framework driven by Multi-modal Large Language Models (MLLMs), which integrates perception, memory, and sequential decision-making. Agents are required to comprehend optical and sonar data, autonomously explore complex environments, and accomplish long-horizon objectives under these harsh conditions. Extensive experiments reveal substantial gaps between state-of-the-art MLLM-driven agents and human experts, highlighting the persistent difficulty of perception, planning, and adaptability in ocean underwater environments. By providing a high-fidelity, rigorously designed platform, OceanGym establishes a testbed for developing robust embodied AI and transferring these capabilities to real-world autonomous ocean underwater vehicles, marking a decisive step toward intelligent agents capable of operating in one of Earth's last unexplored frontiers. The code and data are available at https://github.com/OceanGPT/OceanGym.
Automating Steering for Safe Multimodal Large Language Models
Jul 17, 2025Recent progress in Multimodal Large Language Models (MLLMs) has unlocked powerful cross-modal reasoning abilities, but also raised new safety concerns, particularly when faced with adversarial multimodal inputs. To improve the safety of MLLMs during inference, we introduce a modular and adaptive inference-time intervention technology, AutoSteer, without requiring any fine-tuning of the underlying model. AutoSteer incorporates three core components: (1) a novel Safety Awareness Score (SAS) that automatically identifies the most safety-relevant distinctions among the model's internal layers; (2) an adaptive safety prober trained to estimate the likelihood of toxic outputs from intermediate representations; and (3) a lightweight Refusal Head that selectively intervenes to modulate generation when safety risks are detected. Experiments on LLaVA-OV and Chameleon across diverse safety-critical benchmarks demonstrate that AutoSteer significantly reduces the Attack Success Rate (ASR) for textual, visual, and cross-modal threats, while maintaining general abilities. These findings position AutoSteer as a practical, interpretable, and effective framework for safer deployment of multimodal AI systems.
ChineseHarm-Bench: A Chinese Harmful Content Detection Benchmark
Jun 12, 2025Large language models (LLMs) have been increasingly applied to automated harmful content detection tasks, assisting moderators in identifying policy violations and improving the overall efficiency and accuracy of content review. However, existing resources for harmful content detection are predominantly focused on English, with Chinese datasets remaining scarce and often limited in scope. We present a comprehensive, professionally annotated benchmark for Chinese content harm detection, which covers six representative categories and is constructed entirely from real-world data. Our annotation process further yields a knowledge rule base that provides explicit expert knowledge to assist LLMs in Chinese harmful content detection. In addition, we propose a knowledge-augmented baseline that integrates both human-annotated knowledge rules and implicit knowledge from large language models, enabling smaller models to achieve performance comparable to state-of-the-art LLMs. Code and data are available at https://github.com/zjunlp/ChineseHarm-bench.
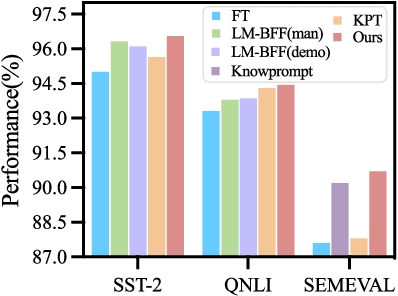
ZJUKLAB at SemEval-2025 Task 4: Unlearning via Model Merging
Mar 27, 2025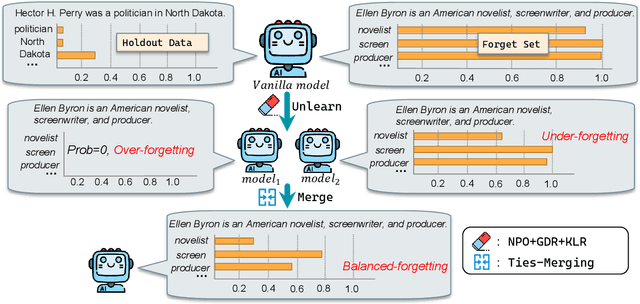
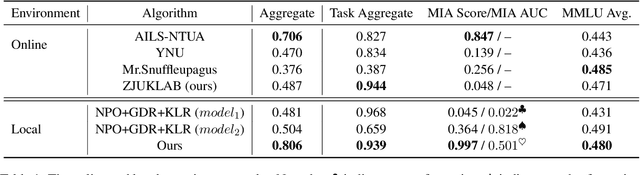
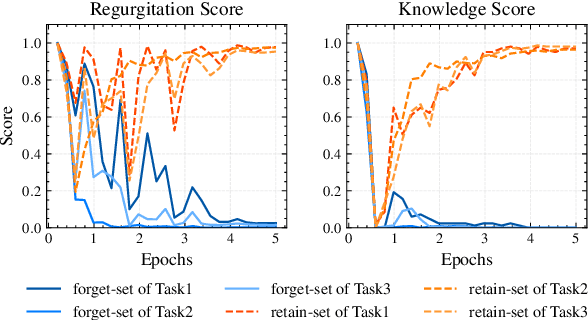
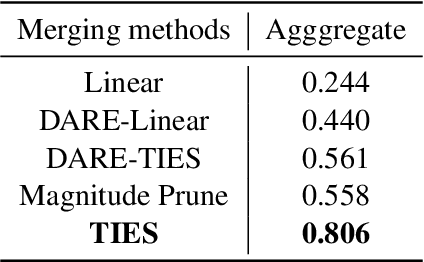
This paper presents the ZJUKLAB team's submission for SemEval-2025 Task 4: Unlearning Sensitive Content from Large Language Models. This task aims to selectively erase sensitive knowledge from large language models, avoiding both over-forgetting and under-forgetting issues. We propose an unlearning system that leverages Model Merging (specifically TIES-Merging), combining two specialized models into a more balanced unlearned model. Our system achieves competitive results, ranking second among 26 teams, with an online score of 0.944 for Task Aggregate and 0.487 for overall Aggregate. In this paper, we also conduct local experiments and perform a comprehensive analysis of the unlearning process, examining performance trajectories, loss dynamics, and weight perspectives, along with several supplementary experiments, to understand the effectiveness of our method. Furthermore, we analyze the shortcomings of our method and evaluation metrics, emphasizing that MIA scores and ROUGE-based metrics alone are insufficient to fully evaluate successful unlearning. Finally, we emphasize the need for more comprehensive evaluation methodologies and rethinking of unlearning objectives in future research. Code is available at https://github.com/zjunlp/unlearn/tree/main/semeval25.
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
Mar 20, 2025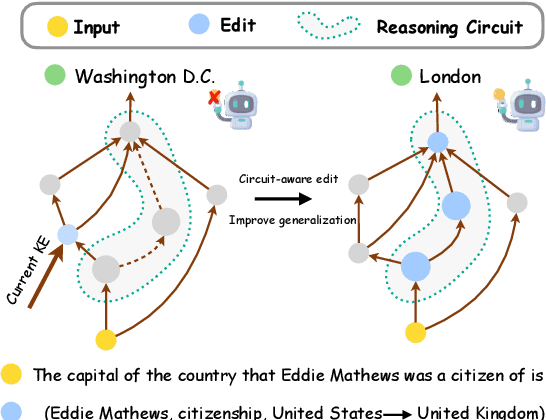



Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they struggle to generalize these updates to multi-hop reasoning tasks that depend on the modified knowledge. Through an analysis of reasoning circuits -- the neural pathways LLMs use for knowledge-based inference, we observe that current layer-localized KE approaches, such as MEMIT and WISE, which edit only single or a few model layers, struggle to effectively incorporate updated information into these reasoning pathways. To address this limitation, we propose CaKE (Circuit-aware Knowledge Editing), a novel method that enables more effective integration of updated knowledge in LLMs. CaKE leverages strategically curated data, guided by our circuits-based analysis, that enforces the model to utilize the modified knowledge, stimulating the model to develop appropriate reasoning circuits for newly integrated knowledge. Experimental results show that CaKE enables more accurate and consistent use of updated knowledge across related reasoning tasks, leading to an average of 20% improvement in multi-hop reasoning accuracy on MQuAKE dataset compared to existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
Exploring Model Kinship for Merging Large Language Models
Oct 16, 2024



Model merging has become one of the key technologies for enhancing the capabilities and efficiency of Large Language Models (LLMs). However, our understanding of the expected performance gains and principles when merging any two models remains limited. In this work, we introduce model kinship, the degree of similarity or relatedness between LLMs, analogous to biological evolution. With comprehensive empirical analysis, we find that there is a certain relationship between model kinship and the performance gains after model merging, which can help guide our selection of candidate models. Inspired by this, we propose a new model merging strategy: Top-k Greedy Merging with Model Kinship, which can yield better performance on benchmark datasets. Specifically, we discover that using model kinship as a criterion can assist us in continuously performing model merging, alleviating the degradation (local optima) in model evolution, whereas model kinship can serve as a guide to escape these traps. Code is available at https://github.com/zjunlp/ModelKinship.