 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025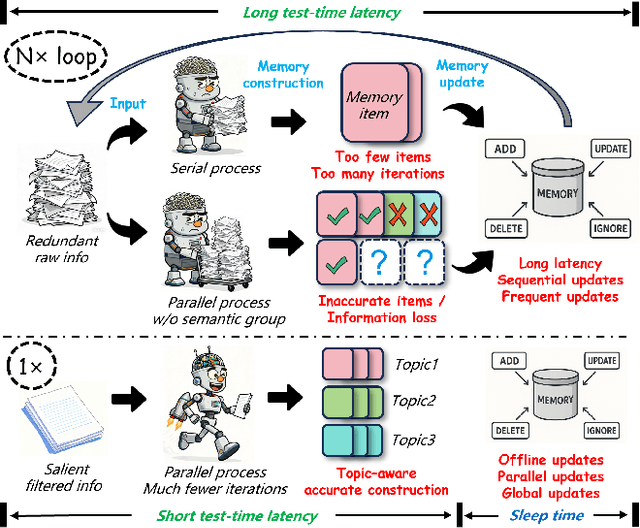
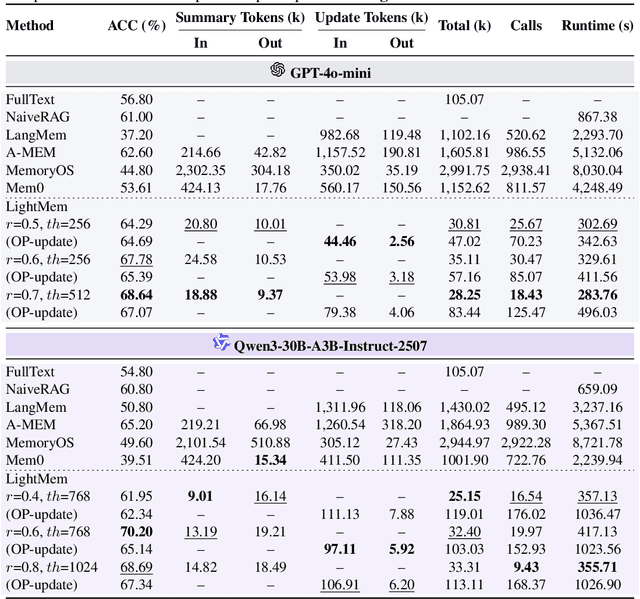
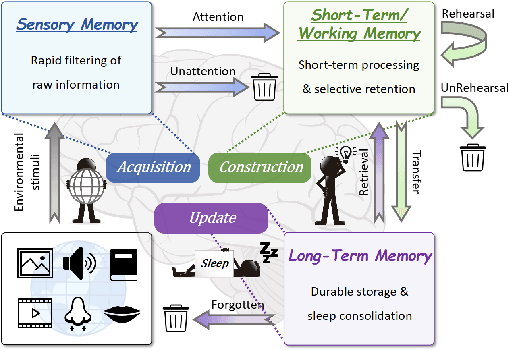
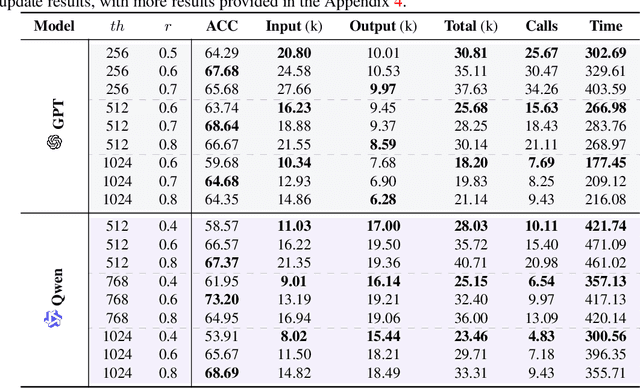
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
Mar 26, 2025



Recent advancements in Large Multimodal Models (LMMs) have shown promise in Autonomous Driving Systems (ADS). However, their direct application to ADS is hindered by challenges such as misunderstanding of traffic knowledge, complex road conditions, and diverse states of vehicle. To address these challenges, we propose the use of Knowledge Editing, which enables targeted modifications to a model's behavior without the need for full retraining. Meanwhile, we introduce ADS-Edit, a multimodal knowledge editing dataset specifically designed for ADS, which includes various real-world scenarios, multiple data types, and comprehensive evaluation metrics. We conduct comprehensive experiments and derive several interesting conclusions. We hope that our work will contribute to the further advancement of knowledge editing applications in the field of autonomous driving. Code and data are available in https://github.com/zjunlp/EasyEdit.
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
Mar 20, 2025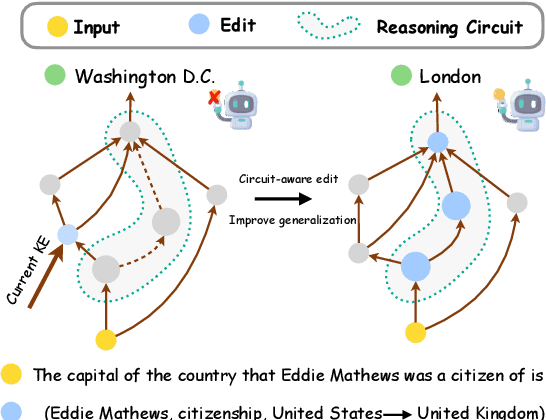



Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they struggle to generalize these updates to multi-hop reasoning tasks that depend on the modified knowledge. Through an analysis of reasoning circuits -- the neural pathways LLMs use for knowledge-based inference, we observe that current layer-localized KE approaches, such as MEMIT and WISE, which edit only single or a few model layers, struggle to effectively incorporate updated information into these reasoning pathways. To address this limitation, we propose CaKE (Circuit-aware Knowledge Editing), a novel method that enables more effective integration of updated knowledge in LLMs. CaKE leverages strategically curated data, guided by our circuits-based analysis, that enforces the model to utilize the modified knowledge, stimulating the model to develop appropriate reasoning circuits for newly integrated knowledge. Experimental results show that CaKE enables more accurate and consistent use of updated knowledge across related reasoning tasks, leading to an average of 20% improvement in multi-hop reasoning accuracy on MQuAKE dataset compared to existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
OmniThink: Expanding Knowledge Boundaries in Machine Writing through Thinking
Jan 16, 2025Machine writing with large language models often relies on retrieval-augmented generation. However, these approaches remain confined within the boundaries of the model's predefined scope, limiting the generation of content with rich information. Specifically, vanilla-retrieved information tends to lack depth, utility, and suffers from redundancy, which negatively impacts the quality of generated articles, leading to shallow, repetitive, and unoriginal outputs. To address these issues, we propose OmniThink, a machine writing framework that emulates the human-like process of iterative expansion and reflection. The core idea behind OmniThink is to simulate the cognitive behavior of learners as they progressively deepen their knowledge of the topics. Experimental results demonstrate that OmniThink improves the knowledge density of generated articles without compromising metrics such as coherence and depth. Human evaluations and expert feedback further highlight the potential of OmniThink to address real-world challenges in the generation of long-form articles.
Benchmarking Chinese Knowledge Rectification in Large Language Models
Sep 09, 2024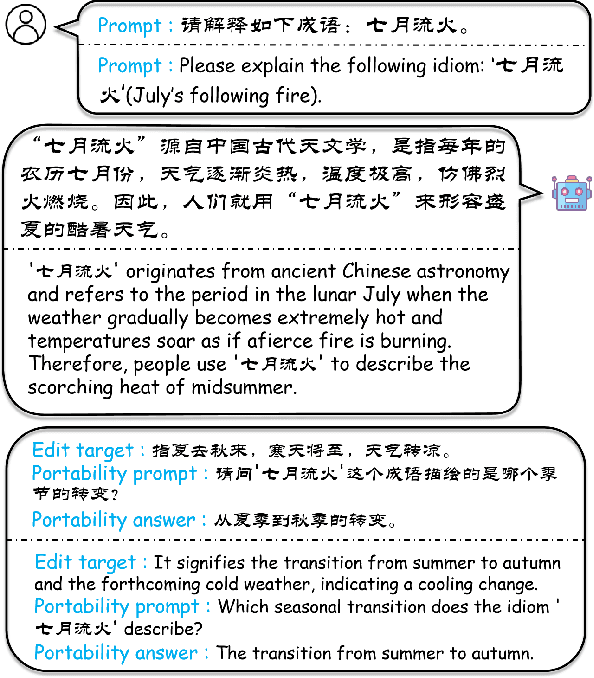

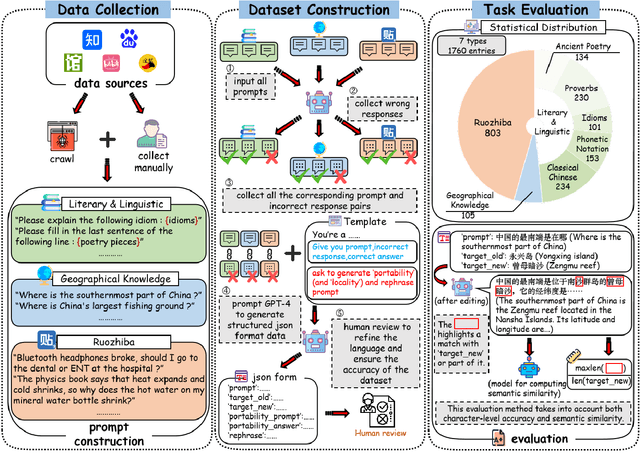
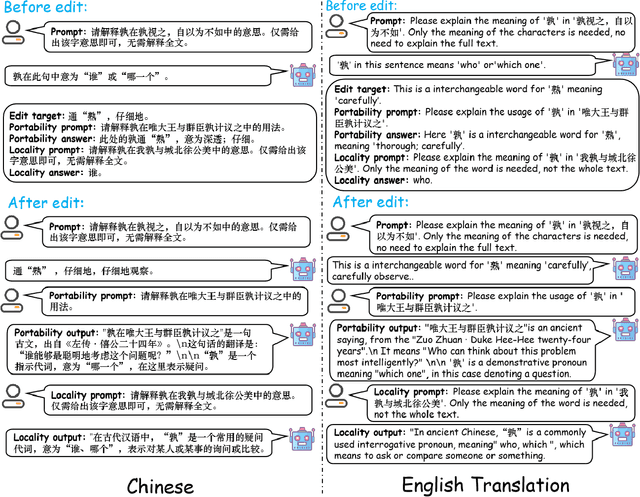
While Large Language Models (LLMs) exhibit remarkable generative capabilities, they are not without flaws, particularly in the form of hallucinations. This issue is even more pronounced when LLMs are applied to specific languages and domains. For example, LLMs may generate nonsense information when handling Chinese ancient poetry, proverbs, or idioms, owing to the lack of specific knowledge. To this end, this paper introduces a benchmark for rectifying Chinese knowledge in LLMs via knowledge editing. Specifically, we introduce a new Chinese dataset, CKnowEdit, by collecting seven type of knowledge from various sources, including classical texts, idioms, and content from Baidu Tieba Ruozhiba, thereby accounting for the unique polyphony, antithesis, and logical constructs inherent in the Chinese language. Through the analysis of this dataset, we uncover the challenges faced by current LLMs in mastering Chinese. Furthermore, our evaluation of state-of-the-art knowledge editing techniques on this dataset unveil the substantial scope for advancement in the rectification of Chinese knowledge. Code and dataset are available at https://github.com/zjunlp/EasyEdit.