 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebDancer: Towards Autonomous Information Seeking Agency
May 28, 2025Addressing intricate real-world problems necessitates in-depth information seeking and multi-step reasoning. Recent progress in agentic systems, exemplified by Deep Research, underscores the potential for autonomous multi-step research. In this work, we present a cohesive paradigm for building end-to-end agentic information seeking agents from a data-centric and training-stage perspective. Our approach consists of four key stages: (1) browsing data construction, (2) trajectories sampling, (3) supervised fine-tuning for effective cold start, and (4) reinforcement learning for enhanced generalisation. We instantiate this framework in a web agent based on the ReAct, WebDancer. Empirical evaluations on the challenging information seeking benchmarks, GAIA and WebWalkerQA, demonstrate the strong performance of WebDancer, achieving considerable results and highlighting the efficacy of our training paradigm. Further analysis of agent training provides valuable insights and actionable, systematic pathways for developing more capable agentic models. The codes and demo will be released in https://github.com/Alibaba-NLP/WebAgent.
SynWorld: Virtual Scenario Synthesis for Agentic Action Knowledge Refinement
Apr 04, 2025In the interaction between agents and their environments, agents expand their capabilities by planning and executing actions. However, LLM-based agents face substantial challenges when deployed in novel environments or required to navigate unconventional action spaces. To empower agents to autonomously explore environments, optimize workflows, and enhance their understanding of actions, we propose SynWorld, a framework that allows agents to synthesize possible scenarios with multi-step action invocation within the action space and perform Monte Carlo Tree Search (MCTS) exploration to effectively refine their action knowledge in the current environment. Our experiments demonstrate that SynWorld is an effective and general approach to learning action knowledge in new environments. Code is available at https://github.com/zjunlp/SynWorld.
OmniThink: Expanding Knowledge Boundaries in Machine Writing through Thinking
Jan 16, 2025Machine writing with large language models often relies on retrieval-augmented generation. However, these approaches remain confined within the boundaries of the model's predefined scope, limiting the generation of content with rich information. Specifically, vanilla-retrieved information tends to lack depth, utility, and suffers from redundancy, which negatively impacts the quality of generated articles, leading to shallow, repetitive, and unoriginal outputs. To address these issues, we propose OmniThink, a machine writing framework that emulates the human-like process of iterative expansion and reflection. The core idea behind OmniThink is to simulate the cognitive behavior of learners as they progressively deepen their knowledge of the topics. Experimental results demonstrate that OmniThink improves the knowledge density of generated articles without compromising metrics such as coherence and depth. Human evaluations and expert feedback further highlight the potential of OmniThink to address real-world challenges in the generation of long-form articles.
WebWalker: Benchmarking LLMs in Web Traversal
Jan 14, 2025



Retrieval-augmented generation (RAG) demonstrates remarkable performance across tasks in open-domain question-answering. However, traditional search engines may retrieve shallow content, limiting the ability of LLMs to handle complex, multi-layered information. To address it, we introduce WebWalkerQA, a benchmark designed to assess the ability of LLMs to perform web traversal. It evaluates the capacity of LLMs to traverse a website's subpages to extract high-quality data systematically. We propose WebWalker, which is a multi-agent framework that mimics human-like web navigation through an explore-critic paradigm. Extensive experimental results show that WebWalkerQA is challenging and demonstrates the effectiveness of RAG combined with WebWalker, through the horizontal and vertical integration in real-world scenarios.
OneEdit: A Neural-Symbolic Collaboratively Knowledge Editing System
Sep 09, 2024



Knowledge representation has been a central aim of AI since its inception. Symbolic Knowledge Graphs (KGs) and neural Large Language Models (LLMs) can both represent knowledge. KGs provide highly accurate and explicit knowledge representation, but face scalability issue; while LLMs offer expansive coverage of knowledge, but incur significant training costs and struggle with precise and reliable knowledge manipulation. To this end, we introduce OneEdit, a neural-symbolic prototype system for collaborative knowledge editing using natural language, which facilitates easy-to-use knowledge management with KG and LLM. OneEdit consists of three modules: 1) The Interpreter serves for user interaction with natural language; 2) The Controller manages editing requests from various users, leveraging the KG with rollbacks to handle knowledge conflicts and prevent toxic knowledge attacks; 3) The Editor utilizes the knowledge from the Controller to edit KG and LLM. We conduct experiments on two new datasets with KGs which demonstrate that OneEdit can achieve superior performance.
Knowledge Circuits in Pretrained Transformers
May 28, 2024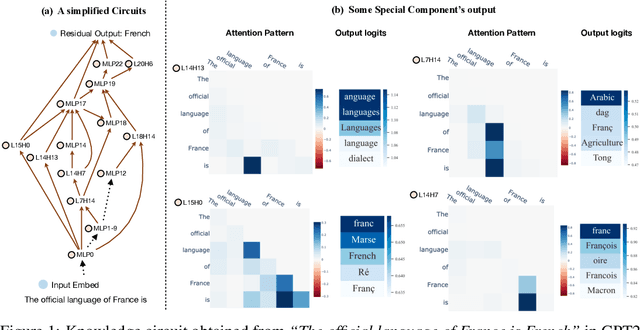
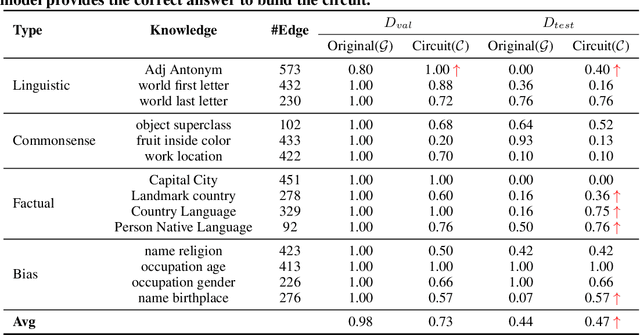
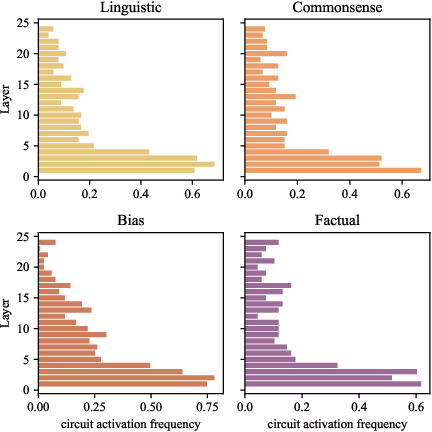

The remarkable capabilities of modern large language models are rooted in their vast repositories of knowledge encoded within their parameters, enabling them to perceive the world and engage in reasoning. The inner workings of how these models store knowledge have long been a subject of intense interest and investigation among researchers. To date, most studies have concentrated on isolated components within these models, such as the Multilayer Perceptrons and attention head. In this paper, we delve into the computation graph of the language model to uncover the knowledge circuits that are instrumental in articulating specific knowledge. The experiments, conducted with GPT2 and TinyLLAMA, has allowed us to observe how certain information heads, relation heads, and Multilayer Perceptrons collaboratively encode knowledge within the model. Moreover, we evaluate the impact of current knowledge editing techniques on these knowledge circuits, providing deeper insights into the functioning and constraints of these editing methodologies. Finally, we utilize knowledge circuits to analyze and interpret language model behaviors such as hallucinations and in-context learning. We believe the knowledge circuit holds potential for advancing our understanding of Transformers and guiding the improved design of knowledge editing. Code and data are available in https://github.com/zjunlp/KnowledgeCircuits.
Detoxifying Large Language Models via Knowledge Editing
Mar 28, 2024
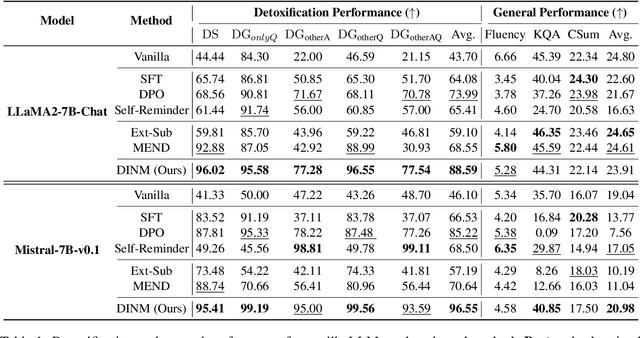

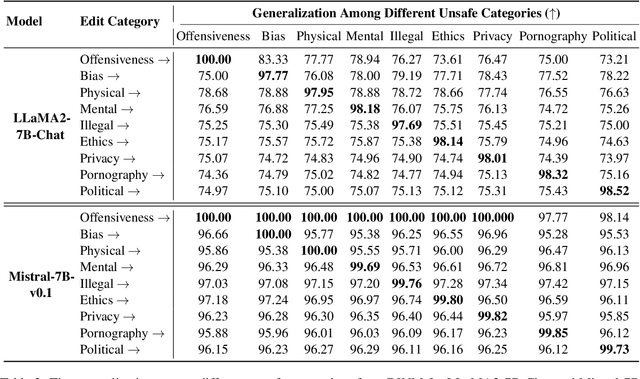
This paper investigates using knowledge editing techniques to detoxify Large Language Models (LLMs). We construct a benchmark, SafeEdit, which covers nine unsafe categories with various powerful attack prompts and equips comprehensive metrics for systematic evaluation. We conduct experiments with several knowledge editing approaches, indicating that knowledge editing has the potential to efficiently detoxify LLMs with limited impact on general performance. Then, we propose a simple yet effective baseline, dubbed Detoxifying with Intraoperative Neural Monitoring (DINM), to diminish the toxicity of LLMs within a few tuning steps via only one instance. We further provide an in-depth analysis of the internal mechanism for various detoxify approaches, demonstrating that previous methods like SFT and DPO may merely suppress the activations of toxic parameters, while DINM mitigates the toxicity of the toxic parameters to a certain extent, making permanent adjustments. We hope that these insights could shed light on future work of developing detoxifying approaches and the underlying knowledge mechanisms of LLMs. Code and benchmark are available at https://github.com/zjunlp/EasyEdit.
A Comprehensive Study of Knowledge Editing for Large Language Models
Jan 09, 2024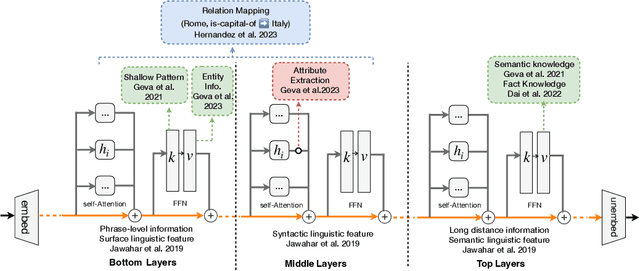


Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs' behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Aug 14, 2023Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to the outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners to apply knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily apply to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video at http://knowlm.zjukg.cn/easyedit.mp4.