 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyEdit2: An Easy-to-use Steering Framework for Editing Large Language Models
Apr 21, 2025



In this paper, we introduce EasyEdit2, a framework designed to enable plug-and-play adjustability for controlling Large Language Model (LLM) behaviors. EasyEdit2 supports a wide range of test-time interventions, including safety, sentiment, personality, reasoning patterns, factuality, and language features. Unlike its predecessor, EasyEdit2 features a new architecture specifically designed for seamless model steering. It comprises key modules such as the steering vector generator and the steering vector applier, which enable automatic generation and application of steering vectors to influence the model's behavior without modifying its parameters. One of the main advantages of EasyEdit2 is its ease of use-users do not need extensive technical knowledge. With just a single example, they can effectively guide and adjust the model's responses, making precise control both accessible and efficient. Empirically, we report model steering performance across different LLMs, demonstrating the effectiveness of these techniques. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit along with a demonstration notebook. In addition, we provide a demo video at https://zjunlp.github.io/project/EasyEdit2/video for a quick introduction.
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models
Feb 06, 2024



In recent years, instruction tuning has gained increasing attention and emerged as a crucial technique to enhance the capabilities of Large Language Models (LLMs). To construct high-quality instruction datasets, many instruction processing approaches have been proposed, aiming to achieve a delicate balance between data quantity and data quality. Nevertheless, due to inconsistencies that persist among various instruction processing methods, there is no standard open-source instruction processing implementation framework available for the community, which hinders practitioners from further developing and advancing. To facilitate instruction processing research and development, we present EasyInstruct, an easy-to-use instruction processing framework for LLMs, which modularizes instruction generation, selection, and prompting, while also considering their combination and interaction. EasyInstruct is publicly released and actively maintained at https://github.com/zjunlp/EasyInstruct, along with a running demo App at https://huggingface.co/spaces/zjunlp/EasyInstruct for quick-start, calling for broader research centered on instruction data.
OceanGPT: A Large Language Model for Ocean Science Tasks
Oct 19, 2023
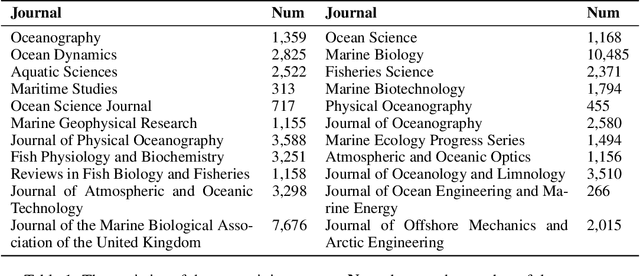
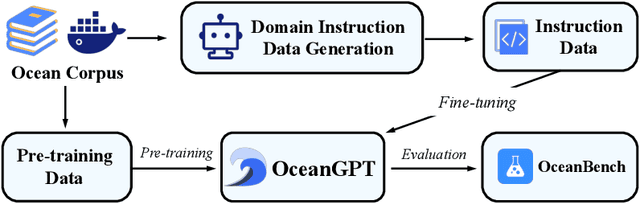

Ocean science, which delves into the oceans that are reservoirs of life and biodiversity, is of great significance given that oceans cover over 70% of our planet's surface. Recently, advances in Large Language Models (LLMs) have transformed the paradigm in science. Despite the success in other domains, current LLMs often fall short in catering to the needs of domain experts like oceanographers, and the potential of LLMs for ocean science is under-explored. The intrinsic reason may be the immense and intricate nature of ocean data as well as the necessity for higher granularity and richness in knowledge. To alleviate these issues, we introduce OceanGPT, the first-ever LLM in the ocean domain, which is expert in various ocean science tasks. We propose DoInstruct, a novel framework to automatically obtain a large volume of ocean domain instruction data, which generates instructions based on multi-agent collaboration. Additionally, we construct the first oceanography benchmark, OceanBench, to evaluate the capabilities of LLMs in the ocean domain. Though comprehensive experiments, OceanGPT not only shows a higher level of knowledge expertise for oceans science tasks but also gains preliminary embodied intelligence capabilities in ocean technology. Codes, data and checkpoints will soon be available at https://github.com/zjunlp/KnowLM.
When Do Program-of-Thoughts Work for Reasoning?
Sep 08, 2023The reasoning capabilities of Large Language Models (LLMs) play a pivotal role in the realm of embodied artificial intelligence. Although there are effective methods like program-of-thought prompting for LLMs which uses programming language to tackle complex reasoning tasks, the specific impact of code data on the improvement of reasoning capabilities remains under-explored. To address this gap, we propose complexity-impacted reasoning score (CIRS), which combines structural and logical attributes, to measure the correlation between code and reasoning abilities. Specifically, we use the abstract syntax tree to encode the structural information and calculate logical complexity by considering the difficulty and the cyclomatic complexity. Through an empirical analysis, we find not all code data of complexity can be learned or understood by LLMs. Optimal level of complexity is critical to the improvement of reasoning abilities by program-aided prompting. Then we design an auto-synthesizing and stratifying algorithm, and apply it to instruction generation for mathematical reasoning and code data filtering for code generation tasks. Extensive results demonstrates the effectiveness of our proposed approach. Code will be integrated into the EasyInstruct framework at https://github.com/zjunlp/EasyInstruct.
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Aug 14, 2023Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to the outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners to apply knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily apply to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub at https://github.com/zjunlp/EasyEdit, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video at http://knowlm.zjukg.cn/easyedit.mp4.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 24, 2022
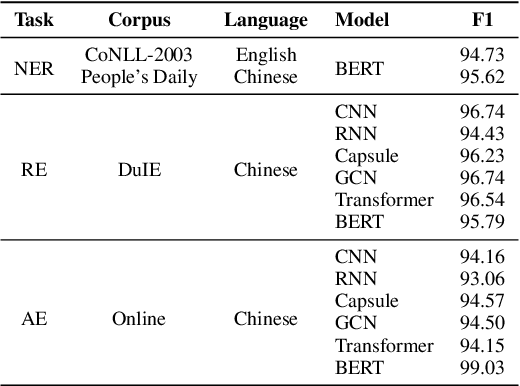
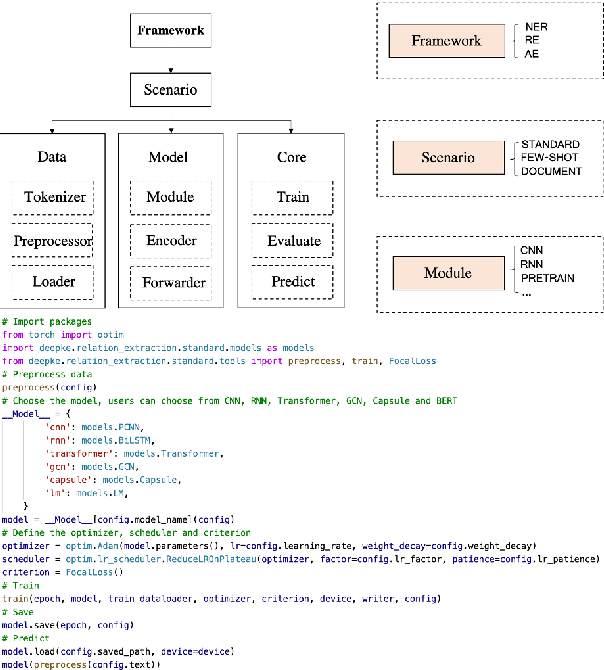
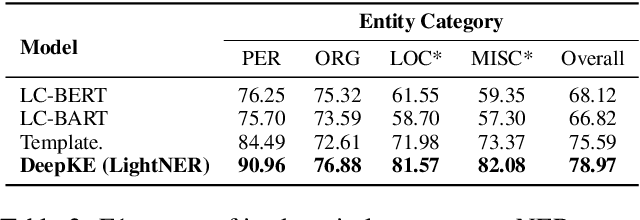
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in http://deepke.zjukg.cn/ for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at https://github.com/zjunlp/DeepKE, with a demo video.