 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOceanGym: A Benchmark Environment for Underwater Embodied Agents
Sep 30, 2025We introduce OceanGym, the first comprehensive benchmark for ocean underwater embodied agents, designed to advance AI in one of the most demanding real-world environments. Unlike terrestrial or aerial domains, underwater settings present extreme perceptual and decision-making challenges, including low visibility, dynamic ocean currents, making effective agent deployment exceptionally difficult. OceanGym encompasses eight realistic task domains and a unified agent framework driven by Multi-modal Large Language Models (MLLMs), which integrates perception, memory, and sequential decision-making. Agents are required to comprehend optical and sonar data, autonomously explore complex environments, and accomplish long-horizon objectives under these harsh conditions. Extensive experiments reveal substantial gaps between state-of-the-art MLLM-driven agents and human experts, highlighting the persistent difficulty of perception, planning, and adaptability in ocean underwater environments. By providing a high-fidelity, rigorously designed platform, OceanGym establishes a testbed for developing robust embodied AI and transferring these capabilities to real-world autonomous ocean underwater vehicles, marking a decisive step toward intelligent agents capable of operating in one of Earth's last unexplored frontiers. The code and data are available at https://github.com/OceanGPT/OceanGym.
Spatial Knowledge Graph-Guided Multimodal Synthesis
May 28, 2025Recent advances in multimodal large language models (MLLMs) have significantly enhanced their capabilities; however, their spatial perception abilities remain a notable limitation. To address this challenge, multimodal data synthesis offers a promising solution. Yet, ensuring that synthesized data adhere to spatial common sense is a non-trivial task. In this work, we introduce SKG2Data, a novel multimodal synthesis approach guided by spatial knowledge graphs, grounded in the concept of knowledge-to-data generation. SKG2Data automatically constructs a Spatial Knowledge Graph (SKG) to emulate human-like perception of spatial directions and distances, which is subsequently utilized to guide multimodal data synthesis. Extensive experiments demonstrate that data synthesized from diverse types of spatial knowledge, including direction and distance, not only enhance the spatial perception and reasoning abilities of MLLMs but also exhibit strong generalization capabilities. We hope that the idea of knowledge-based data synthesis can advance the development of spatial intelligence.
Unified Hallucination Detection for Multimodal Large Language Models
Feb 16, 2024


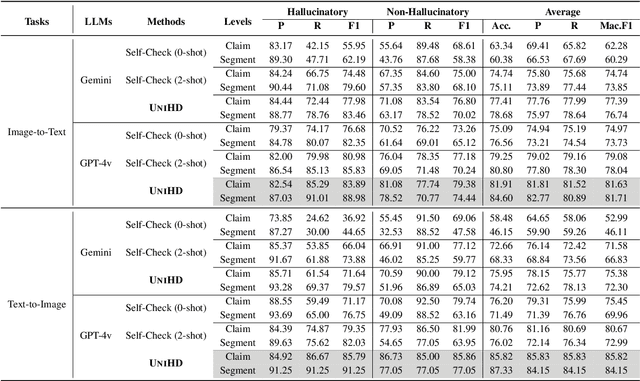
Despite significant strides in multimodal tasks, Multimodal Large Language Models (MLLMs) are plagued by the critical issue of hallucination. The reliable detection of such hallucinations in MLLMs has, therefore, become a vital aspect of model evaluation and the safeguarding of practical application deployment. Prior research in this domain has been constrained by a narrow focus on singular tasks, an inadequate range of hallucination categories addressed, and a lack of detailed granularity. In response to these challenges, our work expands the investigative horizons of hallucination detection. We present a novel meta-evaluation benchmark, MHaluBench, meticulously crafted to facilitate the evaluation of advancements in hallucination detection methods. Additionally, we unveil a novel unified multimodal hallucination detection framework, UNIHD, which leverages a suite of auxiliary tools to validate the occurrence of hallucinations robustly. We demonstrate the effectiveness of UNIHD through meticulous evaluation and comprehensive analysis. We also provide strategic insights on the application of specific tools for addressing various categories of hallucinations.
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models
Feb 06, 2024



In recent years, instruction tuning has gained increasing attention and emerged as a crucial technique to enhance the capabilities of Large Language Models (LLMs). To construct high-quality instruction datasets, many instruction processing approaches have been proposed, aiming to achieve a delicate balance between data quantity and data quality. Nevertheless, due to inconsistencies that persist among various instruction processing methods, there is no standard open-source instruction processing implementation framework available for the community, which hinders practitioners from further developing and advancing. To facilitate instruction processing research and development, we present EasyInstruct, an easy-to-use instruction processing framework for LLMs, which modularizes instruction generation, selection, and prompting, while also considering their combination and interaction. EasyInstruct is publicly released and actively maintained at https://github.com/zjunlp/EasyInstruct, along with a running demo App at https://huggingface.co/spaces/zjunlp/EasyInstruct for quick-start, calling for broader research centered on instruction data.
OceanGPT: A Large Language Model for Ocean Science Tasks
Oct 19, 2023
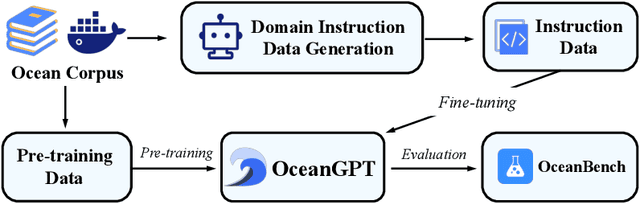

Ocean science, which delves into the oceans that are reservoirs of life and biodiversity, is of great significance given that oceans cover over 70% of our planet's surface. Recently, advances in Large Language Models (LLMs) have transformed the paradigm in science. Despite the success in other domains, current LLMs often fall short in catering to the needs of domain experts like oceanographers, and the potential of LLMs for ocean science is under-explored. The intrinsic reason may be the immense and intricate nature of ocean data as well as the necessity for higher granularity and richness in knowledge. To alleviate these issues, we introduce OceanGPT, the first-ever LLM in the ocean domain, which is expert in various ocean science tasks. We propose DoInstruct, a novel framework to automatically obtain a large volume of ocean domain instruction data, which generates instructions based on multi-agent collaboration. Additionally, we construct the first oceanography benchmark, OceanBench, to evaluate the capabilities of LLMs in the ocean domain. Though comprehensive experiments, OceanGPT not only shows a higher level of knowledge expertise for oceans science tasks but also gains preliminary embodied intelligence capabilities in ocean technology. Codes, data and checkpoints will soon be available at https://github.com/zjunlp/KnowLM.