 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnoEval: On Research Idea Evaluation as a Knowledge-Grounded, Multi-Perspective Reasoning Problem
Feb 16, 2026The rapid evolution of Large Language Models has catalyzed a surge in scientific idea production, yet this leap has not been accompanied by a matching advance in idea evaluation. The fundamental nature of scientific evaluation needs knowledgeable grounding, collective deliberation, and multi-criteria decision-making. However, existing idea evaluation methods often suffer from narrow knowledge horizons, flattened evaluation dimensions, and the inherent bias in LLM-as-a-Judge. To address these, we regard idea evaluation as a knowledge-grounded, multi-perspective reasoning problem and introduce InnoEval, a deep innovation evaluation framework designed to emulate human-level idea assessment. We apply a heterogeneous deep knowledge search engine that retrieves and grounds dynamic evidence from diverse online sources. We further achieve review consensus with an innovation review board containing reviewers with distinct academic backgrounds, enabling a multi-dimensional decoupled evaluation across multiple metrics. We construct comprehensive datasets derived from authoritative peer-reviewed submissions to benchmark InnoEval. Experiments demonstrate that InnoEval can consistently outperform baselines in point-wise, pair-wise, and group-wise evaluation tasks, exhibiting judgment patterns and consensus highly aligned with human experts.
Aligning Agentic World Models via Knowledgeable Experience Learning
Jan 19, 2026Current Large Language Models (LLMs) exhibit a critical modal disconnect: they possess vast semantic knowledge but lack the procedural grounding to respect the immutable laws of the physical world. Consequently, while these agents implicitly function as world models, their simulations often suffer from physical hallucinations-generating plans that are logically sound but physically unexecutable. Existing alignment strategies predominantly rely on resource-intensive training or fine-tuning, which attempt to compress dynamic environmental rules into static model parameters. However, such parametric encapsulation is inherently rigid, struggling to adapt to the open-ended variability of physical dynamics without continuous, costly retraining. To bridge this gap, we introduce WorldMind, a framework that autonomously constructs a symbolic World Knowledge Repository by synthesizing environmental feedback. Specifically, it unifies Process Experience to enforce physical feasibility via prediction errors and Goal Experience to guide task optimality through successful trajectories. Experiments on EB-ALFRED and EB-Habitat demonstrate that WorldMind achieves superior performance compared to baselines with remarkable cross-model and cross-environment transferability.
Retrieval-augmented Prompt Learning for Pre-trained Foundation Models
Dec 23, 2025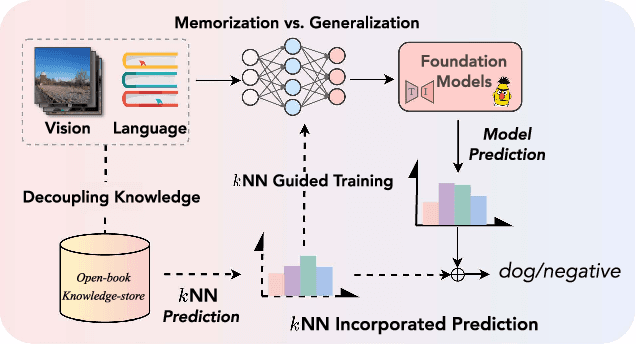
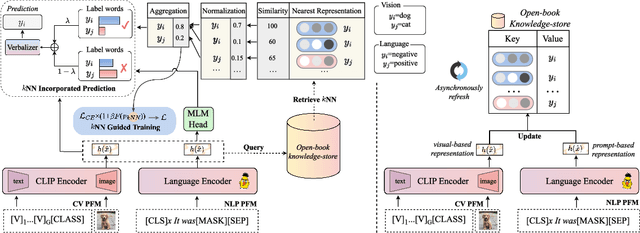
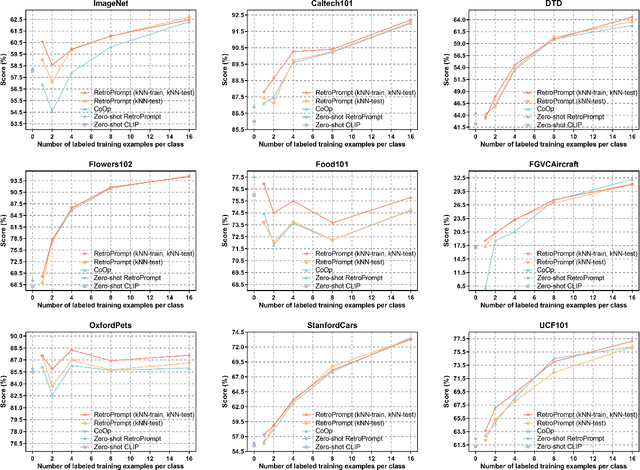
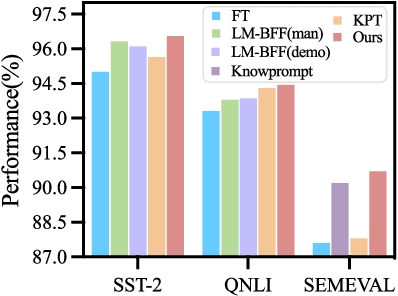
The pre-trained foundation models (PFMs) have become essential for facilitating large-scale multimodal learning. Researchers have effectively employed the ``pre-train, prompt, and predict'' paradigm through prompt learning to induce improved few-shot performance. However, prompt learning approaches for PFMs still follow a parametric learning paradigm. As such, the stability of generalization in memorization and rote learning can be compromised. More specifically, conventional prompt learning might face difficulties in fully utilizing atypical instances and avoiding overfitting to shallow patterns with limited data during the process of fully-supervised training. To overcome these constraints, we present our approach, named RetroPrompt, which aims to achieve a balance between memorization and generalization by decoupling knowledge from mere memorization. Unlike traditional prompting methods, RetroPrompt leverages a publicly accessible knowledge base generated from the training data and incorporates a retrieval mechanism throughout the input, training, and inference stages. This enables the model to actively retrieve relevant contextual information from the corpus, thereby enhancing the available cues. We conduct comprehensive experiments on a variety of datasets across natural language processing and computer vision tasks to demonstrate the superior performance of our proposed approach, RetroPrompt, in both zero-shot and few-shot scenarios. Through detailed analysis of memorization patterns, we observe that RetroPrompt effectively reduces the reliance on rote memorization, leading to enhanced generalization.
LightMem: Lightweight and Efficient Memory-Augmented Generation
Oct 21, 2025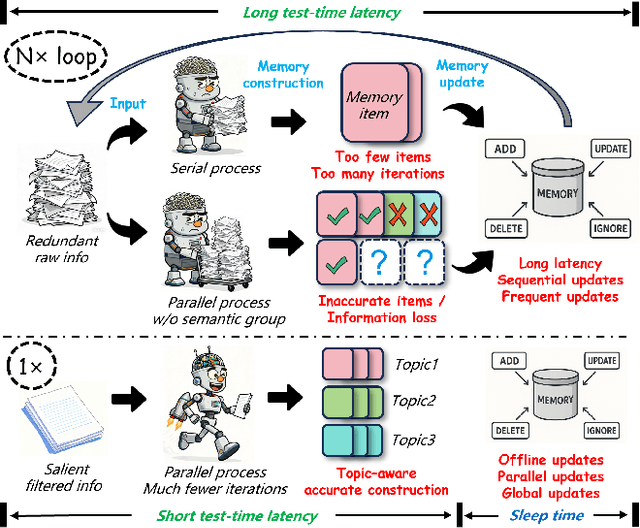
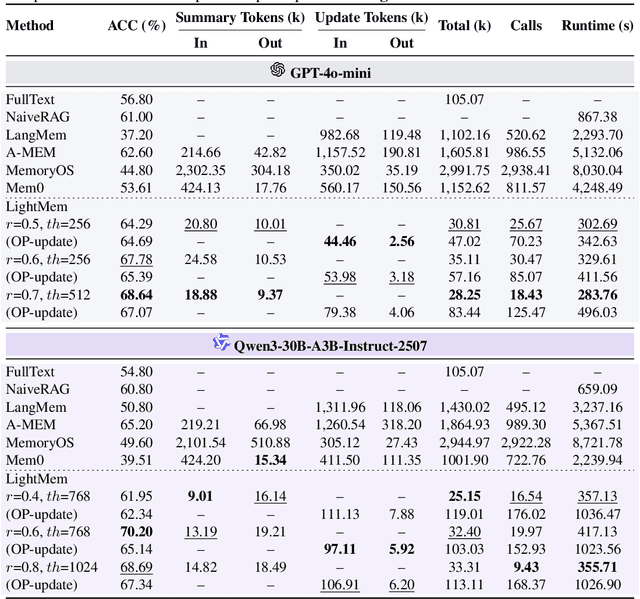
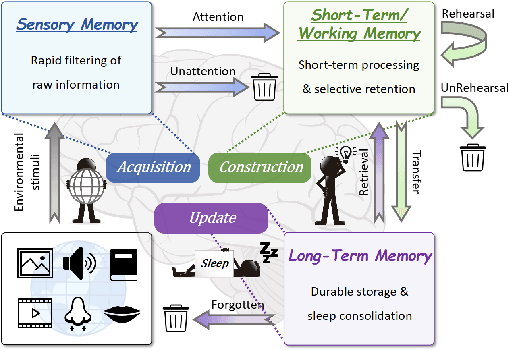
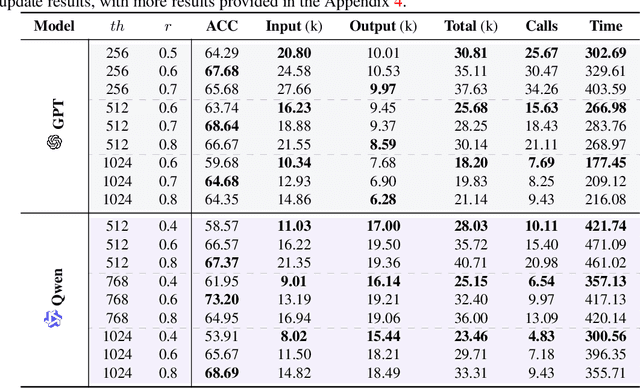
Despite their remarkable capabilities, Large Language Models (LLMs) struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
OceanGym: A Benchmark Environment for Underwater Embodied Agents
Sep 30, 2025We introduce OceanGym, the first comprehensive benchmark for ocean underwater embodied agents, designed to advance AI in one of the most demanding real-world environments. Unlike terrestrial or aerial domains, underwater settings present extreme perceptual and decision-making challenges, including low visibility, dynamic ocean currents, making effective agent deployment exceptionally difficult. OceanGym encompasses eight realistic task domains and a unified agent framework driven by Multi-modal Large Language Models (MLLMs), which integrates perception, memory, and sequential decision-making. Agents are required to comprehend optical and sonar data, autonomously explore complex environments, and accomplish long-horizon objectives under these harsh conditions. Extensive experiments reveal substantial gaps between state-of-the-art MLLM-driven agents and human experts, highlighting the persistent difficulty of perception, planning, and adaptability in ocean underwater environments. By providing a high-fidelity, rigorously designed platform, OceanGym establishes a testbed for developing robust embodied AI and transferring these capabilities to real-world autonomous ocean underwater vehicles, marking a decisive step toward intelligent agents capable of operating in one of Earth's last unexplored frontiers. The code and data are available at https://github.com/OceanGPT/OceanGym.
Tailored Teaching with Balanced Difficulty: Elevating Reasoning in Multimodal Chain-of-Thought via Prompt Curriculum
Aug 26, 2025The effectiveness of Multimodal Chain-of-Thought (MCoT) prompting is often limited by the use of randomly or manually selected examples. These examples fail to account for both model-specific knowledge distributions and the intrinsic complexity of the tasks, resulting in suboptimal and unstable model performance. To address this, we propose a novel framework inspired by the pedagogical principle of "tailored teaching with balanced difficulty". We reframe prompt selection as a prompt curriculum design problem: constructing a well ordered set of training examples that align with the model's current capabilities. Our approach integrates two complementary signals: (1) model-perceived difficulty, quantified through prediction disagreement in an active learning setup, capturing what the model itself finds challenging; and (2) intrinsic sample complexity, which measures the inherent difficulty of each question-image pair independently of any model. By jointly analyzing these signals, we develop a difficulty-balanced sampling strategy that ensures the selected prompt examples are diverse across both dimensions. Extensive experiments conducted on five challenging benchmarks and multiple popular Multimodal Large Language Models (MLLMs) demonstrate that our method yields substantial and consistent improvements and greatly reduces performance discrepancies caused by random sampling, providing a principled and robust approach for enhancing multimodal reasoning.
Decoupled Functional Evaluation of Autonomous Driving Models via Feature Map Quality Scoring
Aug 12, 2025End-to-end models are emerging as the mainstream in autonomous driving perception and planning. However, the lack of explicit supervision signals for intermediate functional modules leads to opaque operational mechanisms and limited interpretability, making it challenging for traditional methods to independently evaluate and train these modules. Pioneering in the issue, this study builds upon the feature map-truth representation similarity-based evaluation framework and proposes an independent evaluation method based on Feature Map Convergence Score (FMCS). A Dual-Granularity Dynamic Weighted Scoring System (DG-DWSS) is constructed, formulating a unified quantitative metric - Feature Map Quality Score - to enable comprehensive evaluation of the quality of feature maps generated by functional modules. A CLIP-based Feature Map Quality Evaluation Network (CLIP-FMQE-Net) is further developed, combining feature-truth encoders and quality score prediction heads to enable real-time quality analysis of feature maps generated by functional modules. Experimental results on the NuScenes dataset demonstrate that integrating our evaluation module into the training improves 3D object detection performance, achieving a 3.89 percent gain in NDS. These results verify the effectiveness of our method in enhancing feature representation quality and overall model performance.
Memp: Exploring Agent Procedural Memory
Aug 08, 2025Large Language Models (LLMs) based agents excel at diverse tasks, yet they suffer from brittle procedural memory that is manually engineered or entangled in static parameters. In this work, we investigate strategies to endow agents with a learnable, updatable, and lifelong procedural memory. We propose Memp that distills past agent trajectories into both fine-grained, step-by-step instructions and higher-level, script-like abstractions, and explore the impact of different strategies for Build, Retrieval, and Update of procedural memory. Coupled with a dynamic regimen that continuously updates, corrects, and deprecates its contents, this repository evolves in lockstep with new experience. Empirical evaluation on TravelPlanner and ALFWorld shows that as the memory repository is refined, agents achieve steadily higher success rates and greater efficiency on analogous tasks. Moreover, procedural memory built from a stronger model retains its value: migrating the procedural memory to a weaker model yields substantial performance gains.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025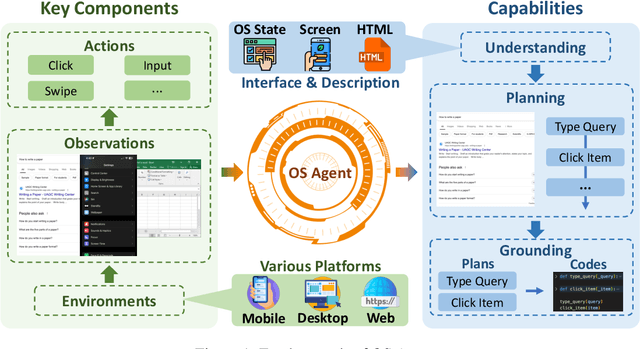
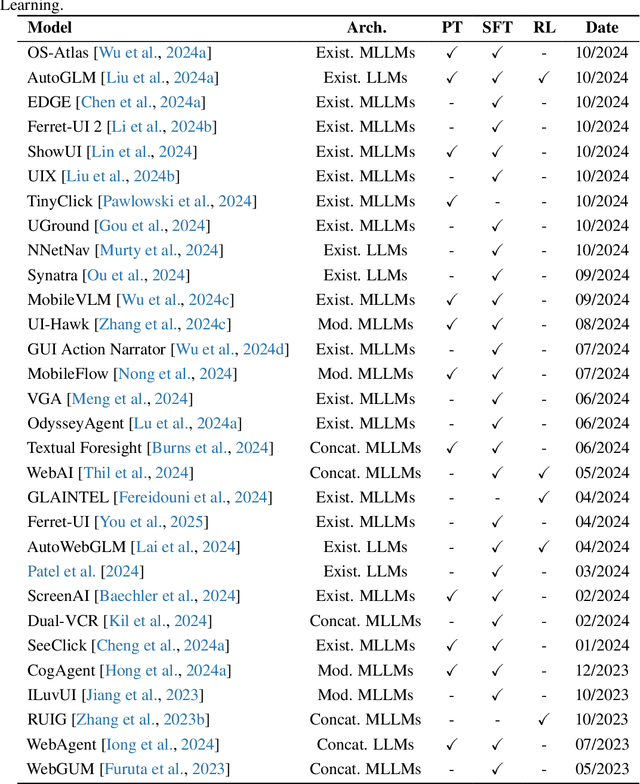
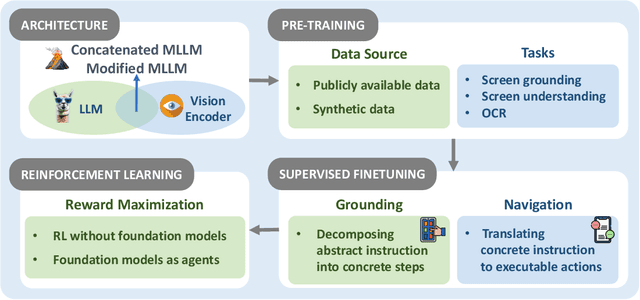
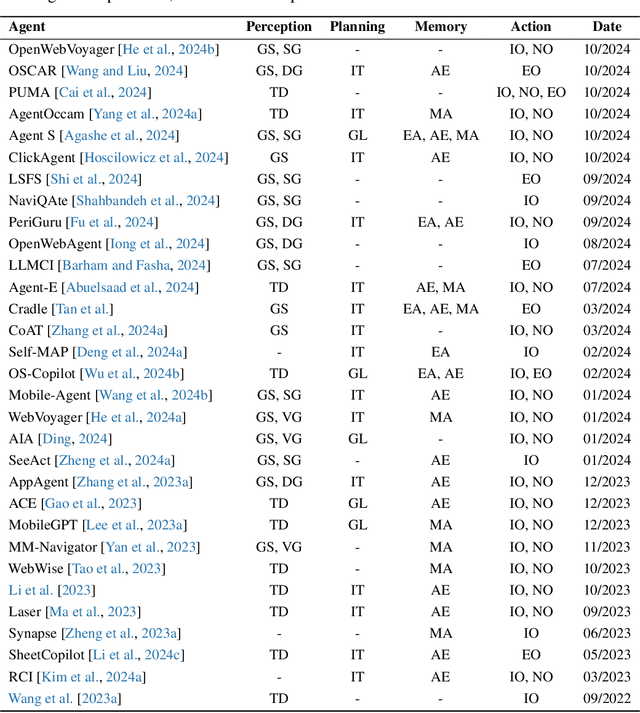
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality
Jun 24, 2025



Large Language Models (LLMs), particularly slow-thinking models, often exhibit severe hallucination, outputting incorrect content due to an inability to accurately recognize knowledge boundaries during reasoning. While Reinforcement Learning (RL) can enhance complex reasoning abilities, its outcome-oriented reward mechanism often lacks factual supervision over the thinking process, further exacerbating the hallucination problem. To address the high hallucination in slow-thinking models, we propose Knowledge-enhanced RL, KnowRL. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. This targeted factual input during RL training enables the model to learn and internalize fact-based reasoning strategies. By directly rewarding adherence to facts within the reasoning steps, KnowRL fosters a more reliable thinking process. Experimental results on three hallucination evaluation datasets and two reasoning evaluation datasets demonstrate that KnowRL effectively mitigates hallucinations in slow-thinking models while maintaining their original strong reasoning capabilities. Our code is available at https://github.com/zjunlp/KnowRL.