 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-augmented Prompt Learning for Pre-trained Foundation Models
Dec 23, 2025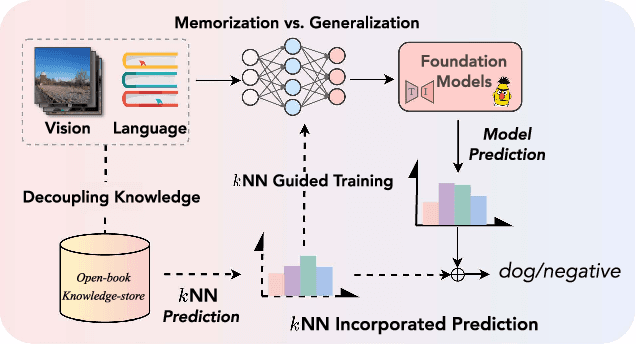
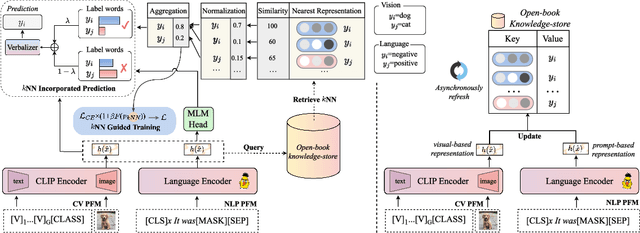
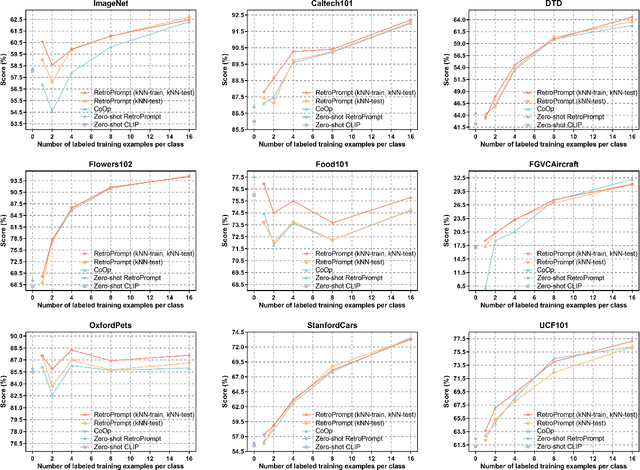
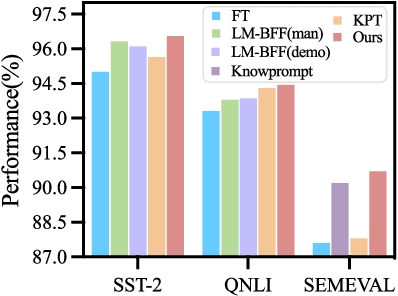
The pre-trained foundation models (PFMs) have become essential for facilitating large-scale multimodal learning. Researchers have effectively employed the ``pre-train, prompt, and predict'' paradigm through prompt learning to induce improved few-shot performance. However, prompt learning approaches for PFMs still follow a parametric learning paradigm. As such, the stability of generalization in memorization and rote learning can be compromised. More specifically, conventional prompt learning might face difficulties in fully utilizing atypical instances and avoiding overfitting to shallow patterns with limited data during the process of fully-supervised training. To overcome these constraints, we present our approach, named RetroPrompt, which aims to achieve a balance between memorization and generalization by decoupling knowledge from mere memorization. Unlike traditional prompting methods, RetroPrompt leverages a publicly accessible knowledge base generated from the training data and incorporates a retrieval mechanism throughout the input, training, and inference stages. This enables the model to actively retrieve relevant contextual information from the corpus, thereby enhancing the available cues. We conduct comprehensive experiments on a variety of datasets across natural language processing and computer vision tasks to demonstrate the superior performance of our proposed approach, RetroPrompt, in both zero-shot and few-shot scenarios. Through detailed analysis of memorization patterns, we observe that RetroPrompt effectively reduces the reliance on rote memorization, leading to enhanced generalization.
AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
Jun 12, 2025Large Language Model (LLM) agents have shown great potential in addressing real-world data science problems. LLM-driven data science agents promise to automate the entire machine learning pipeline, yet their real-world effectiveness remains limited. Existing frameworks depend on rigid, pre-defined workflows and inflexible coding strategies; consequently, they excel only on relatively simple, classical problems and fail to capture the empirical expertise that human practitioners bring to complex, innovative tasks. In this work, we introduce AutoMind, an adaptive, knowledgeable LLM-agent framework that overcomes these deficiencies through three key advances: (1) a curated expert knowledge base that grounds the agent in domain expert knowledge, (2) an agentic knowledgeable tree search algorithm that strategically explores possible solutions, and (3) a self-adaptive coding strategy that dynamically tailors code generation to task complexity. Evaluations on two automated data science benchmarks demonstrate that AutoMind delivers superior performance versus state-of-the-art baselines. Additional analyses confirm favorable effectiveness, efficiency, and qualitative solution quality, highlighting AutoMind as an efficient and robust step toward fully automated data science.
Symbolic Learning Enables Self-Evolving Agents
Jun 26, 2024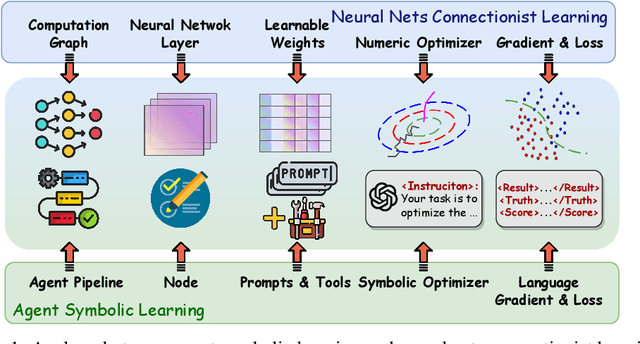
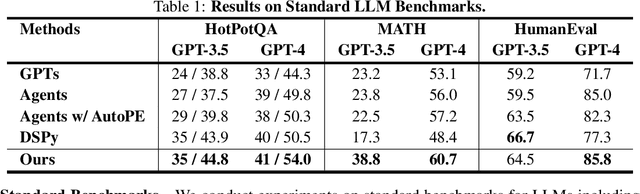
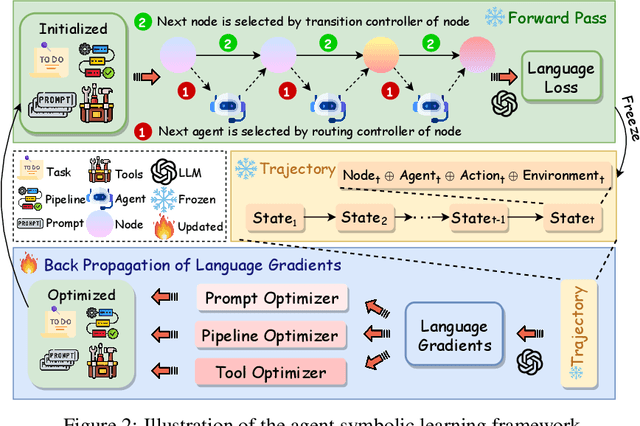
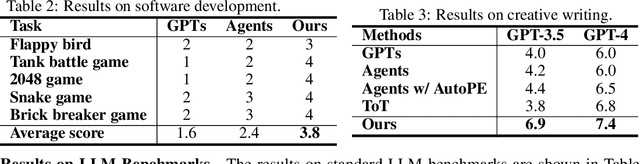
The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing "language agents", which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in "self-evolving agents".
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
Mar 05, 2024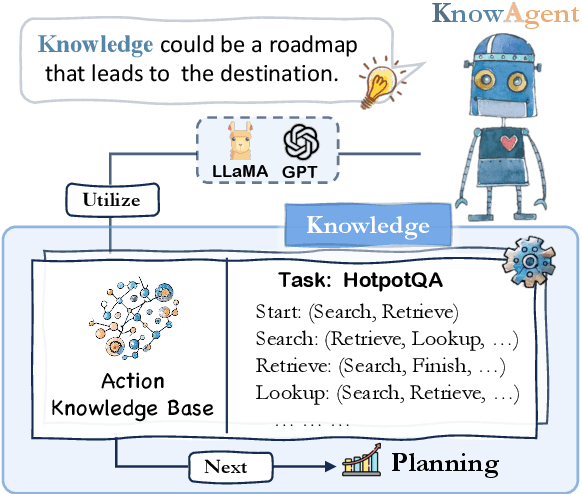
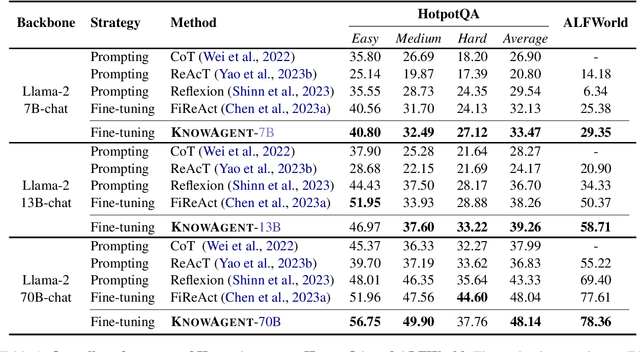
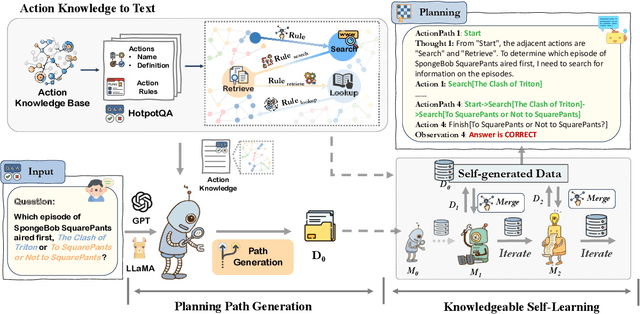

Large Language Models (LLMs) have demonstrated great potential in complex reasoning tasks, yet they fall short when tackling more sophisticated challenges, especially when interacting with environments through generating executable actions. This inadequacy primarily stems from the lack of built-in action knowledge in language agents, which fails to effectively guide the planning trajectories during task solving and results in planning hallucination. To address this issue, we introduce KnowAgent, a novel approach designed to enhance the planning capabilities of LLMs by incorporating explicit action knowledge. Specifically, KnowAgent employs an action knowledge base and a knowledgeable self-learning strategy to constrain the action path during planning, enabling more reasonable trajectory synthesis, and thereby enhancing the planning performance of language agents. Experimental results on HotpotQA and ALFWorld based on various backbone models demonstrate that KnowAgent can achieve comparable or superior performance to existing baselines. Further analysis indicates the effectiveness of KnowAgent in terms of planning hallucinations mitigation. Code is available in https://github.com/zjunlp/KnowAgent.
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models
Feb 06, 2024



In recent years, instruction tuning has gained increasing attention and emerged as a crucial technique to enhance the capabilities of Large Language Models (LLMs). To construct high-quality instruction datasets, many instruction processing approaches have been proposed, aiming to achieve a delicate balance between data quantity and data quality. Nevertheless, due to inconsistencies that persist among various instruction processing methods, there is no standard open-source instruction processing implementation framework available for the community, which hinders practitioners from further developing and advancing. To facilitate instruction processing research and development, we present EasyInstruct, an easy-to-use instruction processing framework for LLMs, which modularizes instruction generation, selection, and prompting, while also considering their combination and interaction. EasyInstruct is publicly released and actively maintained at https://github.com/zjunlp/EasyInstruct, along with a running demo App at https://huggingface.co/spaces/zjunlp/EasyInstruct for quick-start, calling for broader research centered on instruction data.
OceanGPT: A Large Language Model for Ocean Science Tasks
Oct 19, 2023
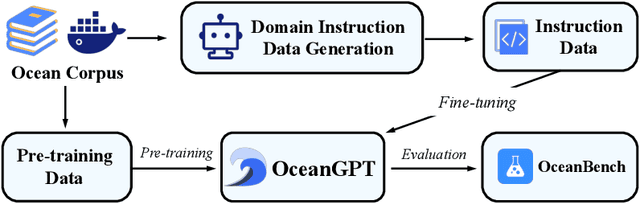

Ocean science, which delves into the oceans that are reservoirs of life and biodiversity, is of great significance given that oceans cover over 70% of our planet's surface. Recently, advances in Large Language Models (LLMs) have transformed the paradigm in science. Despite the success in other domains, current LLMs often fall short in catering to the needs of domain experts like oceanographers, and the potential of LLMs for ocean science is under-explored. The intrinsic reason may be the immense and intricate nature of ocean data as well as the necessity for higher granularity and richness in knowledge. To alleviate these issues, we introduce OceanGPT, the first-ever LLM in the ocean domain, which is expert in various ocean science tasks. We propose DoInstruct, a novel framework to automatically obtain a large volume of ocean domain instruction data, which generates instructions based on multi-agent collaboration. Additionally, we construct the first oceanography benchmark, OceanBench, to evaluate the capabilities of LLMs in the ocean domain. Though comprehensive experiments, OceanGPT not only shows a higher level of knowledge expertise for oceans science tasks but also gains preliminary embodied intelligence capabilities in ocean technology. Codes, data and checkpoints will soon be available at https://github.com/zjunlp/KnowLM.
Layout and Task Aware Instruction Prompt for Zero-shot Document Image Question Answering
Jun 01, 2023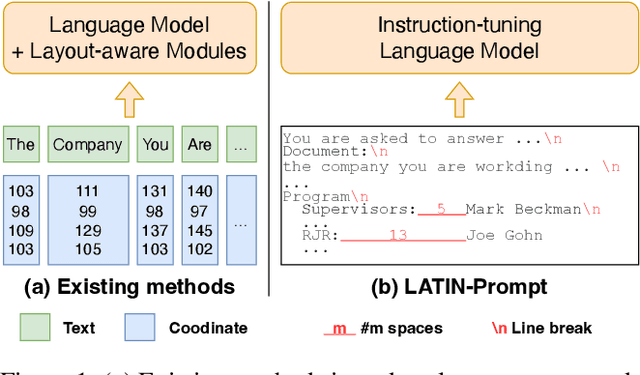

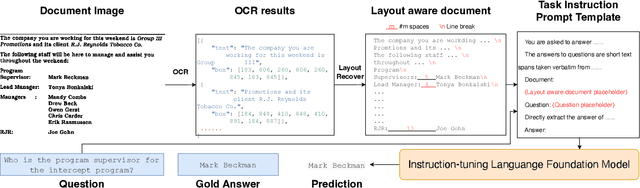
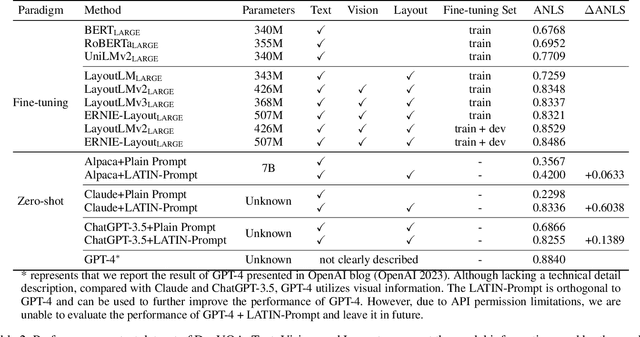
The pre-training-fine-tuning paradigm based on layout-aware multimodal pre-trained models has achieved significant progress on document image question answering. However, domain pre-training and task fine-tuning for additional visual, layout, and task modules prevent them from directly utilizing off-the-shelf instruction-tuning language foundation models, which have recently shown promising potential in zero-shot learning. Contrary to aligning language models to the domain of document image question answering, we align document image question answering to off-the-shell instruction-tuning language foundation models to utilize their zero-shot capability. Specifically, we propose layout and task aware instruction prompt called LATIN-Prompt, which consists of layout-aware document content and task-aware descriptions. The former recovers the layout information among text segments from OCR tools by appropriate spaces and line breaks. The latter ensures that the model generates answers that meet the requirements, especially format requirements, through a detailed description of task. Experimental results on three benchmarks show that LATIN-Prompt can improve the zero-shot performance of instruction-tuning language foundation models on document image question answering and help them achieve comparable levels to SOTAs based on the pre-training-fine-tuning paradigm. Quantitative analysis and qualitative analysis demonstrate the effectiveness of LATIN-Prompt. We provide the code in supplementary and will release the code to facilitate future research.
LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities
May 22, 2023This paper presents an exhaustive quantitative and qualitative evaluation of Large Language Models (LLMs) for Knowledge Graph (KG) construction and reasoning. We employ eight distinct datasets that encompass aspects including entity, relation and event extraction, link prediction, and question answering. Empirically, our findings suggest that GPT-4 outperforms ChatGPT in the majority of tasks and even surpasses fine-tuned models in certain reasoning and question-answering datasets. Moreover, our investigation extends to the potential generalization ability of LLMs for information extraction, which culminates in the presentation of the Virtual Knowledge Extraction task and the development of the VINE dataset. Drawing on these empirical findings, we further propose AutoKG, a multi-agent-based approach employing LLMs for KG construction and reasoning, which aims to chart the future of this field and offer exciting opportunities for advancement. We anticipate that our research can provide invaluable insights for future undertakings of KG\footnote{Code and datasets will be available in https://github.com/zjunlp/AutoKG.
A Concept Knowledge Graph for User Next Intent Prediction at Alipay
Jan 02, 2023



This paper illustrates the technologies of user next intent prediction with a concept knowledge graph. The system has been deployed on the Web at Alipay, serving more than 100 million daily active users. Specifically, we propose AlipayKG to explicitly characterize user intent, which is an offline concept knowledge graph in the Life-Service domain modeling the historical behaviors of users, the rich content interacted by users and the relations between them. We further introduce a Transformer-based model which integrates expert rules from the knowledge graph to infer the online user's next intent. Experimental results demonstrate that the proposed system can effectively enhance the performance of the downstream tasks while retaining explainability.
Reasoning with Language Model Prompting: A Survey
Dec 19, 2022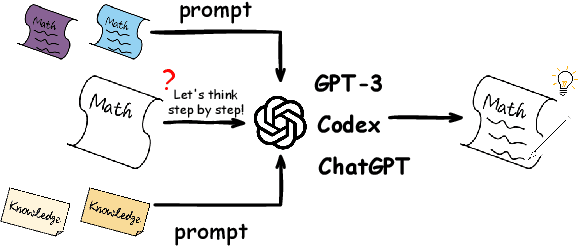
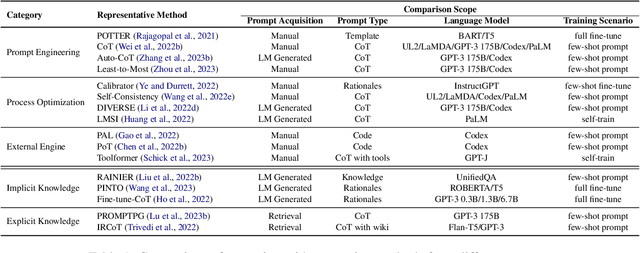

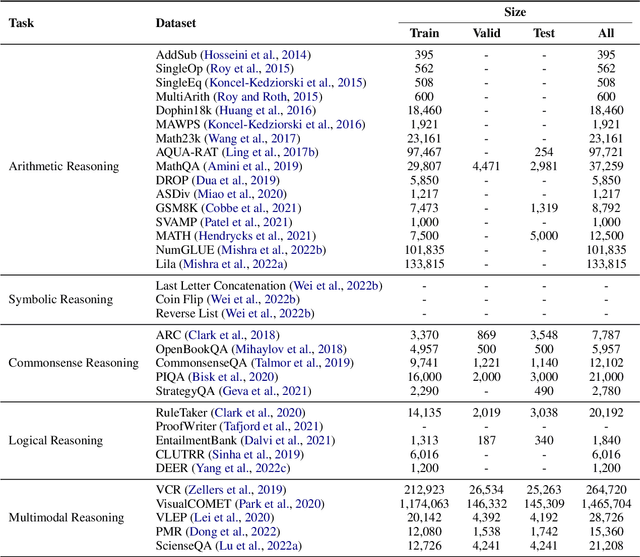
Reasoning, as an essential ability for complex problem-solving, can provide back-end support for various real-world applications, such as medical diagnosis, negotiation, etc. This paper provides a comprehensive survey of cutting-edge research on reasoning with language model prompting. We introduce research works with comparisons and summaries and provide systematic resources to help beginners. We also discuss the potential reasons for emerging such reasoning abilities and highlight future research directions.