 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Superficial Unlearning: Sharpness-Aware Robust Erasure of Hallucinations in Multimodal LLMs
Jan 23, 2026Multimodal LLMs are powerful but prone to object hallucinations, which describe non-existent entities and harm reliability. While recent unlearning methods attempt to mitigate this, we identify a critical flaw: structural fragility. We empirically demonstrate that standard erasure achieves only superficial suppression, trapping the model in sharp minima where hallucinations catastrophically resurge after lightweight relearning. To ensure geometric stability, we propose SARE, which casts unlearning as a targeted min-max optimization problem and uses a Targeted-SAM mechanism to explicitly flatten the loss landscape around hallucinated concepts. By suppressing hallucinations under simulated worst-case parameter perturbations, our framework ensures robust removal stable against weight shifts. Extensive experiments demonstrate that SARE significantly outperforms baselines in erasure efficacy while preserving general generation quality. Crucially, it maintains persistent hallucination suppression against relearning and parameter updates, validating the effectiveness of geometric stabilization.
Your One-Stop Solution for AI-Generated Video Detection
Jan 16, 2026Recent advances in generative modeling can create remarkably realistic synthetic videos, making it increasingly difficult for humans to distinguish them from real ones and necessitating reliable detection methods. However, two key limitations hinder the development of this field. \textbf{From the dataset perspective}, existing datasets are often limited in scale and constructed using outdated or narrowly scoped generative models, making it difficult to capture the diversity and rapid evolution of modern generative techniques. Moreover, the dataset construction process frequently prioritizes quantity over quality, neglecting essential aspects such as semantic diversity, scenario coverage, and technological representativeness. \textbf{From the benchmark perspective}, current benchmarks largely remain at the stage of dataset creation, leaving many fundamental issues and in-depth analysis yet to be systematically explored. Addressing this gap, we propose AIGVDBench, a benchmark designed to be comprehensive and representative, covering \textbf{31} state-of-the-art generation models and over \textbf{440,000} videos. By executing more than \textbf{1,500} evaluations on \textbf{33} existing detectors belonging to four distinct categories. This work presents \textbf{8 in-depth analyses} from multiple perspectives and identifies \textbf{4 novel findings} that offer valuable insights for future research. We hope this work provides a solid foundation for advancing the field of AI-generated video detection. Our benchmark is open-sourced at https://github.com/LongMa-2025/AIGVDBench.
Thought Purity: Defense Paradigm For Chain-of-Thought Attack
Jul 16, 2025While reinforcement learning-trained Large Reasoning Models (LRMs, e.g., Deepseek-R1) demonstrate advanced reasoning capabilities in the evolving Large Language Models (LLMs) domain, their susceptibility to security threats remains a critical vulnerability. This weakness is particularly evident in Chain-of-Thought (CoT) generation processes, where adversarial methods like backdoor prompt attacks can systematically subvert the model's core reasoning mechanisms. The emerging Chain-of-Thought Attack (CoTA) reveals this vulnerability through exploiting prompt controllability, simultaneously degrading both CoT safety and task performance with low-cost interventions. To address this compounded security-performance vulnerability, we propose Thought Purity (TP): a defense paradigm that systematically strengthens resistance to malicious content while preserving operational efficacy. Our solution achieves this through three synergistic components: (1) a safety-optimized data processing pipeline (2) reinforcement learning-enhanced rule constraints (3) adaptive monitoring metrics. Our approach establishes the first comprehensive defense mechanism against CoTA vulnerabilities in reinforcement learning-aligned reasoning systems, significantly advancing the security-functionality equilibrium for next-generation AI architectures.
Spatial Knowledge Graph-Guided Multimodal Synthesis
May 28, 2025Recent advances in multimodal large language models (MLLMs) have significantly enhanced their capabilities; however, their spatial perception abilities remain a notable limitation. To address this challenge, multimodal data synthesis offers a promising solution. Yet, ensuring that synthesized data adhere to spatial common sense is a non-trivial task. In this work, we introduce SKG2Data, a novel multimodal synthesis approach guided by spatial knowledge graphs, grounded in the concept of knowledge-to-data generation. SKG2Data automatically constructs a Spatial Knowledge Graph (SKG) to emulate human-like perception of spatial directions and distances, which is subsequently utilized to guide multimodal data synthesis. Extensive experiments demonstrate that data synthesized from diverse types of spatial knowledge, including direction and distance, not only enhance the spatial perception and reasoning abilities of MLLMs but also exhibit strong generalization capabilities. We hope that the idea of knowledge-based data synthesis can advance the development of spatial intelligence.
EasyInstruct: An Easy-to-use Instruction Processing Framework for Large Language Models
Feb 06, 2024



In recent years, instruction tuning has gained increasing attention and emerged as a crucial technique to enhance the capabilities of Large Language Models (LLMs). To construct high-quality instruction datasets, many instruction processing approaches have been proposed, aiming to achieve a delicate balance between data quantity and data quality. Nevertheless, due to inconsistencies that persist among various instruction processing methods, there is no standard open-source instruction processing implementation framework available for the community, which hinders practitioners from further developing and advancing. To facilitate instruction processing research and development, we present EasyInstruct, an easy-to-use instruction processing framework for LLMs, which modularizes instruction generation, selection, and prompting, while also considering their combination and interaction. EasyInstruct is publicly released and actively maintained at https://github.com/zjunlp/EasyInstruct, along with a running demo App at https://huggingface.co/spaces/zjunlp/EasyInstruct for quick-start, calling for broader research centered on instruction data.
OceanGPT: A Large Language Model for Ocean Science Tasks
Oct 19, 2023
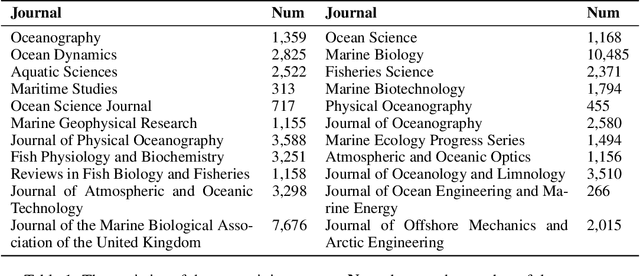
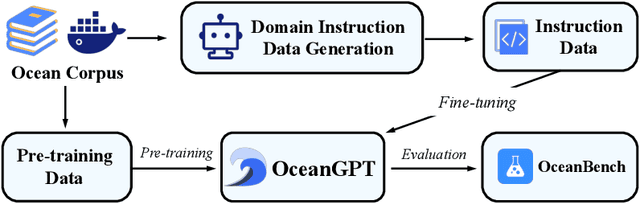

Ocean science, which delves into the oceans that are reservoirs of life and biodiversity, is of great significance given that oceans cover over 70% of our planet's surface. Recently, advances in Large Language Models (LLMs) have transformed the paradigm in science. Despite the success in other domains, current LLMs often fall short in catering to the needs of domain experts like oceanographers, and the potential of LLMs for ocean science is under-explored. The intrinsic reason may be the immense and intricate nature of ocean data as well as the necessity for higher granularity and richness in knowledge. To alleviate these issues, we introduce OceanGPT, the first-ever LLM in the ocean domain, which is expert in various ocean science tasks. We propose DoInstruct, a novel framework to automatically obtain a large volume of ocean domain instruction data, which generates instructions based on multi-agent collaboration. Additionally, we construct the first oceanography benchmark, OceanBench, to evaluate the capabilities of LLMs in the ocean domain. Though comprehensive experiments, OceanGPT not only shows a higher level of knowledge expertise for oceans science tasks but also gains preliminary embodied intelligence capabilities in ocean technology. Codes, data and checkpoints will soon be available at https://github.com/zjunlp/KnowLM.
When Do Program-of-Thoughts Work for Reasoning?
Sep 08, 2023The reasoning capabilities of Large Language Models (LLMs) play a pivotal role in the realm of embodied artificial intelligence. Although there are effective methods like program-of-thought prompting for LLMs which uses programming language to tackle complex reasoning tasks, the specific impact of code data on the improvement of reasoning capabilities remains under-explored. To address this gap, we propose complexity-impacted reasoning score (CIRS), which combines structural and logical attributes, to measure the correlation between code and reasoning abilities. Specifically, we use the abstract syntax tree to encode the structural information and calculate logical complexity by considering the difficulty and the cyclomatic complexity. Through an empirical analysis, we find not all code data of complexity can be learned or understood by LLMs. Optimal level of complexity is critical to the improvement of reasoning abilities by program-aided prompting. Then we design an auto-synthesizing and stratifying algorithm, and apply it to instruction generation for mathematical reasoning and code data filtering for code generation tasks. Extensive results demonstrates the effectiveness of our proposed approach. Code will be integrated into the EasyInstruct framework at https://github.com/zjunlp/EasyInstruct.
CodeKGC: Code Language Model for Generative Knowledge Graph Construction
Apr 18, 2023Current generative knowledge graph construction approaches usually fail to capture structural knowledge by simply flattening natural language into serialized texts or a specification language. However, large generative language model trained on structured data such as code has demonstrated impressive capability in understanding natural language for structural prediction and reasoning tasks. Intuitively, we address the task of generative knowledge graph construction with code language model: given a code-format natural language input, the target is to generate triples which can be represented as code completion tasks. Specifically, we develop schema-aware prompts that effectively utilize the semantic structure within the knowledge graph. As code inherently possesses structure, such as class and function definitions, it serves as a useful model for prior semantic structural knowledge. Furthermore, we employ a rationale-enhanced generation method to boost the performance. Rationales provide intermediate steps, thereby improving knowledge extraction abilities. Experimental results indicate that the proposed approach can obtain better performance on benchmark datasets compared with baselines. Code and datasets are available in https://github.com/zjunlp/DeepKE/tree/main/example/llm.
Tele-Knowledge Pre-training for Fault Analysis
Oct 20, 2022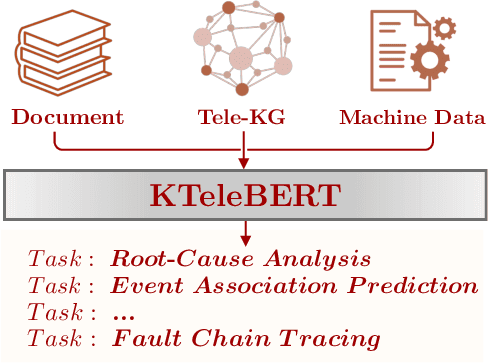
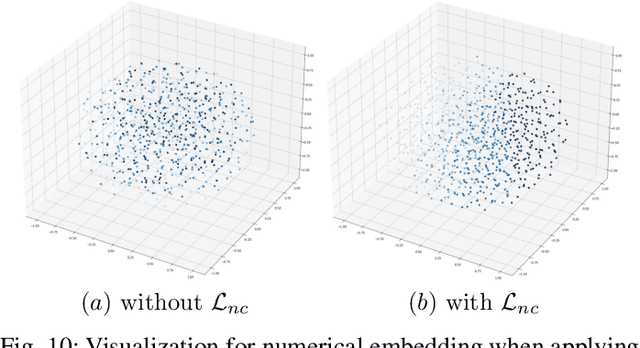


In this work, we share our experience on tele-knowledge pre-training for fault analysis. Fault analysis is a vital task for tele-application, which should be timely and properly handled. Fault analysis is also a complex task, that has many sub-tasks. Solving each task requires diverse tele-knowledge. Machine log data and product documents contain part of the tele-knowledge. We create a Tele-KG to organize other tele-knowledge from experts uniformly. With these valuable tele-knowledge data, in this work, we propose a tele-domain pre-training model KTeleBERT and its knowledge-enhanced version KTeleBERT, which includes effective prompt hints, adaptive numerical data encoding, and two knowledge injection paradigms. We train our model in two stages: pre-training TeleBERT on 20 million telecommunication corpora and re-training TeleBERT on 1 million causal and machine corpora to get the KTeleBERT. Then, we apply our models for three tasks of fault analysis, including root-cause analysis, event association prediction, and fault chain tracing. The results show that with KTeleBERT, the performance of task models has been boosted, demonstrating the effectiveness of pre-trained KTeleBERT as a model containing diverse tele-knowledge.
Relphormer: Relational Graph Transformer for Knowledge Graph Representation
May 24, 2022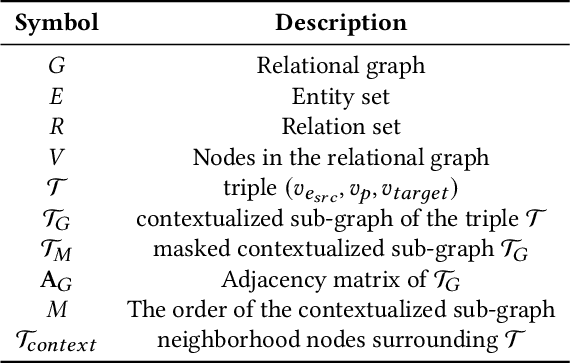
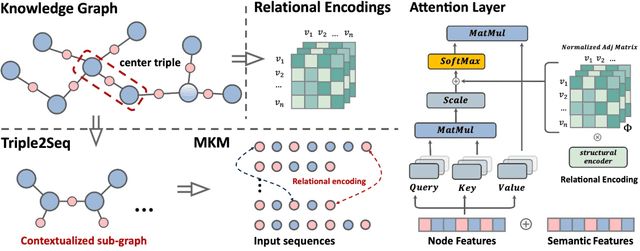
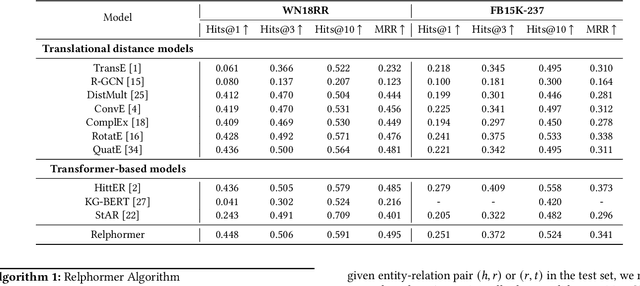
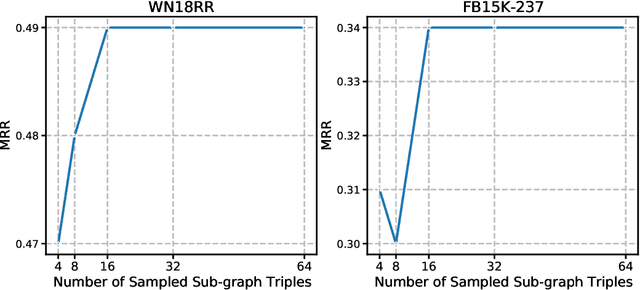
Transformers have achieved remarkable performance in widespread fields, including natural language processing, computer vision and graph mining. However, in the knowledge graph representation, where translational distance paradigm dominates this area, vanilla Transformer architectures have not yielded promising improvements. Note that vanilla Transformer architectures struggle to capture the intrinsically semantic and structural information of knowledge graphs and can hardly scale to long-distance neighbors due to quadratic dependency. To this end, we propose a new variant of Transformer for knowledge graph representation dubbed Relphormer. Specifically, we introduce Triple2Seq which can dynamically sample contextualized sub-graph sequences as the input of the Transformer to alleviate the scalability issue. We then propose a novel structure-enhanced self-attention mechanism to encode the relational information and keep the globally semantic information among sub-graphs. Moreover, we propose masked knowledge modeling as a new paradigm for knowledge graph representation learning to unify different link prediction tasks. Experimental results show that our approach can obtain better performance on benchmark datasets compared with baselines.