 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelphormer: Relational Graph Transformer for Knowledge Graph Representation
Paper and Code
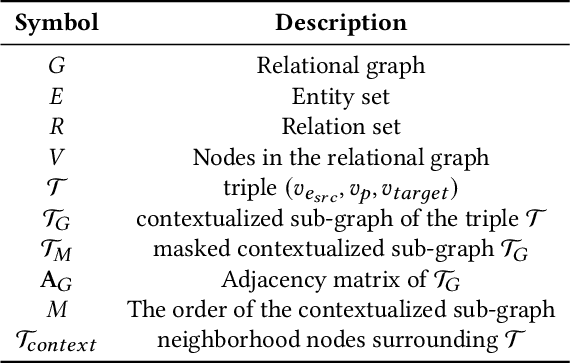
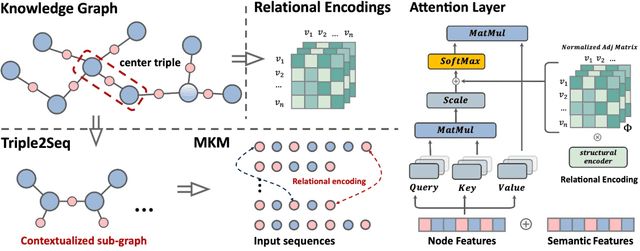
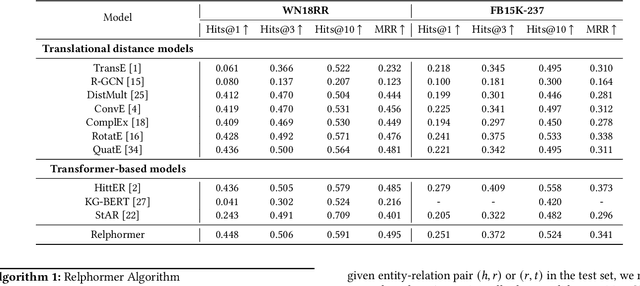
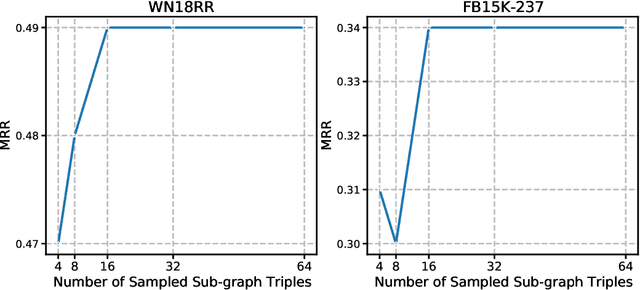
Transformers have achieved remarkable performance in widespread fields, including natural language processing, computer vision and graph mining. However, in the knowledge graph representation, where translational distance paradigm dominates this area, vanilla Transformer architectures have not yielded promising improvements. Note that vanilla Transformer architectures struggle to capture the intrinsically semantic and structural information of knowledge graphs and can hardly scale to long-distance neighbors due to quadratic dependency. To this end, we propose a new variant of Transformer for knowledge graph representation dubbed Relphormer. Specifically, we introduce Triple2Seq which can dynamically sample contextualized sub-graph sequences as the input of the Transformer to alleviate the scalability issue. We then propose a novel structure-enhanced self-attention mechanism to encode the relational information and keep the globally semantic information among sub-graphs. Moreover, we propose masked knowledge modeling as a new paradigm for knowledge graph representation learning to unify different link prediction tasks. Experimental results show that our approach can obtain better performance on benchmark datasets compared with baselines.