 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Knowledge Graph Representation Learning by Structure Contextual Pre-training
Paper and Code
Dec 08, 2021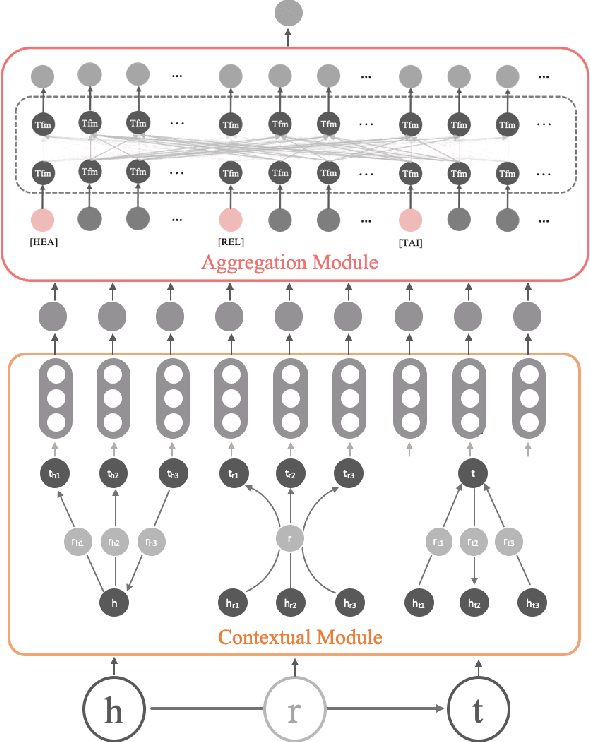
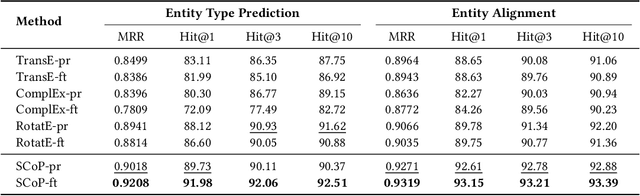
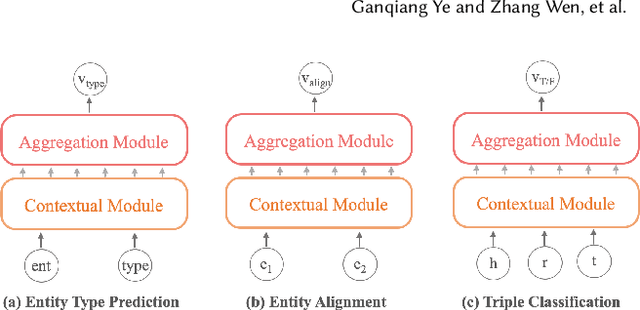
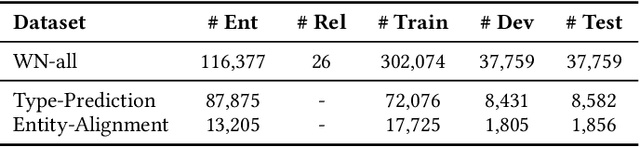
Representation learning models for Knowledge Graphs (KG) have proven to be effective in encoding structural information and performing reasoning over KGs. In this paper, we propose a novel pre-training-then-fine-tuning framework for knowledge graph representation learning, in which a KG model is firstly pre-trained with triple classification task, followed by discriminative fine-tuning on specific downstream tasks such as entity type prediction and entity alignment. Drawing on the general ideas of learning deep contextualized word representations in typical pre-trained language models, we propose SCoP to learn pre-trained KG representations with structural and contextual triples of the target triple encoded. Experimental results demonstrate that fine-tuning SCoP not only outperforms results of baselines on a portfolio of downstream tasks but also avoids tedious task-specific model design and parameter training.