 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Knowledge Graph Representation Learning by Structure Contextual Pre-training
Dec 08, 2021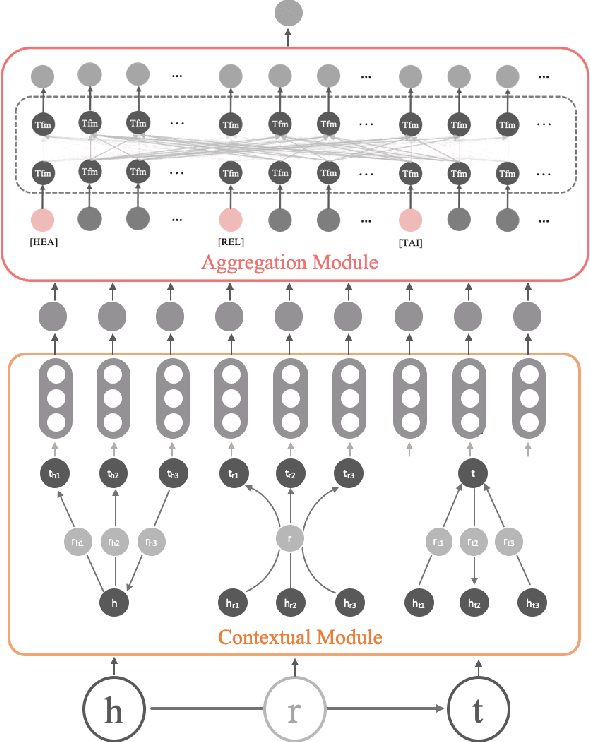
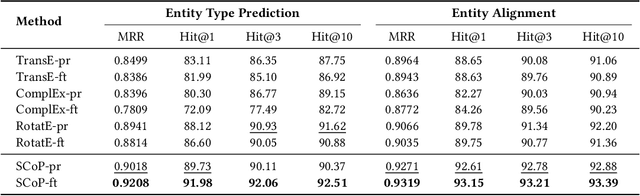
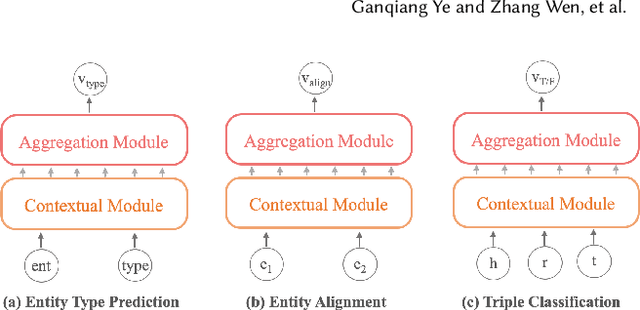
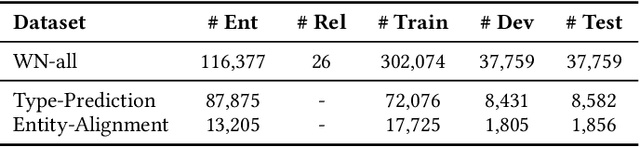
Representation learning models for Knowledge Graphs (KG) have proven to be effective in encoding structural information and performing reasoning over KGs. In this paper, we propose a novel pre-training-then-fine-tuning framework for knowledge graph representation learning, in which a KG model is firstly pre-trained with triple classification task, followed by discriminative fine-tuning on specific downstream tasks such as entity type prediction and entity alignment. Drawing on the general ideas of learning deep contextualized word representations in typical pre-trained language models, we propose SCoP to learn pre-trained KG representations with structural and contextual triples of the target triple encoded. Experimental results demonstrate that fine-tuning SCoP not only outperforms results of baselines on a portfolio of downstream tasks but also avoids tedious task-specific model design and parameter training.
Knowledge Perceived Multi-modal Pretraining in E-commerce
Aug 20, 2021

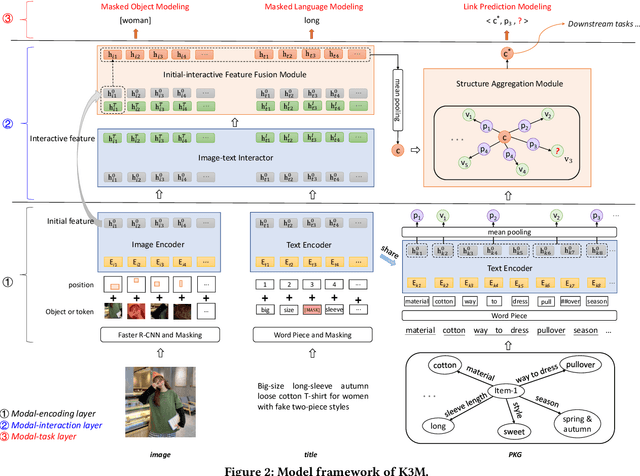
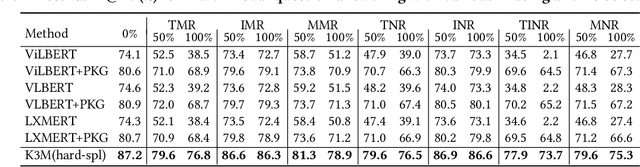
In this paper, we address multi-modal pretraining of product data in the field of E-commerce. Current multi-modal pretraining methods proposed for image and text modalities lack robustness in the face of modality-missing and modality-noise, which are two pervasive problems of multi-modal product data in real E-commerce scenarios. To this end, we propose a novel method, K3M, which introduces knowledge modality in multi-modal pretraining to correct the noise and supplement the missing of image and text modalities. The modal-encoding layer extracts the features of each modality. The modal-interaction layer is capable of effectively modeling the interaction of multiple modalities, where an initial-interactive feature fusion model is designed to maintain the independence of image modality and text modality, and a structure aggregation module is designed to fuse the information of image, text, and knowledge modalities. We pretrain K3M with three pretraining tasks, including masked object modeling (MOM), masked language modeling (MLM), and link prediction modeling (LPM). Experimental results on a real-world E-commerce dataset and a series of product-based downstream tasks demonstrate that K3M achieves significant improvements in performances than the baseline and state-of-the-art methods when modality-noise or modality-missing exists.
Billion-scale Pre-trained E-commerce Product Knowledge Graph Model
May 02, 2021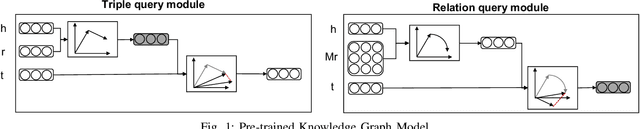
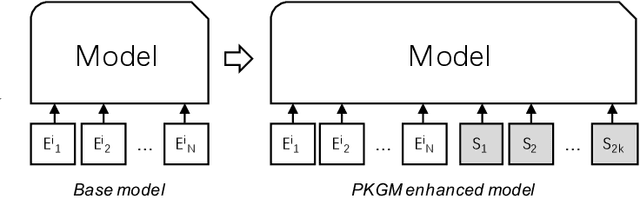
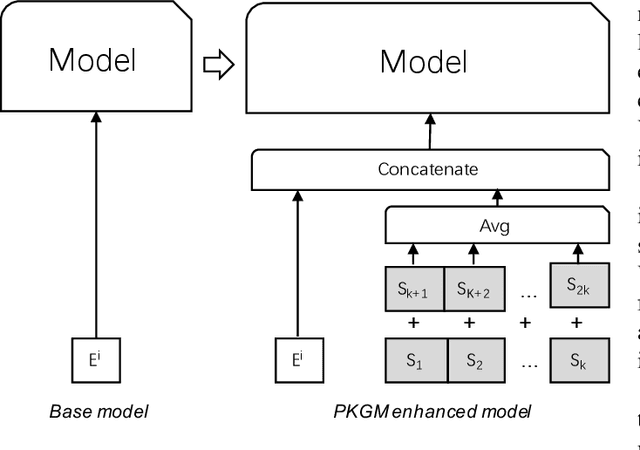
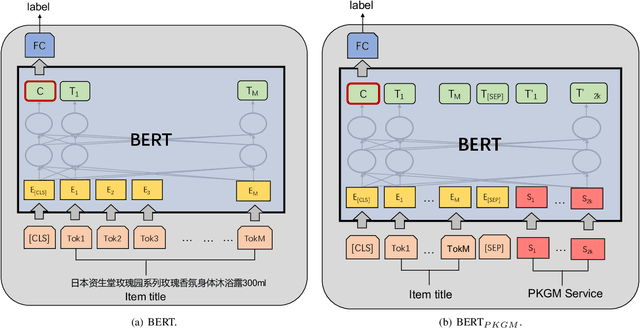
In recent years, knowledge graphs have been widely applied to organize data in a uniform way and enhance many tasks that require knowledge, for example, online shopping which has greatly facilitated people's life. As a backbone for online shopping platforms, we built a billion-scale e-commerce product knowledge graph for various item knowledge services such as item recommendation. However, such knowledge services usually include tedious data selection and model design for knowledge infusion, which might bring inappropriate results. Thus, to avoid this problem, we propose a Pre-trained Knowledge Graph Model (PKGM) for our billion-scale e-commerce product knowledge graph, providing item knowledge services in a uniform way for embedding-based models without accessing triple data in the knowledge graph. Notably, PKGM could also complete knowledge graphs during servicing, thereby overcoming the common incompleteness issue in knowledge graphs. We test PKGM in three knowledge-related tasks including item classification, same item identification, and recommendation. Experimental results show PKGM successfully improves the performance of each task.
Interventional Aspect-Based Sentiment Analysis
Apr 20, 2021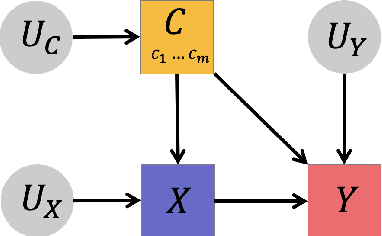

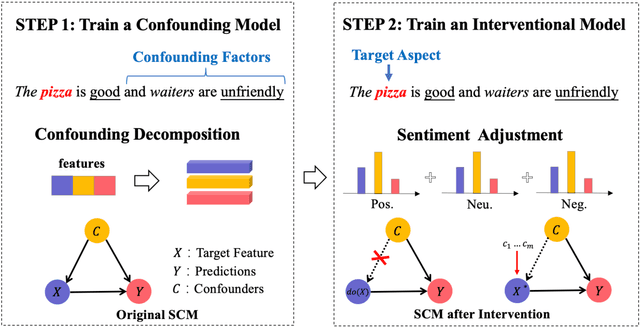
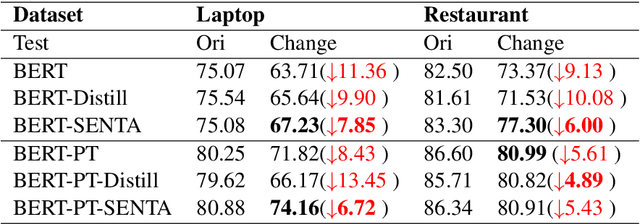
Recent neural-based aspect-based sentiment analysis approaches, though achieving promising improvement on benchmark datasets, have reported suffering from poor robustness when encountering confounder such as non-target aspects. In this paper, we take a causal view to addressing this issue. We propose a simple yet effective method, namely, Sentiment Adjustment (SENTA), by applying a backdoor adjustment to disentangle those confounding factors. Experimental results on the Aspect Robustness Test Set (ARTS) dataset demonstrate that our approach improves the performance while maintaining accuracy in the original test set.