 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower-based Partial Attention: Bridging Linear-Complexity and Full Attention
Jan 27, 2026It is widely accepted from transformer research that "attention is all we need", but the amount of attention required has never been systematically quantified. Is quadratic $O(L^2)$ attention necessary, or is there a sub-quadratic attention mechanism that can achieve comparable performance? To answer this question, we introduce power-based partial attention (PPA), an attention mechanism of order $O(L^{1+p})$, where $0 \leq p \leq 1$, such that $p=0$ corresponds to sliding window attention with linear complexity, and $p=1$ corresponds to full attention. With this attention construction, we can explore how transformer architecture performance varies as a function of the attention scaling behavior controlled by $p$. The overall trend from our experiments shows an S-curve-like behavior where the performance transitions from sliding-window (linear-complexity) attention to full attention over a narrow window of $p$ values, and plateaus as $p$ approaches $1$. In our experiments, we show that there exists $0<p<1$ such that $O(L^{1+p})$ attention is sufficient to achieve similar results as $O(L^2)$ full attention.
Superlinear Multi-Step Attention
Jan 26, 2026In this paper, we propose \textbf{Superlinear attention}, a fully trainable multi-step attention architecture that achieves subquadratic complexity for long sequences while preserving \textbf{random context access} (a.k.a.\ structural non-exclusion): no eligible token position is structurally excluded from being selected for attention. Superlinear attention reformulates standard causal self-attention as a multi-step search problem with $N$ steps, yielding an overall complexity of $O(L^{1+\frac{1}{N}})$. To illustrate the architecture, we present a baseline $N=2$ implementation, which is algorithmically analogous to standard jump search. In this $O(L^{3/2})$ instantiation, the first step performs $O(L^{3/2})$ span-search to select relevant spans of the sequence, and the second step applies $O(L^{3/2})$ span-attention (standard attention restricted to the selected spans). In an upscaled $O(L^{1.54})$ configuration for robustness, we achieve an average decoding throughput of 114 tokens/sec at 1M context length and 80 tokens/sec at 10M context in our implementation on a modified 30B hybrid MoE model on a single B200 GPU. With limited training, we also obtain strong performance on the NIAH (Needle In A Haystack) task up to 256K context length, demonstrating that the routed span selection is learnable end-to-end. This paper emphasizes architectural formulation, scaling analysis, and systems feasibility, and presents initial validation; comprehensive quality evaluations across diverse long-context tasks are left to future work.
Structure-CLIP: Enhance Multi-modal Language Representations with Structure Knowledge
May 06, 2023Large-scale vision-language pre-training has shown promising advances on various downstream tasks and achieved significant performance in multi-modal understanding and generation tasks. However, existing methods often perform poorly on image-text matching tasks that require a detailed semantics understanding of the text. Although there have been some works on this problem, they do not sufficiently exploit the structural knowledge present in sentences to enhance multi-modal language representations, which leads to poor performance. In this paper, we present an end-to-end framework Structure-CLIP, which integrates latent detailed semantics from the text to enhance fine-grained semantic representations. Specifically, (1) we use scene graphs in order to pay more attention to the detailed semantic learning in the text and fully explore structured knowledge between fine-grained semantics, and (2) we utilize the knowledge-enhanced framework with the help of the scene graph to make full use of representations of structured knowledge. To verify the effectiveness of our proposed method, we pre-trained our models with the aforementioned approach and conduct experiments on different downstream tasks. Numerical results show that Structure-CLIP can often achieve state-of-the-art performance on both VG-Attribution and VG-Relation datasets. Extensive experiments show its components are effective and its predictions are interpretable, which proves that our proposed method can enhance detailed semantic representation well.
Structure Pretraining and Prompt Tuning for Knowledge Graph Transfer
Mar 03, 2023Knowledge graphs (KG) are essential background knowledge providers in many tasks. When designing models for KG-related tasks, one of the key tasks is to devise the Knowledge Representation and Fusion (KRF) module that learns the representation of elements from KGs and fuses them with task representations. While due to the difference of KGs and perspectives to be considered during fusion across tasks, duplicate and ad hoc KRF modules design are conducted among tasks. In this paper, we propose a novel knowledge graph pretraining model KGTransformer that could serve as a uniform KRF module in diverse KG-related tasks. We pretrain KGTransformer with three self-supervised tasks with sampled sub-graphs as input. For utilization, we propose a general prompt-tuning mechanism regarding task data as a triple prompt to allow flexible interactions between task KGs and task data. We evaluate pretrained KGTransformer on three tasks, triple classification, zero-shot image classification, and question answering. KGTransformer consistently achieves better results than specifically designed task models. Through experiments, we justify that the pretrained KGTransformer could be used off the shelf as a general and effective KRF module across KG-related tasks. The code and datasets are available at https://github.com/zjukg/KGTransformer.
MEAformer: Multi-modal Entity Alignment Transformer for Meta Modality Hybrid
Dec 29, 2022
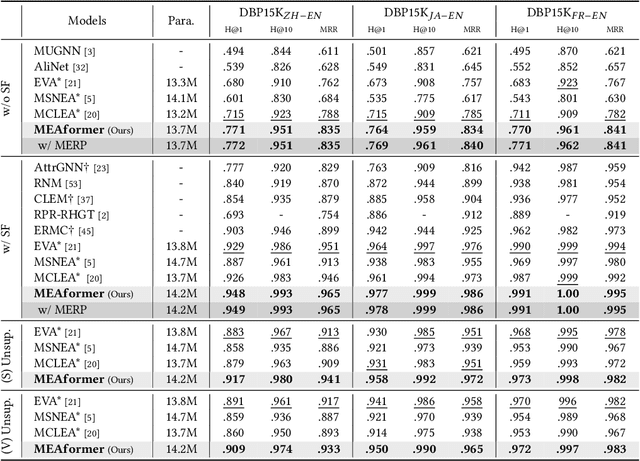
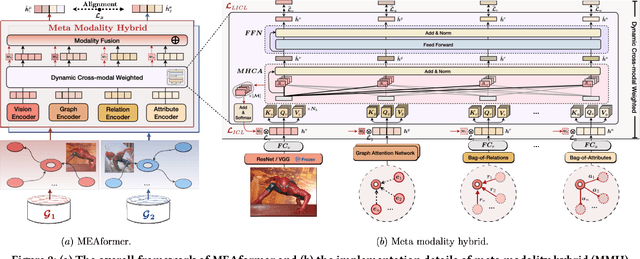
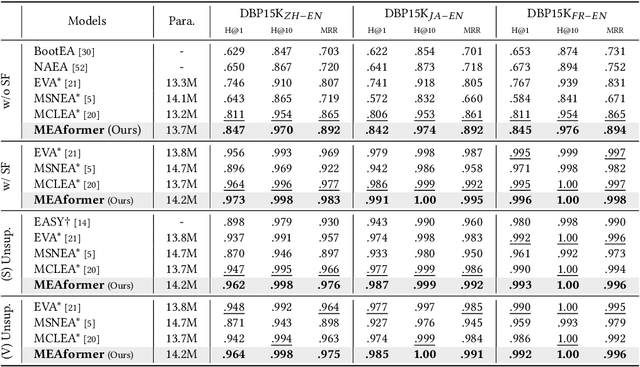
As an important variant of entity alignment (EA), multi-modal entity alignment (MMEA) aims to discover identical entities across different knowledge graphs (KGs) with multiple modalities like images. However, current MMEA algorithms all adopt KG-level modality fusion strategies but ignore modality differences among individual entities, hurting the robustness to potential noise involved in modalities (e.g., unidentifiable images and relations). In this paper we present MEAformer, a multi-modal entity alignment transformer approach for meta modality hybrid, to dynamically predict the mutual correlation coefficients among modalities for instance-level feature fusion. A modal-aware hard entity replay strategy is also proposed for addressing vague entity details. Extensive experimental results show that our model not only achieves SOTA performance on multiple training scenarios including supervised, unsupervised, iterative, and low resource, but also has limited parameters, optimistic speed, and good interpretability. Our code will be available soon.
Tele-Knowledge Pre-training for Fault Analysis
Oct 20, 2022


In this work, we share our experience on tele-knowledge pre-training for fault analysis. Fault analysis is a vital task for tele-application, which should be timely and properly handled. Fault analysis is also a complex task, that has many sub-tasks. Solving each task requires diverse tele-knowledge. Machine log data and product documents contain part of the tele-knowledge. We create a Tele-KG to organize other tele-knowledge from experts uniformly. With these valuable tele-knowledge data, in this work, we propose a tele-domain pre-training model KTeleBERT and its knowledge-enhanced version KTeleBERT, which includes effective prompt hints, adaptive numerical data encoding, and two knowledge injection paradigms. We train our model in two stages: pre-training TeleBERT on 20 million telecommunication corpora and re-training TeleBERT on 1 million causal and machine corpora to get the KTeleBERT. Then, we apply our models for three tasks of fault analysis, including root-cause analysis, event association prediction, and fault chain tracing. The results show that with KTeleBERT, the performance of task models has been boosted, demonstrating the effectiveness of pre-trained KTeleBERT as a model containing diverse tele-knowledge.
Aspect-based Sentiment Classification with Sequential Cross-modal Semantic Graph
Aug 19, 2022
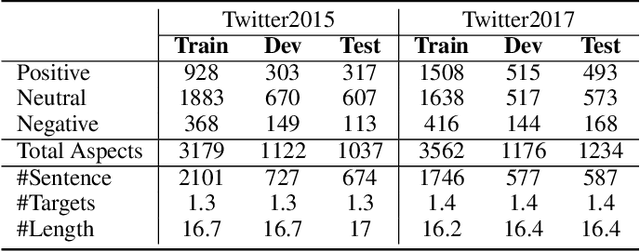
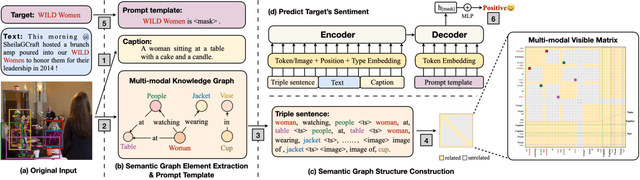
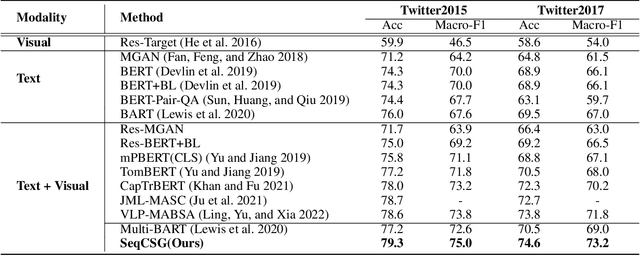
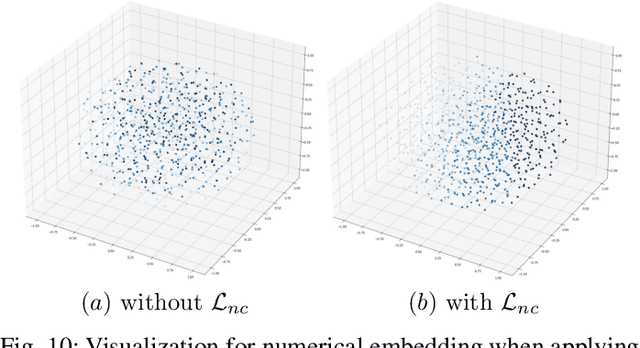
Multi-modal aspect-based sentiment classification (MABSC) is an emerging classification task that aims to classify the sentiment of a given target such as a mentioned entity in data with different modalities. In typical multi-modal data with text and image, previous approaches do not make full use of the fine-grained semantics of the image, especially in conjunction with the semantics of the text and do not fully consider modeling the relationship between fine-grained image information and target, which leads to insufficient use of image and inadequate to identify fine-grained aspects and opinions. To tackle these limitations, we propose a new framework SeqCSG including a method to construct sequential cross-modal semantic graphs and an encoder-decoder model. Specifically, we extract fine-grained information from the original image, image caption, and scene graph, and regard them as elements of the cross-modal semantic graph as well as tokens from texts. The cross-modal semantic graph is represented as a sequence with a multi-modal visible matrix indicating relationships between elements. In order to effectively utilize the cross-modal semantic graph, we propose an encoder-decoder method with a target prompt template. Experimental results show that our approach outperforms existing methods and achieves the state-of-the-art on two standard datasets MABSC. Further analysis demonstrates the effectiveness of each component and our model can implicitly learn the correlation between the target and fine-grained information of the image.
LaKo: Knowledge-driven Visual Question Answering via Late Knowledge-to-Text Injection
Jul 26, 2022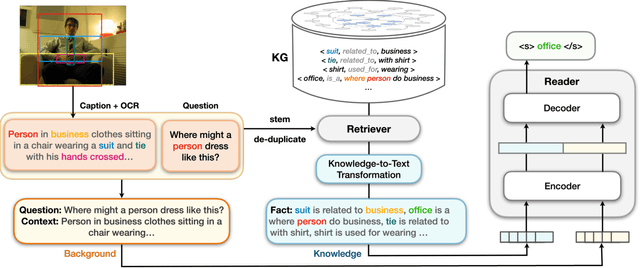

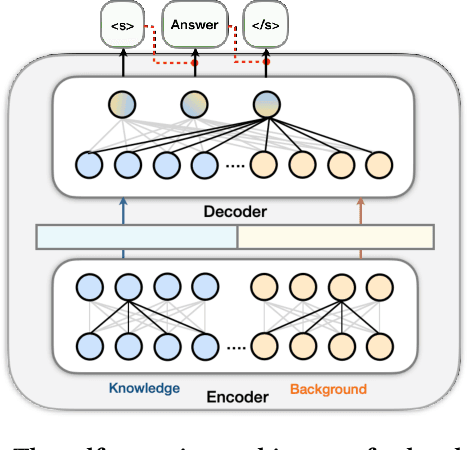

Visual question answering (VQA) often requires an understanding of visual concepts and language semantics, which relies on external knowledge. Most existing methods exploit pre-trained language models or/and unstructured text, but the knowledge in these resources are often incomplete and noisy. Some methods prefer to use knowledge graphs (KGs) which often have intensive structured knowledge, but the research is still quite preliminary. In this paper, we propose LaKo, a knowledge-driven VQA method via Late Knowledge-to-text Injection. To effectively incorporate an external KG, we transfer triples into text and propose a late injection mechanism. Finally we address VQA as a text generation task with an effective encoder-decoder paradigm. In the evaluation with OKVQA datasets, our method achieves state-of-the-art results.
DUET: Cross-modal Semantic Grounding for Contrastive Zero-shot Learning
Jul 04, 2022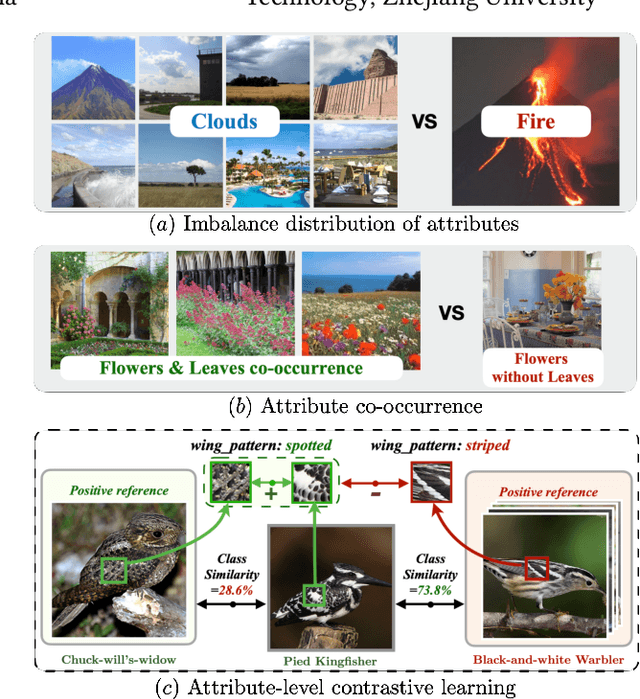
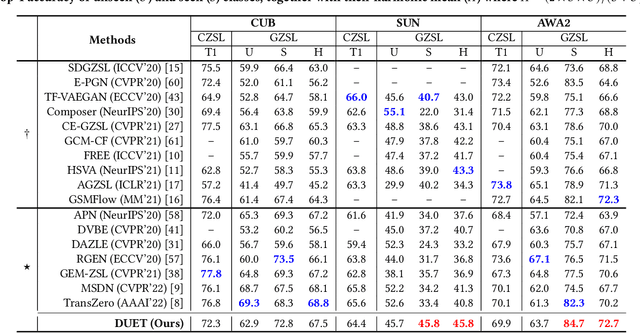
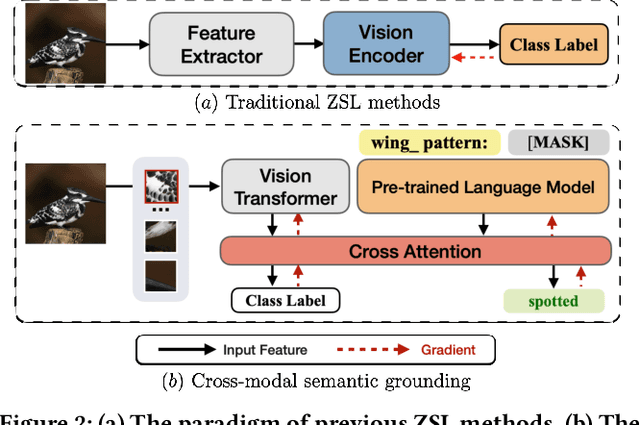

Zero-shot learning (ZSL) aims to predict unseen classes whose samples have never appeared during training, often utilizing additional semantic information (a.k.a. side information) to bridge the training (seen) classes and the unseen classes. One of the most effective and widely used semantic information for zero-shot image classification are attributes which are annotations for class-level visual characteristics. However, due to the shortage of fine-grained annotations, the attribute imbalance and co-occurrence, the current methods often fail to discriminate those subtle visual distinctions between images, which limits their performances. In this paper, we present a transformer-based end-to-end ZSL method named DUET, which integrates latent semantic knowledge from the pretrained language models (PLMs) via a self-supervised multi-modal learning paradigm. Specifically, we (1) developed a cross-modal semantic grounding network to investigate the model's capability of disentangling semantic attributes from the images, (2) applied an attribute-level contrastive learning strategy to further enhance the model's discrimination on fine-grained visual characteristics against the attribute co-occurrence and imbalance, and (3) proposed a multi-task learning policy for considering multi-model objectives. With extensive experiments on three standard ZSL benchmarks and a knowledge graph equipped ZSL benchmark, we find that DUET can often achieve state-of-the-art performance, its components are effective and its predictions are interpretable.
Disentangled Ontology Embedding for Zero-shot Learning
Jun 08, 2022
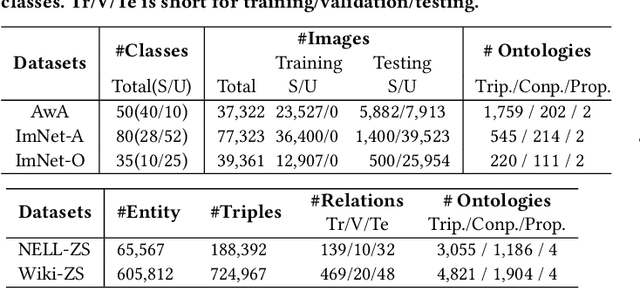
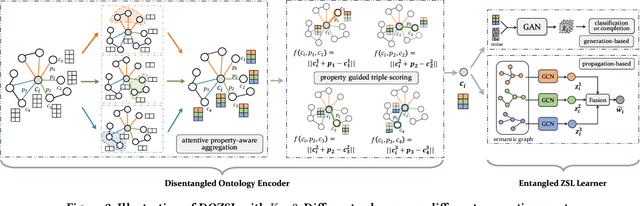
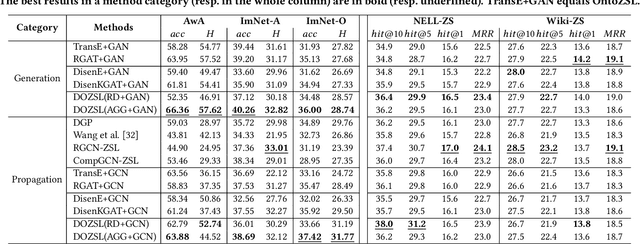
Knowledge Graph (KG) and its variant of ontology have been widely used for knowledge representation, and have shown to be quite effective in augmenting Zero-shot Learning (ZSL). However, existing ZSL methods that utilize KGs all neglect the intrinsic complexity of inter-class relationships represented in KGs. One typical feature is that a class is often related to other classes in different semantic aspects. In this paper, we focus on ontologies for augmenting ZSL, and propose to learn disentangled ontology embeddings guided by ontology properties to capture and utilize more fine-grained class relationships in different aspects. We also contribute a new ZSL framework named DOZSL, which contains two new ZSL solutions based on generative models and graph propagation models, respectively, for effectively utilizing the disentangled ontology embeddings. Extensive evaluations have been conducted on five benchmarks across zero-shot image classification (ZS-IMGC) and zero-shot KG completion (ZS-KGC). DOZSL often achieves better performance than the state-of-the-art, and its components have been verified by ablation studies and case studies. Our codes and datasets are available at https://github.com/zjukg/DOZSL.