 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEAformer: Multi-modal Entity Alignment Transformer for Meta Modality Hybrid
Paper and Code

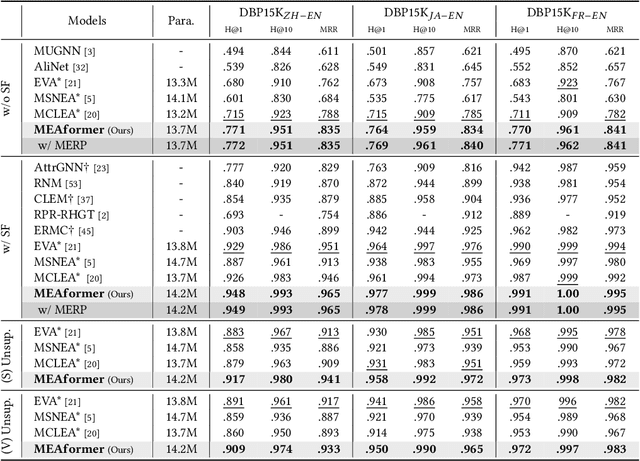
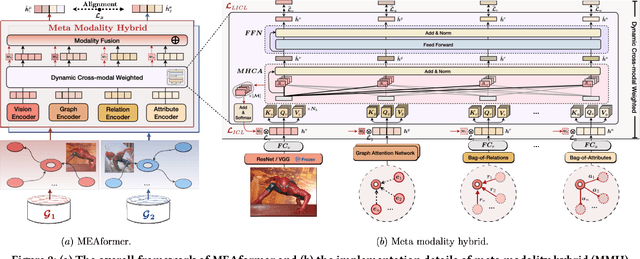
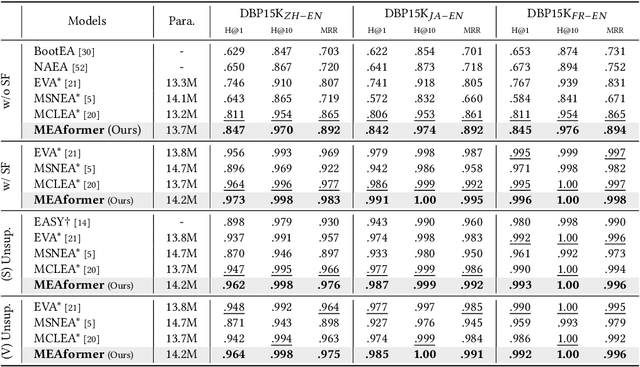
As an important variant of entity alignment (EA), multi-modal entity alignment (MMEA) aims to discover identical entities across different knowledge graphs (KGs) with multiple modalities like images. However, current MMEA algorithms all adopt KG-level modality fusion strategies but ignore modality differences among individual entities, hurting the robustness to potential noise involved in modalities (e.g., unidentifiable images and relations). In this paper we present MEAformer, a multi-modal entity alignment transformer approach for meta modality hybrid, to dynamically predict the mutual correlation coefficients among modalities for instance-level feature fusion. A modal-aware hard entity replay strategy is also proposed for addressing vague entity details. Extensive experimental results show that our model not only achieves SOTA performance on multiple training scenarios including supervised, unsupervised, iterative, and low resource, but also has limited parameters, optimistic speed, and good interpretability. Our code will be available soon.