 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRespiration Monitoring of Multiple People using Multi-site FMCW SISO Radar Systems
Apr 14, 2026Continuous contactless respiration monitoring of co-sleeping subjects faces a dilemma: conventional single-site multiple-input multiple-output (MIMO) radars struggle with limited angular resolution for closely spaced individuals, while distributed radar networks typically require complex hardware synchronization. To address these limitations, this paper proposes non-coherent multi-site single-input-single-output (SISO) radar systems that completely eliminate the need for physical synchronization cables or common reference clocks. The fundamental challenge of ghost target ambiguity in such non-coherent multilateration is resolved through a novel physiological-feature-assisted suppression technique. By exploiting the inherent statistical independence of individual respiratory rhythms, true target locations are robustly distinguished from ghosts via cross-correlation analysis. Experimental validation demonstrates that the proposed system can accurately resolve two subjects spaced less than 20 cm apart, surpassing the resolution limits of traditional compact MIMO arrays, while achieving a respiration rate estimation accuracy of 0.7 bpm root mean square error (RMSE) compared to contact-based ground truth.
Structure Pretraining and Prompt Tuning for Knowledge Graph Transfer
Mar 03, 2023Knowledge graphs (KG) are essential background knowledge providers in many tasks. When designing models for KG-related tasks, one of the key tasks is to devise the Knowledge Representation and Fusion (KRF) module that learns the representation of elements from KGs and fuses them with task representations. While due to the difference of KGs and perspectives to be considered during fusion across tasks, duplicate and ad hoc KRF modules design are conducted among tasks. In this paper, we propose a novel knowledge graph pretraining model KGTransformer that could serve as a uniform KRF module in diverse KG-related tasks. We pretrain KGTransformer with three self-supervised tasks with sampled sub-graphs as input. For utilization, we propose a general prompt-tuning mechanism regarding task data as a triple prompt to allow flexible interactions between task KGs and task data. We evaluate pretrained KGTransformer on three tasks, triple classification, zero-shot image classification, and question answering. KGTransformer consistently achieves better results than specifically designed task models. Through experiments, we justify that the pretrained KGTransformer could be used off the shelf as a general and effective KRF module across KG-related tasks. The code and datasets are available at https://github.com/zjukg/KGTransformer.
MEAformer: Multi-modal Entity Alignment Transformer for Meta Modality Hybrid
Dec 29, 2022
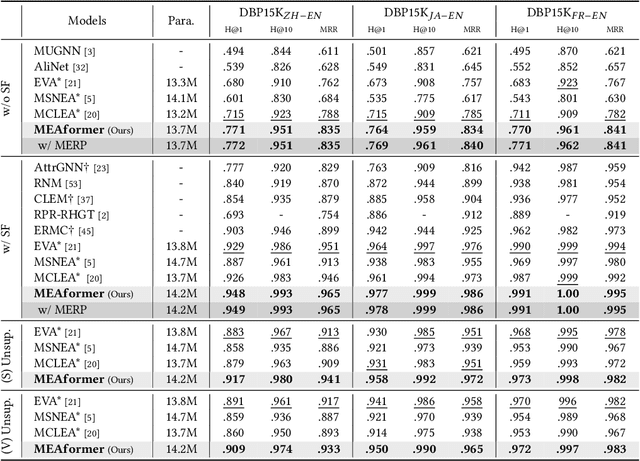
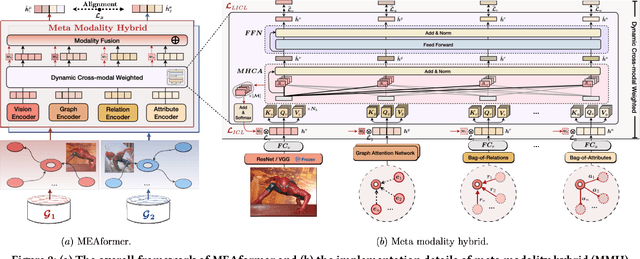
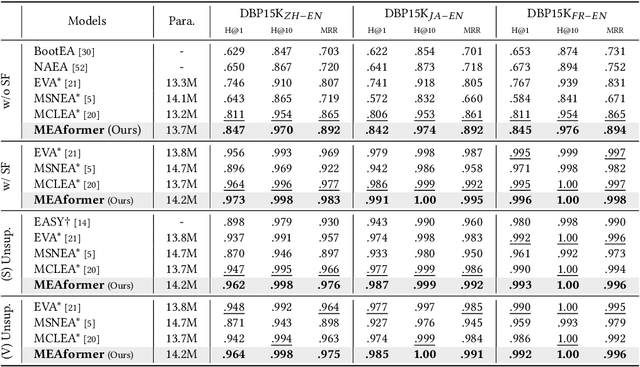
As an important variant of entity alignment (EA), multi-modal entity alignment (MMEA) aims to discover identical entities across different knowledge graphs (KGs) with multiple modalities like images. However, current MMEA algorithms all adopt KG-level modality fusion strategies but ignore modality differences among individual entities, hurting the robustness to potential noise involved in modalities (e.g., unidentifiable images and relations). In this paper we present MEAformer, a multi-modal entity alignment transformer approach for meta modality hybrid, to dynamically predict the mutual correlation coefficients among modalities for instance-level feature fusion. A modal-aware hard entity replay strategy is also proposed for addressing vague entity details. Extensive experimental results show that our model not only achieves SOTA performance on multiple training scenarios including supervised, unsupervised, iterative, and low resource, but also has limited parameters, optimistic speed, and good interpretability. Our code will be available soon.
Tele-Knowledge Pre-training for Fault Analysis
Oct 20, 2022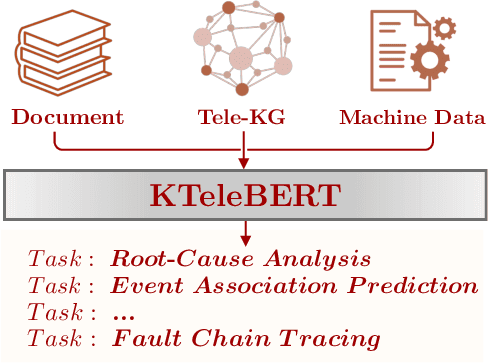


In this work, we share our experience on tele-knowledge pre-training for fault analysis. Fault analysis is a vital task for tele-application, which should be timely and properly handled. Fault analysis is also a complex task, that has many sub-tasks. Solving each task requires diverse tele-knowledge. Machine log data and product documents contain part of the tele-knowledge. We create a Tele-KG to organize other tele-knowledge from experts uniformly. With these valuable tele-knowledge data, in this work, we propose a tele-domain pre-training model KTeleBERT and its knowledge-enhanced version KTeleBERT, which includes effective prompt hints, adaptive numerical data encoding, and two knowledge injection paradigms. We train our model in two stages: pre-training TeleBERT on 20 million telecommunication corpora and re-training TeleBERT on 1 million causal and machine corpora to get the KTeleBERT. Then, we apply our models for three tasks of fault analysis, including root-cause analysis, event association prediction, and fault chain tracing. The results show that with KTeleBERT, the performance of task models has been boosted, demonstrating the effectiveness of pre-trained KTeleBERT as a model containing diverse tele-knowledge.
DUET: Cross-modal Semantic Grounding for Contrastive Zero-shot Learning
Jul 04, 2022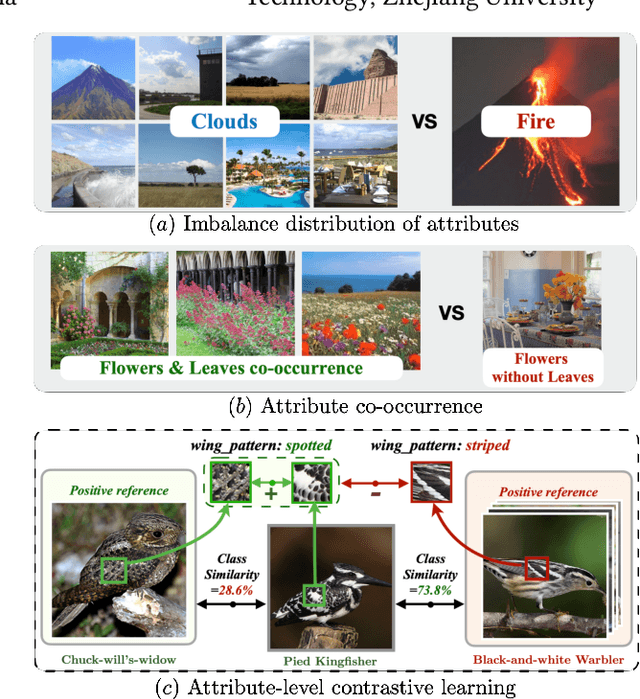
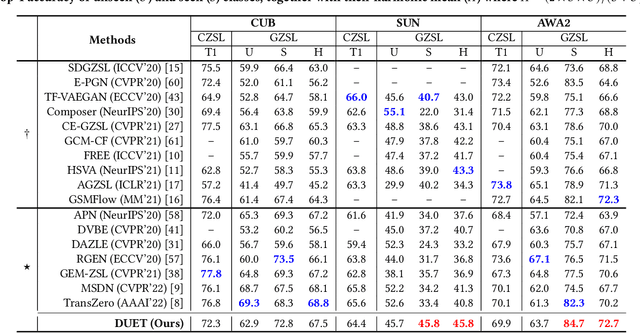
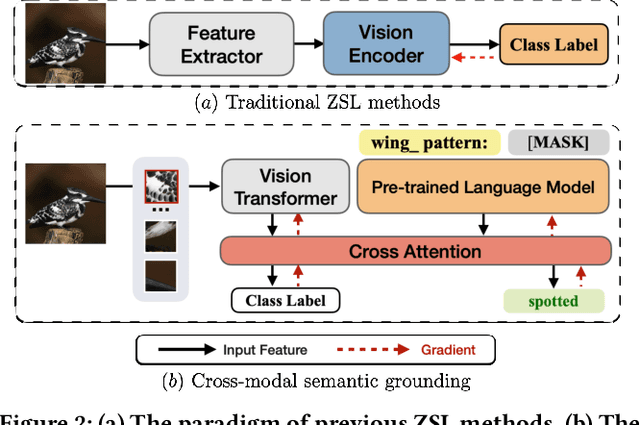

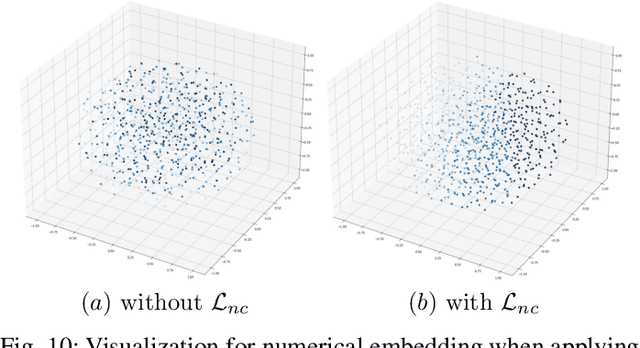
Zero-shot learning (ZSL) aims to predict unseen classes whose samples have never appeared during training, often utilizing additional semantic information (a.k.a. side information) to bridge the training (seen) classes and the unseen classes. One of the most effective and widely used semantic information for zero-shot image classification are attributes which are annotations for class-level visual characteristics. However, due to the shortage of fine-grained annotations, the attribute imbalance and co-occurrence, the current methods often fail to discriminate those subtle visual distinctions between images, which limits their performances. In this paper, we present a transformer-based end-to-end ZSL method named DUET, which integrates latent semantic knowledge from the pretrained language models (PLMs) via a self-supervised multi-modal learning paradigm. Specifically, we (1) developed a cross-modal semantic grounding network to investigate the model's capability of disentangling semantic attributes from the images, (2) applied an attribute-level contrastive learning strategy to further enhance the model's discrimination on fine-grained visual characteristics against the attribute co-occurrence and imbalance, and (3) proposed a multi-task learning policy for considering multi-model objectives. With extensive experiments on three standard ZSL benchmarks and a knowledge graph equipped ZSL benchmark, we find that DUET can often achieve state-of-the-art performance, its components are effective and its predictions are interpretable.