 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Knowledge Graph Generation with Semantics-enriched Prompts
Apr 18, 2025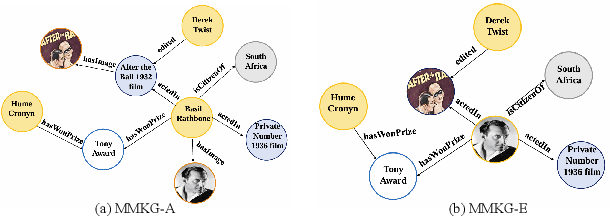
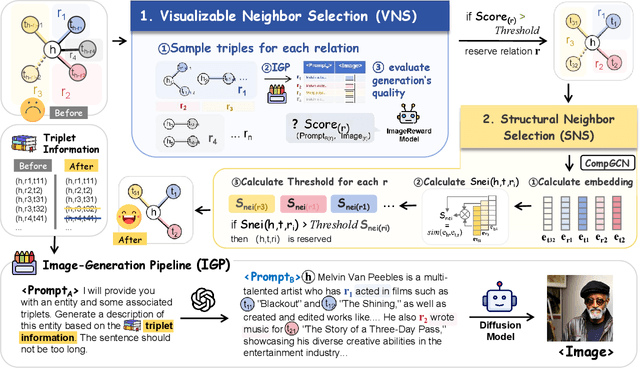
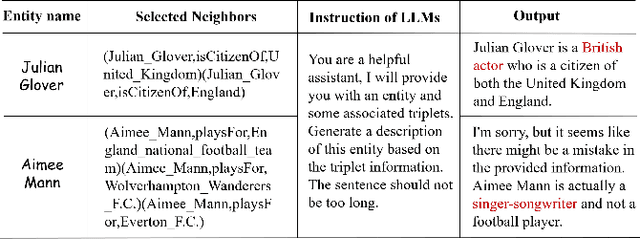

Multi-modal Knowledge Graphs (MMKGs) have been widely applied across various domains for knowledge representation. However, the existing MMKGs are significantly fewer than required, and their construction faces numerous challenges, particularly in ensuring the selection of high-quality, contextually relevant images for knowledge graph enrichment. To address these challenges, we present a framework for constructing MMKGs from conventional KGs. Furthermore, to generate higher-quality images that are more relevant to the context in the given knowledge graph, we designed a neighbor selection method called Visualizable Structural Neighbor Selection (VSNS). This method consists of two modules: Visualizable Neighbor Selection (VNS) and Structural Neighbor Selection (SNS). The VNS module filters relations that are difficult to visualize, while the SNS module selects neighbors that most effectively capture the structural characteristics of the entity. To evaluate the quality of the generated images, we performed qualitative and quantitative evaluations on two datasets, MKG-Y and DB15K. The experimental results indicate that using the VSNS method to select neighbors results in higher-quality images that are more relevant to the knowledge graph.
Have We Designed Generalizable Structural Knowledge Promptings? Systematic Evaluation and Rethinking
Dec 31, 2024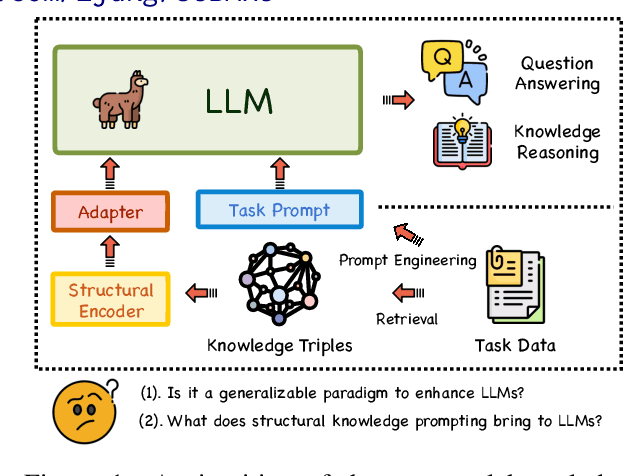
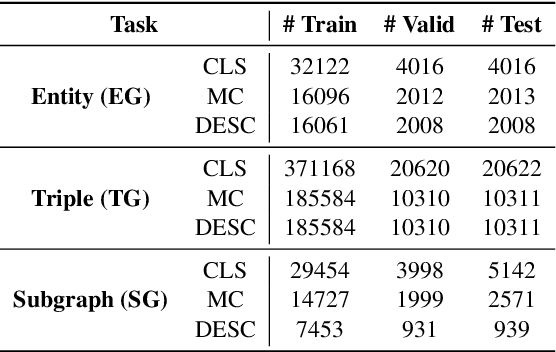
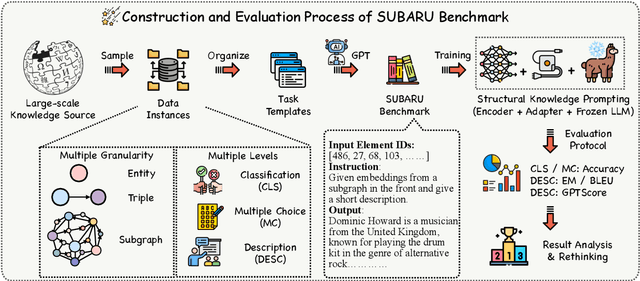
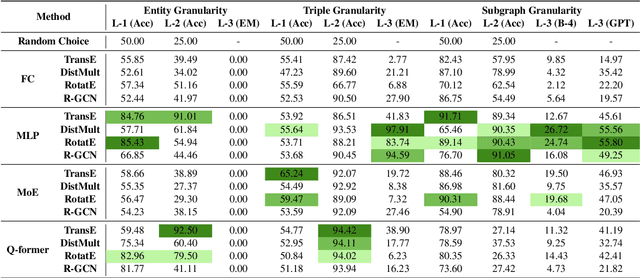
Large language models (LLMs) have demonstrated exceptional performance in text generation within current NLP research. However, the lack of factual accuracy is still a dark cloud hanging over the LLM skyscraper. Structural knowledge prompting (SKP) is a prominent paradigm to integrate external knowledge into LLMs by incorporating structural representations, achieving state-of-the-art results in many knowledge-intensive tasks. However, existing methods often focus on specific problems, lacking a comprehensive exploration of the generalization and capability boundaries of SKP. This paper aims to evaluate and rethink the generalization capability of the SKP paradigm from four perspectives including Granularity, Transferability, Scalability, and Universality. To provide a thorough evaluation, we introduce a novel multi-granular, multi-level benchmark called SUBARU, consisting of 9 different tasks with varying levels of granularity and difficulty.
Is Large Language Model Good at Triple Set Prediction? An Empirical Study
Dec 24, 2024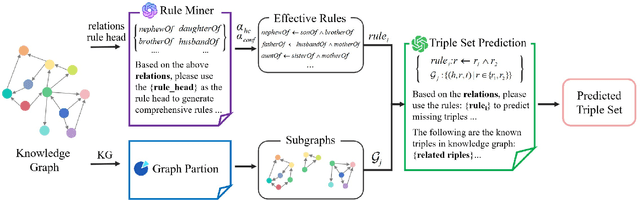



The core of the Knowledge Graph Completion (KGC) task is to predict and complete the missing relations or nodes in a KG. Common KGC tasks are mostly about inferring unknown elements with one or two elements being known in a triple. In comparison, the Triple Set Prediction (TSP) task is a more realistic knowledge graph completion task. It aims to predict all elements of unknown triples based on the information from known triples. In recent years, large language models (LLMs) have exhibited significant advancements in language comprehension, demonstrating considerable potential for KGC tasks. However, the potential of LLM on the TSP task has not yet to be investigated. Thus in this paper we proposed a new framework to explore the strengths and limitations of LLM in the TSP task. Specifically, the framework consists of LLM-based rule mining and LLM-based triple set prediction. The relation list of KG embedded within rich semantic information is first leveraged to prompt LLM in the generation of rules. This process is both efficient and independent of statistical information, making it easier to mine effective and realistic rules. For each subgraph, the specified rule is applied in conjunction with the relevant triples within that subgraph to guide the LLM in predicting the missing triples. Subsequently, the predictions from all subgraphs are consolidated to derive the complete set of predicted triples on KG. Finally, the method is evaluated on the relatively complete CFamily dataset. The experimental results indicate that when LLMs are required to adhere to a large amount of factual knowledge to predict missing triples, significant hallucinations occurs, leading to a noticeable decline in performance. To further explore the causes of this phenomenon, this paper presents a comprehensive analysis supported by a detailed case study.
SF-GNN: Self Filter for Message Lossless Propagation in Deep Graph Neural Network
Jul 03, 2024



Graph Neural Network (GNN), with the main idea of encoding graph structure information of graphs by propagation and aggregation, has developed rapidly. It achieved excellent performance in representation learning of multiple types of graphs such as homogeneous graphs, heterogeneous graphs, and more complex graphs like knowledge graphs. However, merely stacking GNN layers may not improve the model's performance and can even be detrimental. For the phenomenon of performance degradation in deep GNNs, we propose a new perspective. Unlike the popular explanations of over-smoothing or over-squashing, we think the issue arises from the interference of low-quality node representations during message propagation. We introduce a simple and general method, SF-GNN, to address this problem. In SF-GNN, we define two representations for each node, one is the node representation that represents the feature of the node itself, and the other is the message representation specifically for propagating messages to neighbor nodes. A self-filter module evaluates the quality of the node representation and decides whether to integrate it into the message propagation based on this quality assessment. Experiments on node classification tasks for both homogeneous and heterogeneous graphs, as well as link prediction tasks on knowledge graphs, demonstrate that our method can be applied to various GNN models and outperforms state-of-the-art baseline methods in addressing deep GNN degradation.
Start from Zero: Triple Set Prediction for Automatic Knowledge Graph Completion
Jun 26, 2024



Knowledge graph (KG) completion aims to find out missing triples in a KG. Some tasks, such as link prediction and instance completion, have been proposed for KG completion. They are triple-level tasks with some elements in a missing triple given to predict the missing element of the triple. However, knowing some elements of the missing triple in advance is not always a realistic setting. In this paper, we propose a novel graph-level automatic KG completion task called Triple Set Prediction (TSP) which assumes none of the elements in the missing triples is given. TSP is to predict a set of missing triples given a set of known triples. To properly and accurately evaluate this new task, we propose 4 evaluation metrics including 3 classification metrics and 1 ranking metric, considering both the partial-open-world and the closed-world assumptions. Furthermore, to tackle the huge candidate triples for prediction, we propose a novel and efficient subgraph-based method GPHT that can predict the triple set fast. To fairly compare the TSP results, we also propose two types of methods RuleTensor-TSP and KGE-TSP applying the existing rule- and embedding-based methods for TSP as baselines. During experiments, we evaluate the proposed methods on two datasets extracted from Wikidata following the relation-similarity partial-open-world assumption proposed by us, and also create a complete family data set to evaluate TSP results following the closed-world assumption. Results prove that the methods can successfully generate a set of missing triples and achieve reasonable scores on the new task, and GPHT performs better than the baselines with significantly shorter prediction time. The datasets and code for experiments are available at https://github.com/zjukg/GPHT-for-TSP.
Mixture of Modality Knowledge Experts for Robust Multi-modal Knowledge Graph Completion
May 27, 2024Multi-modal knowledge graph completion (MMKGC) aims to automatically discover new knowledge triples in the given multi-modal knowledge graphs (MMKGs), which is achieved by collaborative modeling the structural information concealed in massive triples and the multi-modal features of the entities. Existing methods tend to focus on crafting elegant entity-wise multi-modal fusion strategies, yet they overlook the utilization of multi-perspective features concealed within the modalities under diverse relational contexts. To address this issue, we introduce a novel MMKGC framework with Mixture of Modality Knowledge experts (MoMoK for short) to learn adaptive multi-modal embedding under intricate relational contexts. We design relation-guided modality knowledge experts to acquire relation-aware modality embeddings and integrate the predictions from multi-modalities to achieve comprehensive decisions. Additionally, we disentangle the experts by minimizing their mutual information. Experiments on four public MMKG benchmarks demonstrate the outstanding performance of MoMoK under complex scenarios.
MyGO: Discrete Modality Information as Fine-Grained Tokens for Multi-modal Knowledge Graph Completion
Apr 15, 2024



Multi-modal knowledge graphs (MMKG) store structured world knowledge containing rich multi-modal descriptive information. To overcome their inherent incompleteness, multi-modal knowledge graph completion (MMKGC) aims to discover unobserved knowledge from given MMKGs, leveraging both structural information from the triples and multi-modal information of the entities. Existing MMKGC methods usually extract multi-modal features with pre-trained models and employ a fusion module to integrate multi-modal features with triple prediction. However, this often results in a coarse handling of multi-modal data, overlooking the nuanced, fine-grained semantic details and their interactions. To tackle this shortfall, we introduce a novel framework MyGO to process, fuse, and augment the fine-grained modality information from MMKGs. MyGO tokenizes multi-modal raw data as fine-grained discrete tokens and learns entity representations with a cross-modal entity encoder. To further augment the multi-modal representations, MyGO incorporates fine-grained contrastive learning to highlight the specificity of the entity representations. Experiments on standard MMKGC benchmarks reveal that our method surpasses 20 of the latest models, underlining its superior performance. Code and data are available at https://github.com/zjukg/MyGO
Learning to Rank Utterances for Query-Focused Meeting Summarization
May 22, 2023Query-focused meeting summarization(QFMS) aims to generate a specific summary for the given query according to the meeting transcripts. Due to the conflict between long meetings and limited input size, previous works mainly adopt extract-then-summarize methods, which use extractors to simulate binary labels or ROUGE scores to extract utterances related to the query and then generate a summary. However, the previous approach fails to fully use the comparison between utterances. To the extractor, comparison orders are more important than specific scores. In this paper, we propose a Ranker-Generator framework. It learns to rank the utterances by comparing them in pairs and learning from the global orders, then uses top utterances as the generator's input. We show that learning to rank utterances helps to select utterances related to the query effectively, and the summarizer can benefit from it. Experimental results on QMSum show that the proposed model outperforms all existing multi-stage models with fewer parameters.
Query-Utterance Attention with Joint modeling for Query-Focused Meeting Summarization
Mar 08, 2023



Query-focused meeting summarization (QFMS) aims to generate summaries from meeting transcripts in response to a given query. Previous works typically concatenate the query with meeting transcripts and implicitly model the query relevance only at the token level with attention mechanism. However, due to the dilution of key query-relevant information caused by long meeting transcripts, the original transformer-based model is insufficient to highlight the key parts related to the query. In this paper, we propose a query-aware framework with joint modeling token and utterance based on Query-Utterance Attention. It calculates the utterance-level relevance to the query with a dense retrieval module. Then both token-level query relevance and utterance-level query relevance are combined and incorporated into the generation process with attention mechanism explicitly. We show that the query relevance of different granularities contributes to generating a summary more related to the query. Experimental results on the QMSum dataset show that the proposed model achieves new state-of-the-art performance.
Structure Pretraining and Prompt Tuning for Knowledge Graph Transfer
Mar 03, 2023Knowledge graphs (KG) are essential background knowledge providers in many tasks. When designing models for KG-related tasks, one of the key tasks is to devise the Knowledge Representation and Fusion (KRF) module that learns the representation of elements from KGs and fuses them with task representations. While due to the difference of KGs and perspectives to be considered during fusion across tasks, duplicate and ad hoc KRF modules design are conducted among tasks. In this paper, we propose a novel knowledge graph pretraining model KGTransformer that could serve as a uniform KRF module in diverse KG-related tasks. We pretrain KGTransformer with three self-supervised tasks with sampled sub-graphs as input. For utilization, we propose a general prompt-tuning mechanism regarding task data as a triple prompt to allow flexible interactions between task KGs and task data. We evaluate pretrained KGTransformer on three tasks, triple classification, zero-shot image classification, and question answering. KGTransformer consistently achieves better results than specifically designed task models. Through experiments, we justify that the pretrained KGTransformer could be used off the shelf as a general and effective KRF module across KG-related tasks. The code and datasets are available at https://github.com/zjukg/KGTransformer.