 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCC-Loc: A Unified Semantic Cascade Consensus Framework for UAV Thermal Geo-Localization
Apr 03, 2026Cross-modal Thermal Geo-localization (TG) provides a robust, all-weather solution for Unmanned Aerial Vehicles (UAVs) in Global Navigation Satellite System (GNSS)-denied environments. However, profound thermal-visible modality gaps introduce severe feature ambiguity, systematically corrupting conventional coarse-to-fine registration. To dismantle this bottleneck, we propose SCC-Loc, a unified Semantic-Cascade-Consensus localization framework. By sharing a single DINOv2 backbone across global retrieval and MINIMA$_{\text{RoMa}}$ matching, it minimizes memory footprint and achieves zero-shot, highly accurate absolute position estimation. Specifically, we tackle modality ambiguity by introducing three cohesive components. First, we design the Semantic-Guided Viewport Alignment (SGVA) module to adaptively optimize satellite crop regions, effectively correcting initial spatial deviations. Second, we develop the Cascaded Spatial-Adaptive Texture-Structure Filtering (C-SATSF) mechanism to explicitly enforce geometric consistency, thereby eradicating dense cross-modal outliers. Finally, we propose the Consensus-Driven Reliability-Aware Position Selection (CD-RAPS) strategy to derive the optimal solution through a synergy of physically constrained pose optimization. To address data scarcity, we construct Thermal-UAV, a comprehensive dataset providing 11,890 diverse thermal queries referenced against a large-scale satellite ortho-photo and corresponding spatially aligned Digital Surface Model (DSM). Extensive experiments demonstrate that SCC-Loc establishes a new state-of-the-art, suppressing the mean localization error to 9.37 m and providing a 7.6-fold accuracy improvement within a strict 5-m threshold over the strongest baseline. Code and dataset are available at https://github.com/FloralHercules/SCC-Loc.
DST-Calib: A Dual-Path, Self-Supervised, Target-Free LiDAR-Camera Extrinsic Calibration Network
Jan 03, 2026LiDAR-camera extrinsic calibration is essential for multi-modal data fusion in robotic perception systems. However, existing approaches typically rely on handcrafted calibration targets (e.g., checkerboards) or specific, static scene types, limiting their adaptability and deployment in real-world autonomous and robotic applications. This article presents the first self-supervised LiDAR-camera extrinsic calibration network that operates in an online fashion and eliminates the need for specific calibration targets. We first identify a significant generalization degradation problem in prior methods, caused by the conventional single-sided data augmentation strategy. To overcome this limitation, we propose a novel double-sided data augmentation technique that generates multi-perspective camera views using estimated depth maps, thereby enhancing robustness and diversity during training. Built upon this augmentation strategy, we design a dual-path, self-supervised calibration framework that reduces the dependence on high-precision ground truth labels and supports fully adaptive online calibration. Furthermore, to improve cross-modal feature association, we replace the traditional dual-branch feature extraction design with a difference map construction process that explicitly correlates LiDAR and camera features. This not only enhances calibration accuracy but also reduces model complexity. Extensive experiments conducted on five public benchmark datasets, as well as our own recorded dataset, demonstrate that the proposed method significantly outperforms existing approaches in terms of generalizability.
ChangingGrounding: 3D Visual Grounding in Changing Scenes
Oct 16, 2025Real-world robots localize objects from natural-language instructions while scenes around them keep changing. Yet most of the existing 3D visual grounding (3DVG) method still assumes a reconstructed and up-to-date point cloud, an assumption that forces costly re-scans and hinders deployment. We argue that 3DVG should be formulated as an active, memory-driven problem, and we introduce ChangingGrounding, the first benchmark that explicitly measures how well an agent can exploit past observations, explore only where needed, and still deliver precise 3D boxes in changing scenes. To set a strong reference point, we also propose Mem-ChangingGrounder, a zero-shot method for this task that marries cross-modal retrieval with lightweight multi-view fusion: it identifies the object type implied by the query, retrieves relevant memories to guide actions, then explores the target efficiently in the scene, falls back when previous operations are invalid, performs multi-view scanning of the target, and projects the fused evidence from multi-view scans to get accurate object bounding boxes. We evaluate different baselines on ChangingGrounding, and our Mem-ChangingGrounder achieves the highest localization accuracy while greatly reducing exploration cost. We hope this benchmark and method catalyze a shift toward practical, memory-centric 3DVG research for real-world applications. Project page: https://hm123450.github.io/CGB/ .
LiveThinking: Enabling Real-Time Efficient Reasoning for AI-Powered Livestreaming via Reinforcement Learning
Oct 09, 2025
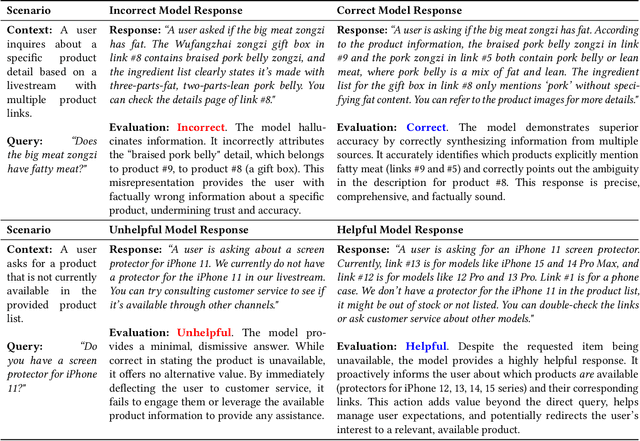
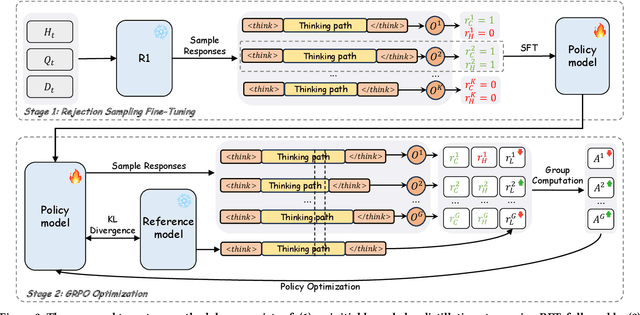
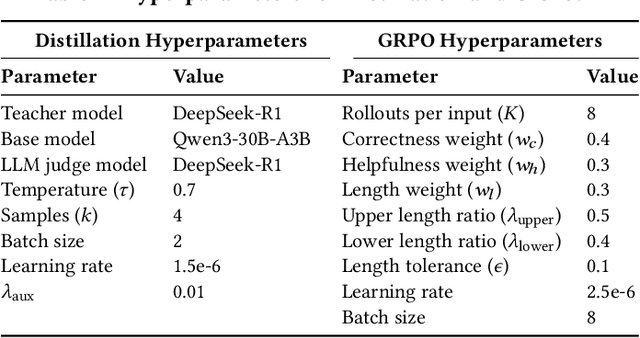
In AI-powered e-commerce livestreaming, digital avatars require real-time responses to drive engagement, a task for which high-latency Large Reasoning Models (LRMs) are ill-suited. We introduce LiveThinking, a practical two-stage optimization framework to bridge this gap. First, we address computational cost by distilling a 670B teacher LRM into a lightweight 30B Mixture-of-Experts (MoE) model (3B active) using Rejection Sampling Fine-Tuning (RFT). This reduces deployment overhead but preserves the teacher's verbose reasoning, causing latency. To solve this, our second stage employs reinforcement learning with Group Relative Policy Optimization (GRPO) to compress the model's reasoning path, guided by a multi-objective reward function balancing correctness, helpfulness, and brevity. LiveThinking achieves a 30-fold reduction in computational cost, enabling sub-second latency. In real-world application on Taobao Live, it improved response correctness by 3.3% and helpfulness by 21.8%. Tested by hundreds of thousands of viewers, our system led to a statistically significant increase in Gross Merchandise Volume (GMV), demonstrating its effectiveness in enhancing user experience and commercial performance in live, interactive settings.
From Sparse to Dense: Camera Relocalization with Scene-Specific Detector from Feature Gaussian Splatting
Mar 25, 2025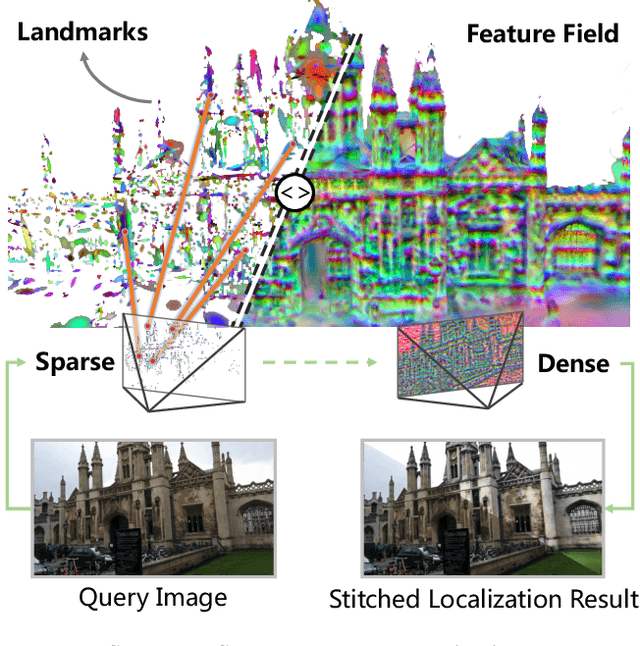
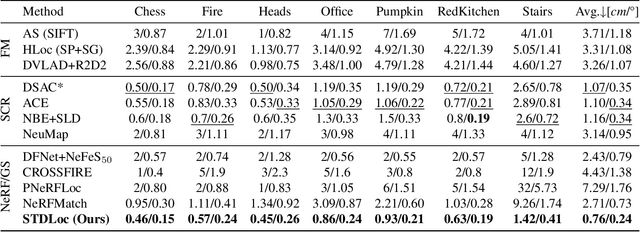
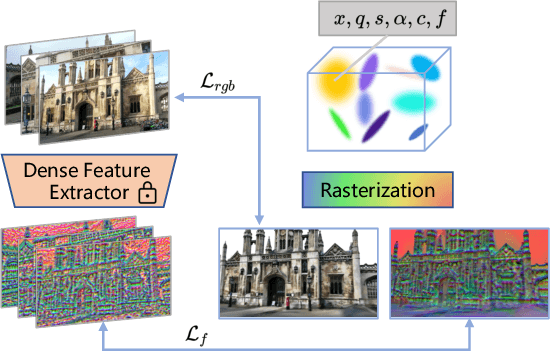

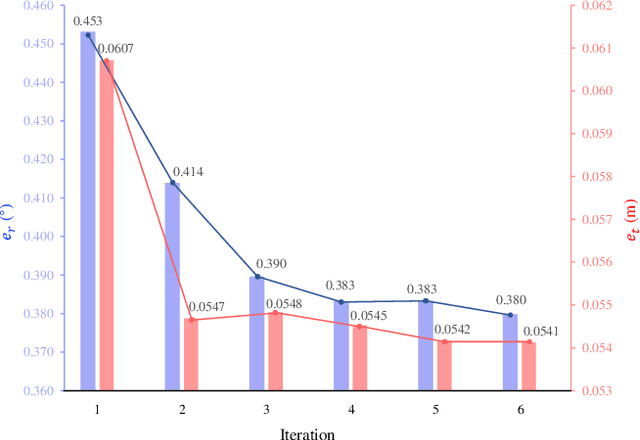
This paper presents a novel camera relocalization method, STDLoc, which leverages Feature Gaussian as scene representation. STDLoc is a full relocalization pipeline that can achieve accurate relocalization without relying on any pose prior. Unlike previous coarse-to-fine localization methods that require image retrieval first and then feature matching, we propose a novel sparse-to-dense localization paradigm. Based on this scene representation, we introduce a novel matching-oriented Gaussian sampling strategy and a scene-specific detector to achieve efficient and robust initial pose estimation. Furthermore, based on the initial localization results, we align the query feature map to the Gaussian feature field by dense feature matching to enable accurate localization. The experiments on indoor and outdoor datasets show that STDLoc outperforms current state-of-the-art localization methods in terms of localization accuracy and recall.
Environment-Driven Online LiDAR-Camera Extrinsic Calibration
Feb 02, 2025LiDAR-camera extrinsic calibration (LCEC) is the core for data fusion in computer vision. Existing methods typically rely on customized calibration targets or fixed scene types, lacking the flexibility to handle variations in sensor data and environmental contexts. This paper introduces EdO-LCEC, the first environment-driven, online calibration approach that achieves human-like adaptability. Inspired by the human perceptual system, EdO-LCEC incorporates a generalizable scene discriminator to actively interpret environmental conditions, creating multiple virtual cameras that capture detailed spatial and textural information. To overcome cross-modal feature matching challenges between LiDAR and camera, we propose dual-path correspondence matching (DPCM), which leverages both structural and textural consistency to achieve reliable 3D-2D correspondences. Our approach formulates the calibration process as a spatial-temporal joint optimization problem, utilizing global constraints from multiple views and scenes to improve accuracy, particularly in sparse or partially overlapping sensor views. Extensive experiments on real-world datasets demonstrate that EdO-LCEC achieves state-of-the-art performance, providing reliable and precise calibration across diverse, challenging environments.
VLM-Grounder: A VLM Agent for Zero-Shot 3D Visual Grounding
Oct 17, 2024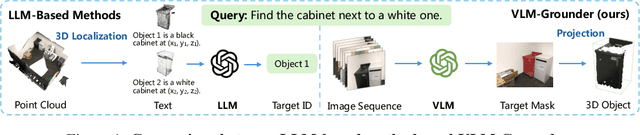
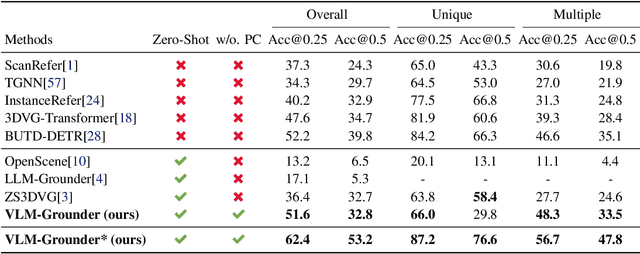
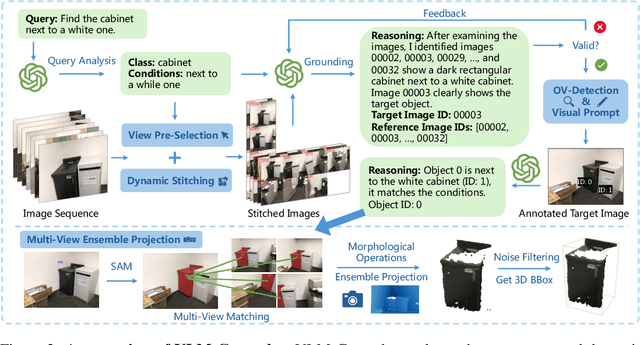
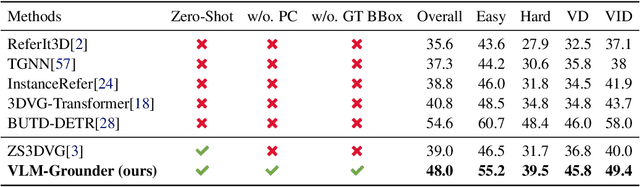
3D visual grounding is crucial for robots, requiring integration of natural language and 3D scene understanding. Traditional methods depending on supervised learning with 3D point clouds are limited by scarce datasets. Recently zero-shot methods leveraging LLMs have been proposed to address the data issue. While effective, these methods only use object-centric information, limiting their ability to handle complex queries. In this work, we present VLM-Grounder, a novel framework using vision-language models (VLMs) for zero-shot 3D visual grounding based solely on 2D images. VLM-Grounder dynamically stitches image sequences, employs a grounding and feedback scheme to find the target object, and uses a multi-view ensemble projection to accurately estimate 3D bounding boxes. Experiments on ScanRefer and Nr3D datasets show VLM-Grounder outperforms previous zero-shot methods, achieving 51.6% Acc@0.25 on ScanRefer and 48.0% Acc on Nr3D, without relying on 3D geometry or object priors. Codes are available at https://github.com/OpenRobotLab/VLM-Grounder .
TrustUQA: A Trustful Framework for Unified Structured Data Question Answering
Jun 27, 2024



Natural language question answering (QA) over structured data sources such as tables and knowledge graphs (KGs) have been widely investigated, for example with Large Language Models (LLMs). The main solutions include question to formal query parsing and retrieval-based answer generation. However, current methods of the former often suffer from weak generalization, failing to dealing with multiple sources simultaneously, while the later is limited in trustfulness. In this paper, we propose UnifiedTQA, a trustful QA framework that can simultaneously support multiple types of structured data in a unified way. To this end, it adopts an LLM-friendly and unified knowledge representation method called Condition Graph (CG), and uses an LLM and demonstration-based two-level method for CG querying. For enhancement, it is also equipped with dynamic demonstration retrieval. We have evaluated UnifiedTQA with 5 benchmarks covering 3 types of structured data. It outperforms 2 existing unified structured data QA methods and in comparison with the baselines that are specific to a data type, it achieves state-of-the-art on 2 of them. Further more, we demonstrates potential of our method for more general QA tasks, QA over mixed structured data and QA across structured data.
Start from Zero: Triple Set Prediction for Automatic Knowledge Graph Completion
Jun 26, 2024



Knowledge graph (KG) completion aims to find out missing triples in a KG. Some tasks, such as link prediction and instance completion, have been proposed for KG completion. They are triple-level tasks with some elements in a missing triple given to predict the missing element of the triple. However, knowing some elements of the missing triple in advance is not always a realistic setting. In this paper, we propose a novel graph-level automatic KG completion task called Triple Set Prediction (TSP) which assumes none of the elements in the missing triples is given. TSP is to predict a set of missing triples given a set of known triples. To properly and accurately evaluate this new task, we propose 4 evaluation metrics including 3 classification metrics and 1 ranking metric, considering both the partial-open-world and the closed-world assumptions. Furthermore, to tackle the huge candidate triples for prediction, we propose a novel and efficient subgraph-based method GPHT that can predict the triple set fast. To fairly compare the TSP results, we also propose two types of methods RuleTensor-TSP and KGE-TSP applying the existing rule- and embedding-based methods for TSP as baselines. During experiments, we evaluate the proposed methods on two datasets extracted from Wikidata following the relation-similarity partial-open-world assumption proposed by us, and also create a complete family data set to evaluate TSP results following the closed-world assumption. Results prove that the methods can successfully generate a set of missing triples and achieve reasonable scores on the new task, and GPHT performs better than the baselines with significantly shorter prediction time. The datasets and code for experiments are available at https://github.com/zjukg/GPHT-for-TSP.
Online,Target-Free LiDAR-Camera Extrinsic Calibration via Cross-Modal Mask Matching
Apr 28, 2024
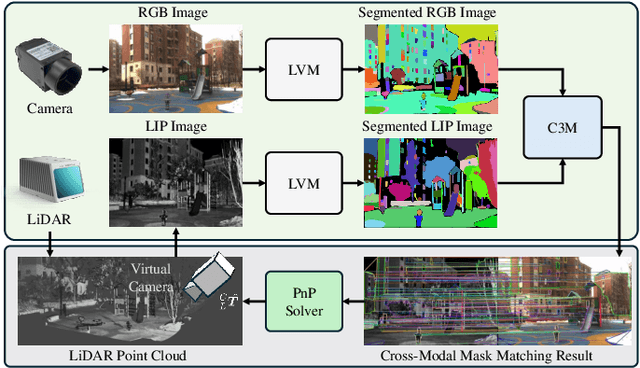
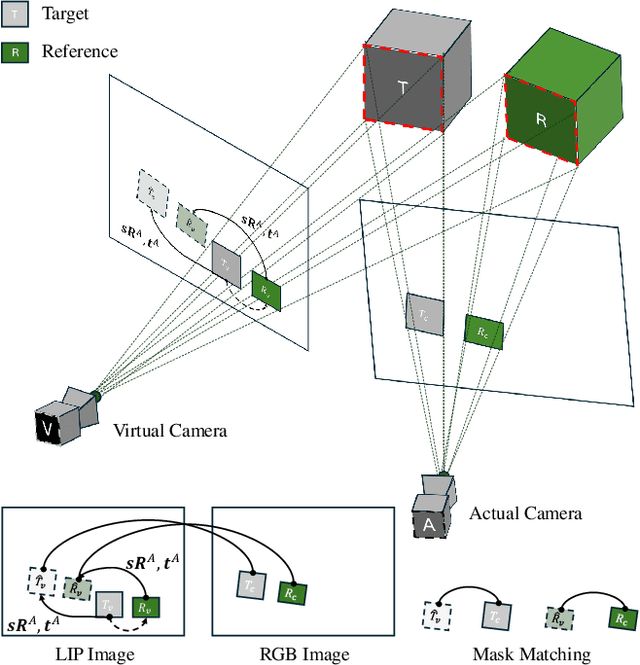
LiDAR-camera extrinsic calibration (LCEC) is crucial for data fusion in intelligent vehicles. Offline, target-based approaches have long been the preferred choice in this field. However, they often demonstrate poor adaptability to real-world environments. This is largely because extrinsic parameters may change significantly due to moderate shocks or during extended operations in environments with vibrations. In contrast, online, target-free approaches provide greater adaptability yet typically lack robustness, primarily due to the challenges in cross-modal feature matching. Therefore, in this article, we unleash the full potential of large vision models (LVMs), which are emerging as a significant trend in the fields of computer vision and robotics, especially for embodied artificial intelligence, to achieve robust and accurate online, target-free LCEC across a variety of challenging scenarios. Our main contributions are threefold: we introduce a novel framework known as MIAS-LCEC, provide an open-source versatile calibration toolbox with an interactive visualization interface, and publish three real-world datasets captured from various indoor and outdoor environments. The cornerstone of our framework and toolbox is the cross-modal mask matching (C3M) algorithm, developed based on a state-of-the-art (SoTA) LVM and capable of generating sufficient and reliable matches. Extensive experiments conducted on these real-world datasets demonstrate the robustness of our approach and its superior performance compared to SoTA methods, particularly for the solid-state LiDARs with super-wide fields of view.