 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvontree: Ontology Rule-Guided Self-Evolution of Large Language Models
Oct 30, 2025
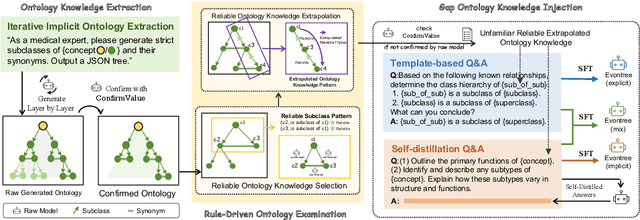
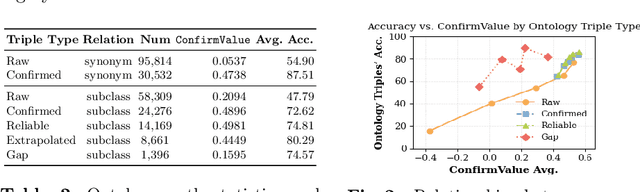
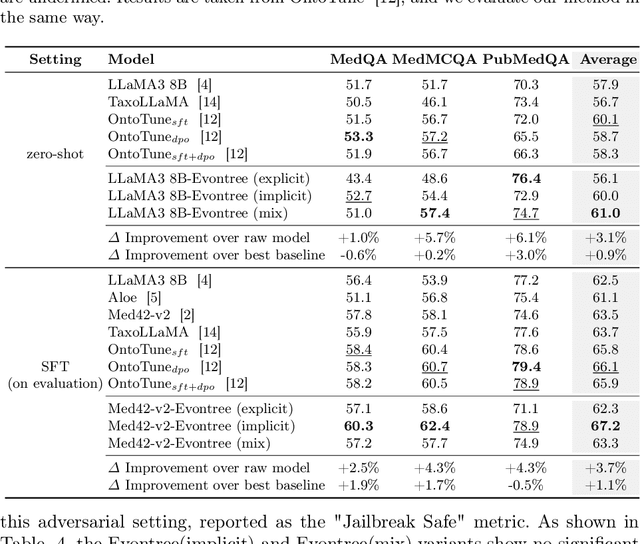
Large language models (LLMs) have demonstrated exceptional capabilities across multiple domains by leveraging massive pre-training and curated fine-tuning data. However, in data-sensitive fields such as healthcare, the lack of high-quality, domain-specific training corpus hinders LLMs' adaptation for specialized applications. Meanwhile, domain experts have distilled domain wisdom into ontology rules, which formalize relationships among concepts and ensure the integrity of knowledge management repositories. Viewing LLMs as implicit repositories of human knowledge, we propose Evontree, a novel framework that leverages a small set of high-quality ontology rules to systematically extract, validate, and enhance domain knowledge within LLMs, without requiring extensive external datasets. Specifically, Evontree extracts domain ontology from raw models, detects inconsistencies using two core ontology rules, and reinforces the refined knowledge via self-distilled fine-tuning. Extensive experiments on medical QA benchmarks with Llama3-8B-Instruct and Med42-v2 demonstrate consistent outperformance over both unmodified models and leading supervised baselines, achieving up to a 3.7% improvement in accuracy. These results confirm the effectiveness, efficiency, and robustness of our approach for low-resource domain adaptation of LLMs.
Multi-modal Knowledge Graph Generation with Semantics-enriched Prompts
Apr 18, 2025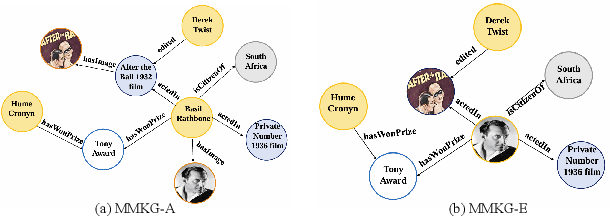
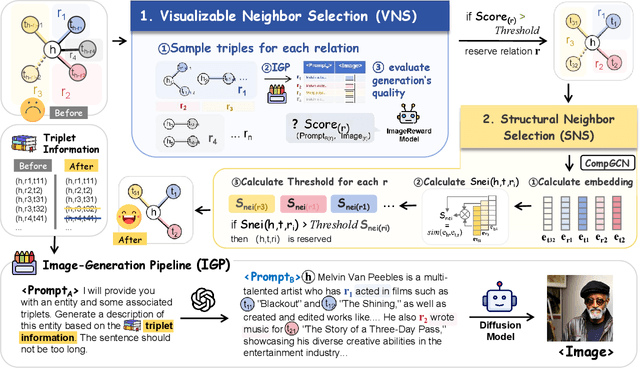
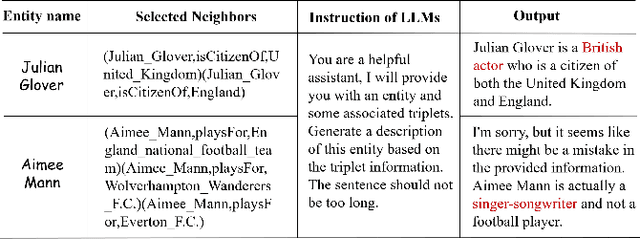

Multi-modal Knowledge Graphs (MMKGs) have been widely applied across various domains for knowledge representation. However, the existing MMKGs are significantly fewer than required, and their construction faces numerous challenges, particularly in ensuring the selection of high-quality, contextually relevant images for knowledge graph enrichment. To address these challenges, we present a framework for constructing MMKGs from conventional KGs. Furthermore, to generate higher-quality images that are more relevant to the context in the given knowledge graph, we designed a neighbor selection method called Visualizable Structural Neighbor Selection (VSNS). This method consists of two modules: Visualizable Neighbor Selection (VNS) and Structural Neighbor Selection (SNS). The VNS module filters relations that are difficult to visualize, while the SNS module selects neighbors that most effectively capture the structural characteristics of the entity. To evaluate the quality of the generated images, we performed qualitative and quantitative evaluations on two datasets, MKG-Y and DB15K. The experimental results indicate that using the VSNS method to select neighbors results in higher-quality images that are more relevant to the knowledge graph.
Reliable Academic Conference Question Answering: A Study Based on Large Language Model
Oct 19, 2023



The rapid growth of computer science has led to a proliferation of research presented at academic conferences, fostering global scholarly communication. Researchers consistently seek accurate, current information about these events at all stages. This data surge necessitates an intelligent question-answering system to efficiently address researchers' queries and ensure awareness of the latest advancements. The information of conferences is usually published on their official website, organized in a semi-structured way with a lot of text. To address this need, we have developed the ConferenceQA dataset for 7 diverse academic conferences with human annotations. Firstly, we employ a combination of manual and automated methods to organize academic conference data in a semi-structured JSON format. Subsequently, we annotate nearly 100 question-answer pairs for each conference. Each pair is classified into four different dimensions. To ensure the reliability of the data, we manually annotate the source of each answer. In light of recent advancements, Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks. They have demonstrated impressive capabilities in information-seeking question answering after instruction fine-tuning, and as such, we present our conference QA study based on LLM. Due to hallucination and outdated knowledge of LLMs, we adopt retrieval based methods to enhance LLMs' question-answering abilities. We have proposed a structure-aware retrieval method, specifically designed to leverage inherent structural information during the retrieval process. Empirical validation on the ConferenceQA dataset has demonstrated the effectiveness of this method. The dataset and code are readily accessible on https://github.com/zjukg/ConferenceQA.