 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMIC: Mitigating Visual Modality Collapse in Universal Multimodal Retrieval While Avoiding Semantic Misalignment
Apr 23, 2026Universal Multimodal Retrieval (UMR) aims to map different modalities (e.g., visual and textual) into a shared embedding space for multi-modal retrieval. Existing UMR methods can be broadly divided into two categories: early-fusion approaches, such as Marvel, which projects visual features into the language model (LM) space for integrating with text modality, and late-fusion approaches, such as UniVL-DR, which encode visual and textual inputs using separate encoders and obtain fused embeddings through addition. Our pilot study reveals that Marvel exhibits visual modality collapse, which is characterized by the model's tendency to disregard visual features while depending excessively on textual cues. In contrast, although UniVL-DR is less affected by this issue, it is more susceptible to semantic misalignment, where semantically related content is positioned far apart in the embedding space. To address these challenges, we propose MiMIC, which introduces two key innovations: (1) a fusion-in-decoder architecture for effective multimodal integration, and (2) robust training through single modality mixin and random caption dropout. Experiments on the WebQA+ and EVQA+ datasets, where image in documents or queries might lack captions, indicate that MiMIC consistently outperforms both early- and late-fusion baselines.
A Specialized Large Language Model for Clinical Reasoning and Diagnosis in Rare Diseases
Nov 18, 2025Rare diseases affect hundreds of millions worldwide, yet diagnosis often spans years. Convectional pipelines decouple noisy evidence extraction from downstream inferential diagnosis, and general/medical large language models (LLMs) face scarce real world electronic health records (EHRs), stale domain knowledge, and hallucinations. We assemble a large, domain specialized clinical corpus and a clinician validated reasoning set, and develop RareSeek R1 via staged instruction tuning, chain of thought learning, and graph grounded retrieval. Across multicenter EHR narratives and public benchmarks, RareSeek R1 attains state of the art accuracy, robust generalization, and stability under noisy or overlapping phenotypes. Augmented retrieval yields the largest gains when narratives pair with prioritized variants by resolving ambiguity and aligning candidates to mechanisms. Human studies show performance on par with experienced physicians and consistent gains in assistive use. Notably, transparent reasoning highlights decisive non phenotypic evidence (median 23.1%, such as imaging, interventions, functional tests) underpinning many correct diagnoses. This work advances a narrative first, knowledge integrated reasoning paradigm that shortens the diagnostic odyssey and enables auditable, clinically translatable decision support.
Self-Correction Distillation for Structured Data Question Answering
Nov 17, 2025Structured data question answering (QA), including table QA, Knowledge Graph (KG) QA, and temporal KG QA, is a pivotal research area. Advances in large language models (LLMs) have driven significant progress in unified structural QA frameworks like TrustUQA. However, these frameworks face challenges when applied to small-scale LLMs since small-scale LLMs are prone to errors in generating structured queries. To improve the structured data QA ability of small-scale LLMs, we propose a self-correction distillation (SCD) method. In SCD, an error prompt mechanism (EPM) is designed to detect errors and provide customized error messages during inference, and a two-stage distillation strategy is designed to transfer large-scale LLMs' query-generation and error-correction capabilities to small-scale LLM. Experiments across 5 benchmarks with 3 structured data types demonstrate that our SCD achieves the best performance and superior generalization on small-scale LLM (8B) compared to other distillation methods, and closely approaches the performance of GPT4 on some datasets. Furthermore, large-scale LLMs equipped with EPM surpass the state-of-the-art results on most datasets.
BoRe-Depth: Self-supervised Monocular Depth Estimation with Boundary Refinement for Embedded Systems
Nov 06, 2025



Depth estimation is one of the key technologies for realizing 3D perception in unmanned systems. Monocular depth estimation has been widely researched because of its low-cost advantage, but the existing methods face the challenges of poor depth estimation performance and blurred object boundaries on embedded systems. In this paper, we propose a novel monocular depth estimation model, BoRe-Depth, which contains only 8.7M parameters. It can accurately estimate depth maps on embedded systems and significantly improves boundary quality. Firstly, we design an Enhanced Feature Adaptive Fusion Module (EFAF) which adaptively fuses depth features to enhance boundary detail representation. Secondly, we integrate semantic knowledge into the encoder to improve the object recognition and boundary perception capabilities. Finally, BoRe-Depth is deployed on NVIDIA Jetson Orin, and runs efficiently at 50.7 FPS. We demonstrate that the proposed model significantly outperforms previous lightweight models on multiple challenging datasets, and we provide detailed ablation studies for the proposed methods. The code is available at https://github.com/liangxiansheng093/BoRe-Depth.
Evontree: Ontology Rule-Guided Self-Evolution of Large Language Models
Oct 30, 2025
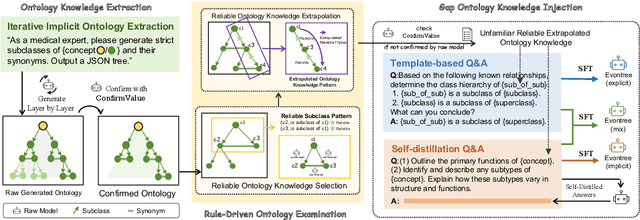
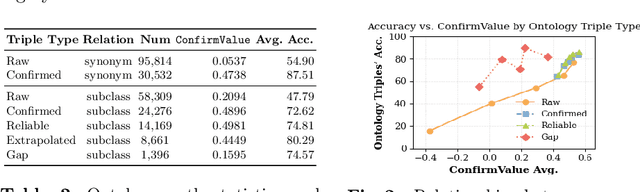
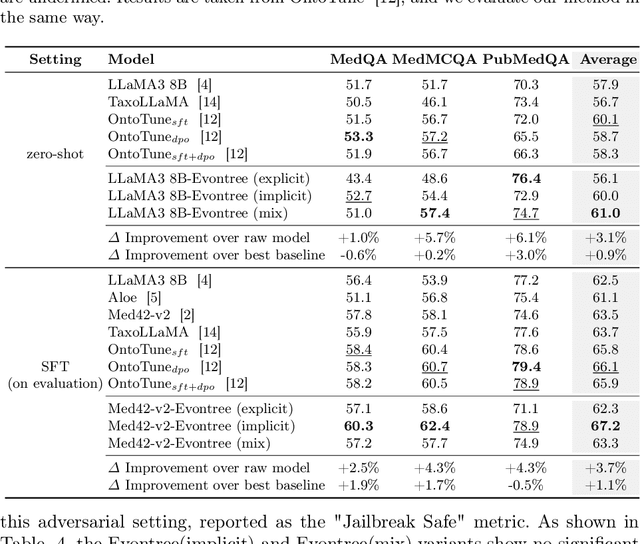
Large language models (LLMs) have demonstrated exceptional capabilities across multiple domains by leveraging massive pre-training and curated fine-tuning data. However, in data-sensitive fields such as healthcare, the lack of high-quality, domain-specific training corpus hinders LLMs' adaptation for specialized applications. Meanwhile, domain experts have distilled domain wisdom into ontology rules, which formalize relationships among concepts and ensure the integrity of knowledge management repositories. Viewing LLMs as implicit repositories of human knowledge, we propose Evontree, a novel framework that leverages a small set of high-quality ontology rules to systematically extract, validate, and enhance domain knowledge within LLMs, without requiring extensive external datasets. Specifically, Evontree extracts domain ontology from raw models, detects inconsistencies using two core ontology rules, and reinforces the refined knowledge via self-distilled fine-tuning. Extensive experiments on medical QA benchmarks with Llama3-8B-Instruct and Med42-v2 demonstrate consistent outperformance over both unmodified models and leading supervised baselines, achieving up to a 3.7% improvement in accuracy. These results confirm the effectiveness, efficiency, and robustness of our approach for low-resource domain adaptation of LLMs.
RTQA : Recursive Thinking for Complex Temporal Knowledge Graph Question Answering with Large Language Models
Sep 04, 2025Current temporal knowledge graph question answering (TKGQA) methods primarily focus on implicit temporal constraints, lacking the capability of handling more complex temporal queries, and struggle with limited reasoning abilities and error propagation in decomposition frameworks. We propose RTQA, a novel framework to address these challenges by enhancing reasoning over TKGs without requiring training. Following recursive thinking, RTQA recursively decomposes questions into sub-problems, solves them bottom-up using LLMs and TKG knowledge, and employs multi-path answer aggregation to improve fault tolerance. RTQA consists of three core components: the Temporal Question Decomposer, the Recursive Solver, and the Answer Aggregator. Experiments on MultiTQ and TimelineKGQA benchmarks demonstrate significant Hits@1 improvements in "Multiple" and "Complex" categories, outperforming state-of-the-art methods. Our code and data are available at https://github.com/zjukg/RTQA.
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Aug 27, 2024



This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
CMed-GPT: Prompt Tuning for Entity-Aware Chinese Medical Dialogue Generation
Nov 24, 2023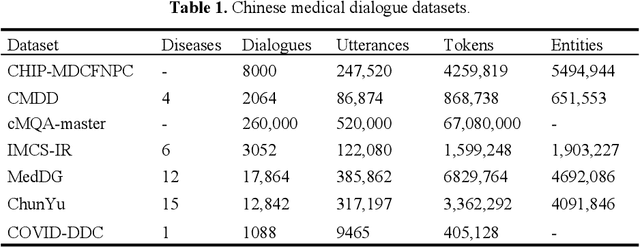
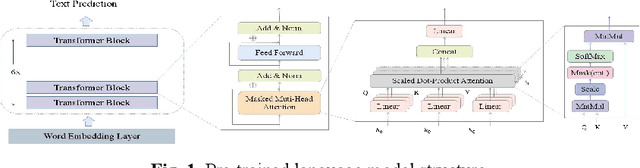
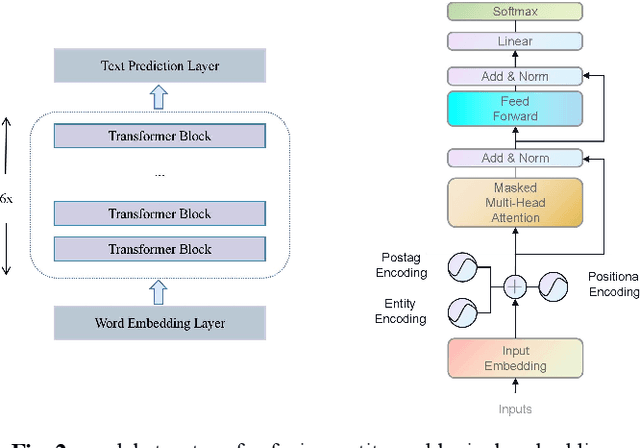

Medical dialogue generation relies on natural language generation techniques to enable online medical consultations. Recently, the widespread adoption of large-scale models in the field of natural language processing has facilitated rapid advancements in this technology. Existing medical dialogue models are mostly based on BERT and pre-trained on English corpora, but there is a lack of high-performing models on the task of Chinese medical dialogue generation. To solve the above problem, this paper proposes CMed-GPT, which is the GPT pre-training language model based on Chinese medical domain text. The model is available in two versions, namely, base and large, with corresponding perplexity values of 8.64 and 8.01. Additionally, we incorporate lexical and entity embeddings into the dialogue text in a uniform manner to meet the requirements of downstream dialogue generation tasks. By applying both fine-tuning and p-tuning to CMed-GPT, we lowered the PPL from 8.44 to 7.35. This study not only confirms the exceptional performance of the CMed-GPT model in generating Chinese biomedical text but also highlights the advantages of p-tuning over traditional fine-tuning with prefix prompts. Furthermore, we validate the significance of incorporating external information in medical dialogue generation, which enhances the quality of dialogue generation.
Using wearable device-based machine learning models to autonomously identify older adults with poor cognition
Aug 28, 2023



Conducting cognitive tests is time-consuming for patients and clinicians. Wearable device-based prediction models allow for continuous health monitoring under normal living conditions and could offer an alternative to identifying older adults with cognitive impairments for early interventions. In this study, we first derived novel wearable-based features related to circadian rhythms, ambient light exposure, physical activity levels, sleep, and signal processing. Then, we quantified the ability of wearable-based machine-learning models to predict poor cognition based on outcomes from the Digit Symbol Substitution Test (DSST), the Consortium to Establish a Registry for Alzheimers Disease Word-Learning subtest (CERAD-WL), and the Animal Fluency Test (AFT). We found that the wearable-based models had significantly higher AUCs when predicting all three cognitive outcomes compared to benchmark models containing age, sex, education, marital status, household income, diabetic status, depression symptoms, and functional independence scores. In addition to uncovering previously unidentified wearable-based features that are predictive of poor cognition such as the standard deviation of the midpoints of each persons most active 10-hour periods and least active 5-hour periods, our paper provides proof-of-concept that wearable-based machine learning models can be used to autonomously screen older adults for possible cognitive impairments. Such models offer cost-effective alternatives to conducting initial screenings manually in clinical settings.
Grant-Free NOMA-OTFS Paradigm: Enabling Efficient Ubiquitous Access for LEO Satellite Internet-of-Things
Sep 25, 2022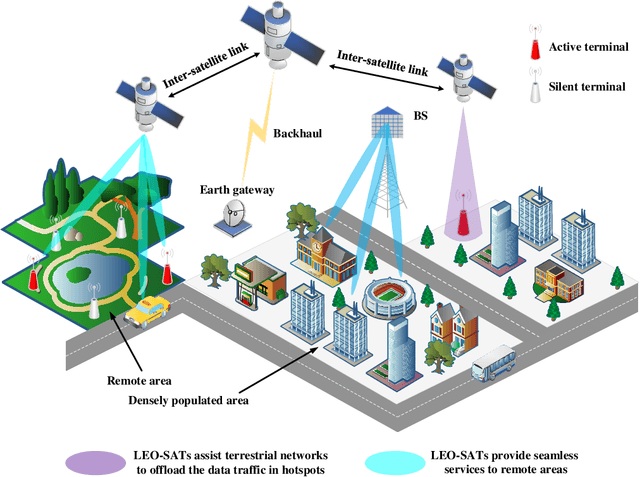
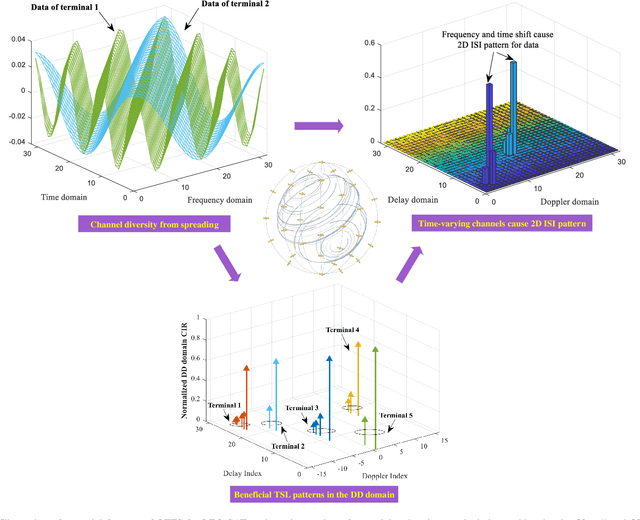
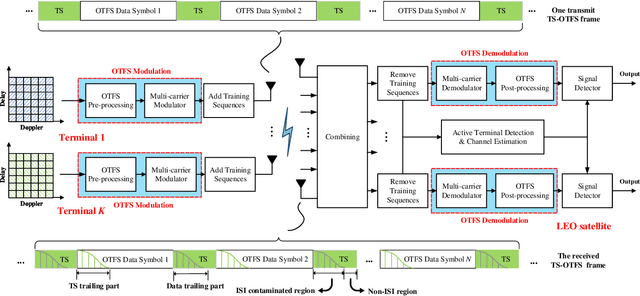
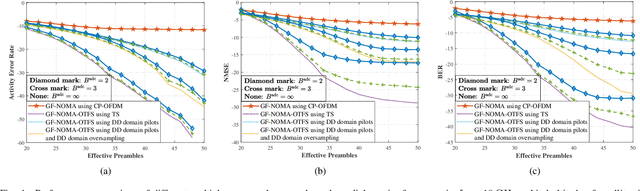
With the blooming of Internet-of-Things (IoT), we are witnessing an explosion in the number of IoT terminals, triggering an unprecedented demand for ubiquitous wireless access globally. In this context, the emerging low-Earth-orbit satellites (LEO-SATs) have been regarded as a promising enabler to complement terrestrial wireless networks in providing ubiquitous connectivity and bridging the ever-growing digital divide in the expected next-generation wireless communications. Nevertheless, the stringent requirements posed by LEO-SATs have imposed significant challenges to the current multiple access schemes and led to an emerging paradigm shift in system design. In this article, we first provide a comprehensive overview of the state-of-the-art multiple access schemes and investigate their limitations in the context of LEO-SATs. To this end, we propose the amalgamation of the grant-free non-orthogonal multiple access (GF-NOMA) paradigm and the orthogonal time frequency space (OTFS) waveform, for simplifying the connection procedure with reduced access latency and enhanced Doppler-robustness. Critical open challenging issues and future directions are finally presented for further technical development.