 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Scientists Are Only as Good as Their Evidence: A Stratified Ablation of Proprietary Data and Reasoning Skills in Drug-Asset Valuation
Jun 08, 2026AI Scientist agents are often evaluated as if capability were mainly a function of model quality, prompting, or reasoning scaffolds. We test a different hypothesis in drug-asset valuation: for knowledge-intensive scientific decisions, the limiting factor is often the evidence substrate the agent can access. We run a controlled three-arm ablation on a production valuation agent: A is a plain web-only LLM analyst, B adds public structured tools plus a 14-dimension valuation playbook, verifier, objectivity policy and red-team, and C adds the proprietary Noah AI corpus of curated pipeline, trial and deal intelligence. Across a 13-asset stratified benchmark, B improves calibration and audit discipline: tier-in-range accuracy rises from 0.80 to 0.89 and objectivity from 3.16 to 3.30. But B does not remove the factual ceiling. Under capability-superset accounting, A and B recover only 0.25 and 0.38 of the curated gold competitive record, while C recovers 0.96; on the curated long-tail subset, C reaches 0.93 vs. 0.26/0.30. Raw blind-panel decision quality is similar for A and B (7.01 vs. 6.96), so we introduce completeness-aware decision utility: informed decision-quality = decision-quality x gold-coverage. On this metric, C reaches 7.43 vs. 1.76/2.57 for A/B. Even a perfect non-proprietary-data report would be capped at 3.83 by B's coverage. The result is not that reasoning scaffolds are unimportant; they improve calibration and discipline. Rather, proprietary evidence sets the upper bound of what the AI Scientist can know and therefore decide.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
SparseST: Exploiting Data Sparsity in Spatiotemporal Modeling and Prediction
Nov 18, 2025Spatiotemporal data mining (STDM) has a wide range of applications in various complex physical systems (CPS), i.e., transportation, manufacturing, healthcare, etc. Among all the proposed methods, the Convolutional Long Short-Term Memory (ConvLSTM) has proved to be generalizable and extendable in different applications and has multiple variants achieving state-of-the-art performance in various STDM applications. However, ConvLSTM and its variants are computationally expensive, which makes them inapplicable in edge devices with limited computational resources. With the emerging need for edge computing in CPS, efficient AI is essential to reduce the computational cost while preserving the model performance. Common methods of efficient AI are developed to reduce redundancy in model capacity (i.e., model pruning, compression, etc.). However, spatiotemporal data mining naturally requires extensive model capacity, as the embedded dependencies in spatiotemporal data are complex and hard to capture, which limits the model redundancy. Instead, there is a fairly high level of data and feature redundancy that introduces an unnecessary computational burden, which has been largely overlooked in existing research. Therefore, we developed a novel framework SparseST, that pioneered in exploiting data sparsity to develop an efficient spatiotemporal model. In addition, we explore and approximate the Pareto front between model performance and computational efficiency by designing a multi-objective composite loss function, which provides a practical guide for practitioners to adjust the model according to computational resource constraints and the performance requirements of downstream tasks.
Neural Radiance and Gaze Fields for Visual Attention Modeling in 3D Environments
Mar 10, 2025



We introduce Neural Radiance and Gaze Fields (NeRGs) as a novel approach for representing visual attention patterns in 3D scenes. Our system renders a 2D view of a 3D scene with a pre-trained Neural Radiance Field (NeRF) and visualizes the gaze field for arbitrary observer positions, which may be decoupled from the render camera perspective. We achieve this by augmenting a standard NeRF with an additional neural network that models the gaze probability distribution. The output of a NeRG is a rendered image of the scene viewed from the camera perspective and a pixel-wise salience map representing conditional probability that an observer fixates on a given surface within the 3D scene as visible in the rendered image. Much like how NeRFs perform novel view synthesis, NeRGs enable the reconstruction of gaze patterns from arbitrary perspectives within complex 3D scenes. To ensure consistent gaze reconstructions, we constrain gaze prediction on the 3D structure of the scene and model gaze occlusion due to intervening surfaces when the observer's viewpoint is decoupled from the rendering camera. For training, we leverage ground truth head pose data from skeleton tracking data or predictions from 2D salience models. We demonstrate the effectiveness of NeRGs in a real-world convenience store setting, where head pose tracking data is available.
Uni-3DAD: GAN-Inversion Aided Universal 3D Anomaly Detection on Model-free Products
Aug 29, 2024



Anomaly detection is a long-standing challenge in manufacturing systems. Traditionally, anomaly detection has relied on human inspectors. However, 3D point clouds have gained attention due to their robustness to environmental factors and their ability to represent geometric data. Existing 3D anomaly detection methods generally fall into two categories. One compares scanned 3D point clouds with design files, assuming these files are always available. However, such assumptions are often violated in many real-world applications where model-free products exist, such as fresh produce (i.e., ``Cookie", ``Potato", etc.), dentures, bone, etc. The other category compares patches of scanned 3D point clouds with a library of normal patches named memory bank. However, those methods usually fail to detect incomplete shapes, which is a fairly common defect type (i.e., missing pieces of different products). The main challenge is that missing areas in 3D point clouds represent the absence of scanned points. This makes it infeasible to compare the missing region with existing point cloud patches in the memory bank. To address these two challenges, we proposed a unified, unsupervised 3D anomaly detection framework capable of identifying all types of defects on model-free products. Our method integrates two detection modules: a feature-based detection module and a reconstruction-based detection module. Feature-based detection covers geometric defects, such as dents, holes, and cracks, while the reconstruction-based method detects missing regions. Additionally, we employ a One-class Support Vector Machine (OCSVM) to fuse the detection results from both modules. The results demonstrate that (1) our proposed method outperforms the state-of-the-art methods in identifying incomplete shapes and (2) it still maintains comparable performance with the SOTA methods in detecting all other types of anomalies.
Spatiotemporal Predictions of Toxic Urban Plumes Using Deep Learning
May 30, 2024



Industrial accidents, chemical spills, and structural fires can release large amounts of harmful materials that disperse into urban atmospheres and impact populated areas. Computer models are typically used to predict the transport of toxic plumes by solving fluid dynamical equations. However, these models can be computationally expensive due to the need for many grid cells to simulate turbulent flow and resolve individual buildings and streets. In emergency response situations, alternative methods are needed that can run quickly and adequately capture important spatiotemporal features. Here, we present a novel deep learning model called ST-GasNet that was inspired by the mathematical equations that govern the behavior of plumes as they disperse through the atmosphere. ST-GasNet learns the spatiotemporal dependencies from a limited set of temporal sequences of ground-level toxic urban plumes generated by a high-resolution large eddy simulation model. On independent sequences, ST-GasNet accurately predicts the late-time spatiotemporal evolution, given the early-time behavior as an input, even for cases when a building splits a large plume into smaller plumes. By incorporating large-scale wind boundary condition information, ST-GasNet achieves a prediction accuracy of at least 90% on test data for the entire prediction period.
ADs: Active Data-sharing for Data Quality Assurance in Advanced Manufacturing Systems
Mar 31, 2024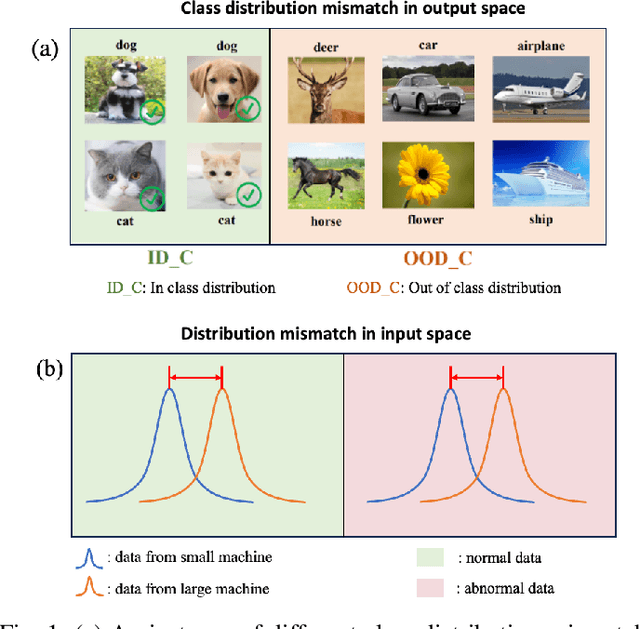
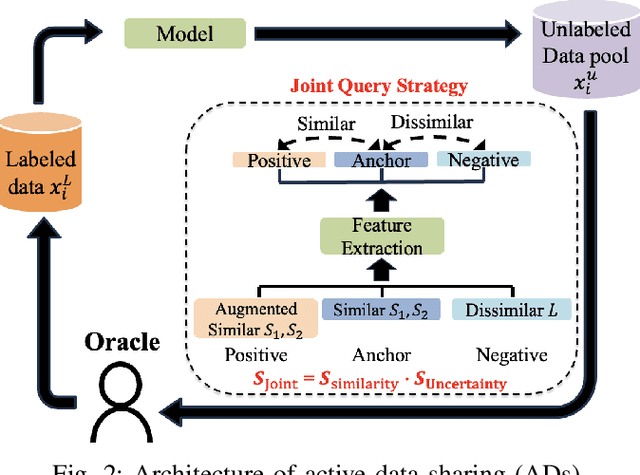
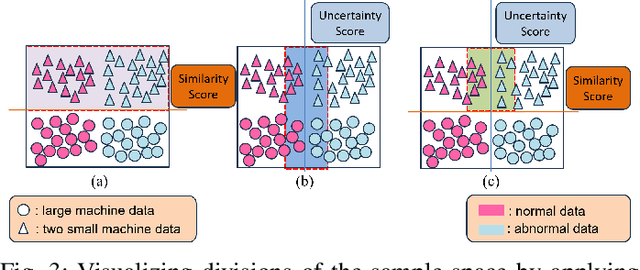
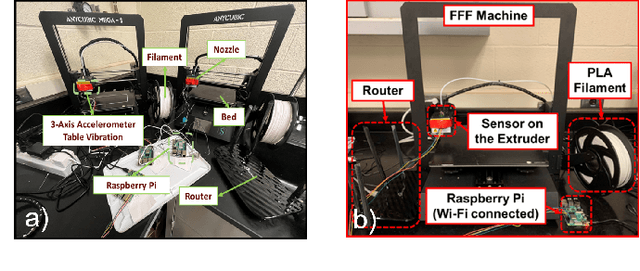
Machine learning (ML) methods are widely used in industrial applications, which usually require a large amount of training data. However, data collection needs extensive time costs and investments in the manufacturing system, and data scarcity commonly exists. Therefore, data-sharing is widely enabled among multiple machines with similar functionality to augment the dataset for building ML methods. However, distribution mismatch inevitably exists in their data due to different working conditions, while the ML methods are assumed to be built and tested on the dataset following the same distribution. Thus, an Active Data-sharing (ADs) framework is proposed to ensure the quality of the shared data among multiple machines. It is designed to simultaneously select the most informative data points benefiting the downstream tasks and mitigate the distribution mismatch among all selected data points. The proposed method is validated on anomaly detection on in-situ monitoring data from three additive manufacturing processes.
Order Estimation of Linear-Phase FIR Filters for DAC Equalization in Multiple Nyquist Bands
Feb 19, 2024This letter considers the design of linear-phase finite-length impulse response (FIR) filters for equalization of the frequency responses of digital-to-analog converters (DACs). The letter derives estimates for the filter orders required, as functions of the bandwidth and equalization accuracy, for four DAC pulses that are used in DACs in multiple Nyquist bands. The estimates are derived through a large set of minimax-optimal equalizers and the use of symbolic regression followed by minimax-optimal curve fitting for further enhancement. Design examples included demonstrate the accuracy of the proposed estimates. In addition, the letter discusses the appropriateness of the four types of linear-phase FIR filters, for the different equalizer cases, as well as the corresponding properties of the equalized systems.
H2G2-Net: A Hierarchical Heterogeneous Graph Generative Network Framework for Discovery of Multi-Modal Physiological Responses
Jan 05, 2024Discovering human cognitive and emotional states using multi-modal physiological signals draws attention across various research applications. Physiological responses of the human body are influenced by human cognition and commonly used to analyze cognitive states. From a network science perspective, the interactions of these heterogeneous physiological modalities in a graph structure may provide insightful information to support prediction of cognitive states. However, there is no clue to derive exact connectivity between heterogeneous modalities and there exists a hierarchical structure of sub-modalities. Existing graph neural networks are designed to learn on non-hierarchical homogeneous graphs with pre-defined graph structures; they failed to learn from hierarchical, multi-modal physiological data without a pre-defined graph structure. To this end, we propose a hierarchical heterogeneous graph generative network (H2G2-Net) that automatically learns a graph structure without domain knowledge, as well as a powerful representation on the hierarchical heterogeneous graph in an end-to-end fashion. We validate the proposed method on the CogPilot dataset that consists of multi-modal physiological signals. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art GNNs by 5%-20% in prediction accuracy.
Flow Completion Network: Inferring the Fluid Dynamics from Incomplete Flow Information using Graph Neural Networks
May 10, 2022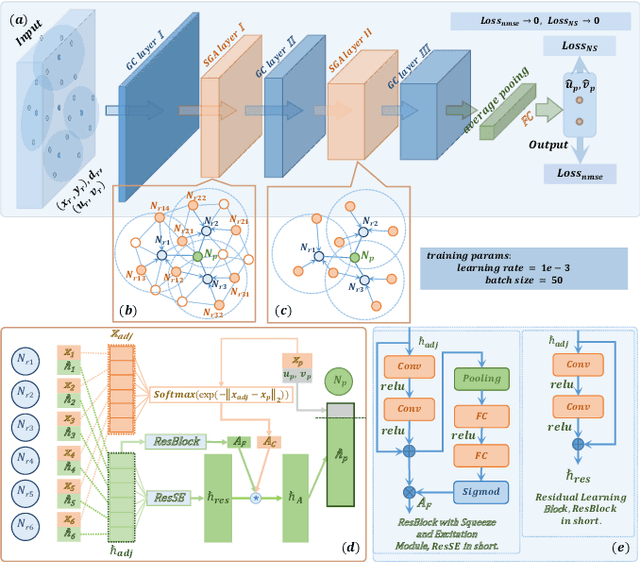
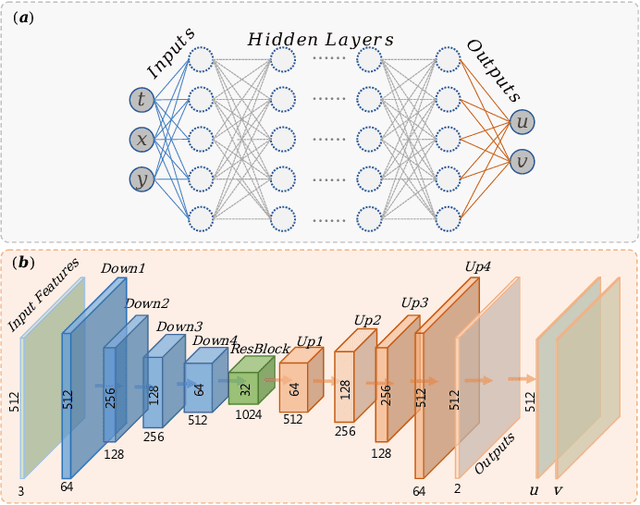
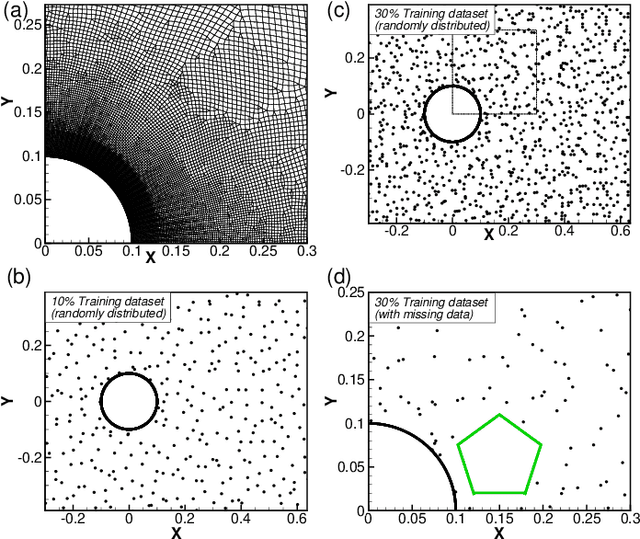
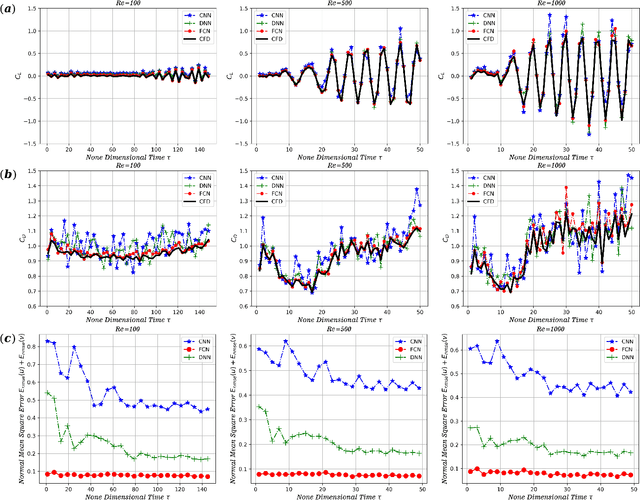
This paper introduces a novel neural network -- the flow completion network (FCN) -- to infer the fluid dynamics, including the flow field and the force acting on the body, from the incomplete data based on Graph Convolution Attention Network. The FCN is composed of several graph convolution layers and spatial attention layers. It is designed to infer the velocity field and the vortex force contribution of the flow field when combined with the vortex force map (VFM) method. Compared with other neural networks adopted in fluid dynamics, the FCN is capable of dealing with both structured data and unstructured data. The performance of the proposed FCN is assessed by the computational fluid dynamics (CFD) data on the flow field around a circular cylinder. The force coefficients predicted by our model are validated against those obtained directly from CFD. Moreover, it is shown that our model effectively utilizes the existing flow field information and the gradient information simultaneously, giving a better performance than the traditional CNN-based and DNN-based models.