 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADs: Active Data-sharing for Data Quality Assurance in Advanced Manufacturing Systems
Paper and Code
Mar 31, 2024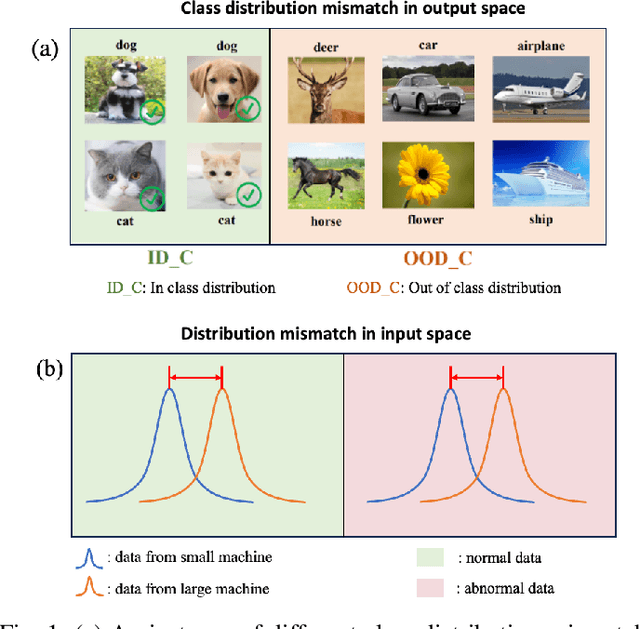
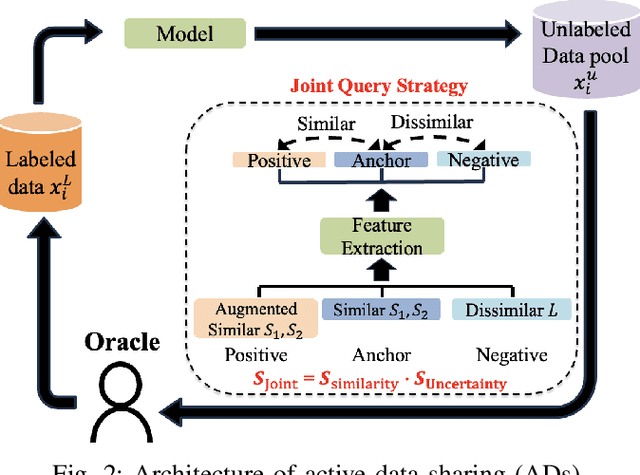
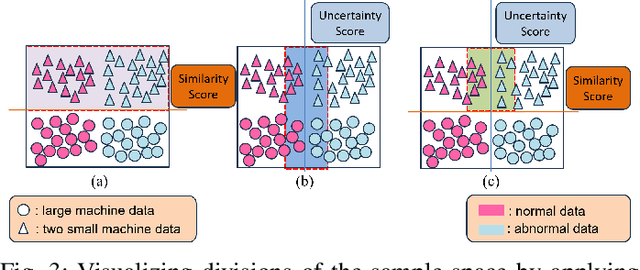
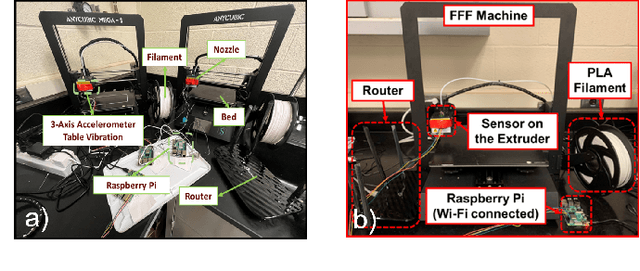
Machine learning (ML) methods are widely used in industrial applications, which usually require a large amount of training data. However, data collection needs extensive time costs and investments in the manufacturing system, and data scarcity commonly exists. Therefore, data-sharing is widely enabled among multiple machines with similar functionality to augment the dataset for building ML methods. However, distribution mismatch inevitably exists in their data due to different working conditions, while the ML methods are assumed to be built and tested on the dataset following the same distribution. Thus, an Active Data-sharing (ADs) framework is proposed to ensure the quality of the shared data among multiple machines. It is designed to simultaneously select the most informative data points benefiting the downstream tasks and mitigate the distribution mismatch among all selected data points. The proposed method is validated on anomaly detection on in-situ monitoring data from three additive manufacturing processes.