 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Graph Unlearning
Nov 12, 2025Spatio-temporal graphs are widely used in modeling complex dynamic processes such as traffic forecasting, molecular dynamics, and healthcare monitoring. Recently, stringent privacy regulations such as GDPR and CCPA have introduced significant new challenges for existing spatio-temporal graph models, requiring complete unlearning of unauthorized data. Since each node in a spatio-temporal graph diffuses information globally across both spatial and temporal dimensions, existing unlearning methods primarily designed for static graphs and localized data removal cannot efficiently erase a single node without incurring costs nearly equivalent to full model retraining. Therefore, an effective approach for complete spatio-temporal graph unlearning is a pressing need. To address this, we propose CallosumNet, a divide-and-conquer spatio-temporal graph unlearning framework inspired by the corpus callosum structure that facilitates communication between the brain's two hemispheres. CallosumNet incorporates two novel techniques: (1) Enhanced Subgraph Construction (ESC), which adaptively constructs multiple localized subgraphs based on several factors, including biologically-inspired virtual ganglions; and (2) Global Ganglion Bridging (GGB), which reconstructs global spatio-temporal dependencies from these localized subgraphs, effectively restoring the full graph representation. Empirical results on four diverse real-world datasets show that CallosumNet achieves complete unlearning with only 1%-2% relative MAE loss compared to the gold model, significantly outperforming state-of-the-art baselines. Ablation studies verify the effectiveness of both proposed techniques.
ETT-CKGE: Efficient Task-driven Tokens for Continual Knowledge Graph Embedding
Jun 09, 2025Continual Knowledge Graph Embedding (CKGE) seeks to integrate new knowledge while preserving past information. However, existing methods struggle with efficiency and scalability due to two key limitations: (1) suboptimal knowledge preservation between snapshots caused by manually designed node/relation importance scores that ignore graph dependencies relevant to the downstream task, and (2) computationally expensive graph traversal for node/relation importance calculation, leading to slow training and high memory overhead. To address these limitations, we introduce ETT-CKGE (Efficient, Task-driven, Tokens for Continual Knowledge Graph Embedding), a novel task-guided CKGE method that leverages efficient task-driven tokens for efficient and effective knowledge transfer between snapshots. Our method introduces a set of learnable tokens that directly capture task-relevant signals, eliminating the need for explicit node scoring or traversal. These tokens serve as consistent and reusable guidance across snapshots, enabling efficient token-masked embedding alignment between snapshots. Importantly, knowledge transfer is achieved through simple matrix operations, significantly reducing training time and memory usage. Extensive experiments across six benchmark datasets demonstrate that ETT-CKGE consistently achieves superior or competitive predictive performance, while substantially improving training efficiency and scalability compared to state-of-the-art CKGE methods. The code is available at: https://github.com/lijingzhu1/ETT-CKGE/tree/main
Accessible and Portable LLM Inference by Compiling Computational Graphs into SQL
Feb 05, 2025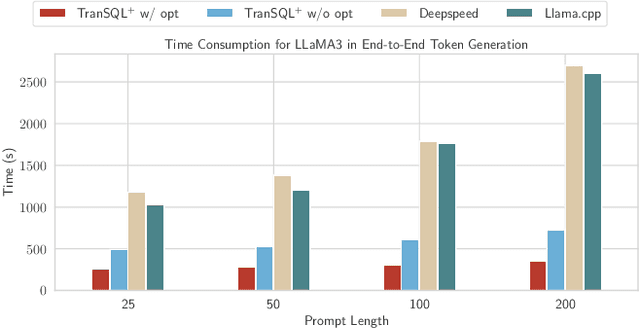
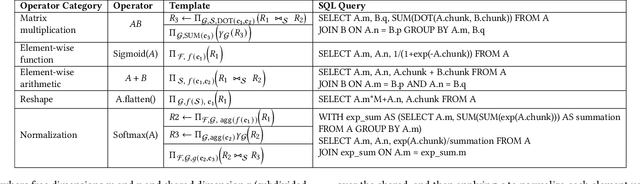
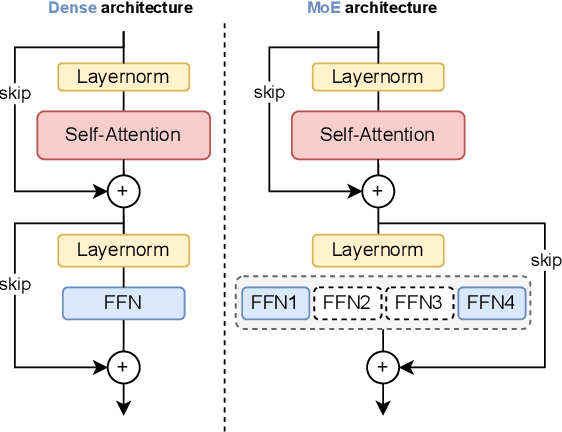
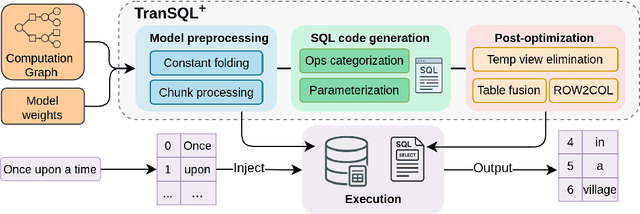
Serving large language models (LLMs) often demands specialized hardware, dedicated frameworks, and substantial development efforts, which restrict their accessibility, especially for edge devices and organizations with limited technical resources. We propose a novel compiler that translates LLM inference graphs into SQL queries, enabling relational databases, one of the most widely used and mature software systems globally, to serve as the runtime. By mapping neural operators such as matrix multiplication and attention into relational primitives like joins and aggregations, our approach leverages database capabilities, including disk-based data management and native caching. Supporting key transformer components, such as attention mechanisms and key-value caching, our system generates SQL pipelines for end-to-end LLM inference. Using the Llama3 family as a case study, we demonstrate up to 30x speedup in token generation for memory-constrained scenarios comparable to competitive CPU-based frameworks. Our work offers an accessible, portable, and efficient solution, facilitating the serving of LLMs across diverse deployment environments.
Ilargi: a GPU Compatible Factorized ML Model Training Framework
Feb 04, 2025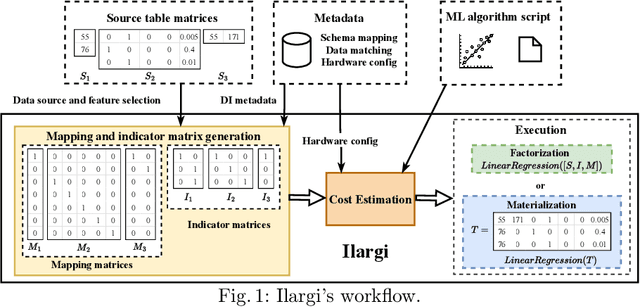

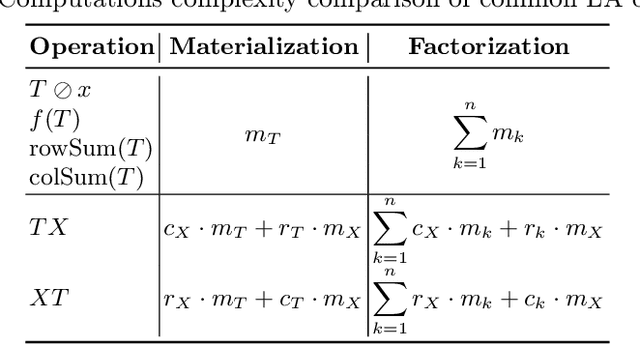

The machine learning (ML) training over disparate data sources traditionally involves materialization, which can impose substantial time and space overhead due to data movement and replication. Factorized learning, which leverages direct computation on disparate sources through linear algebra (LA) rewriting, has emerged as a viable alternative to improve computational efficiency. However, the adaptation of factorized learning to leverage the full capabilities of modern LA-friendly hardware like GPUs has been limited, often requiring manual intervention for algorithm compatibility. This paper introduces Ilargi, a novel factorized learning framework that utilizes matrix-represented data integration (DI) metadata to facilitate automatic factorization across CPU and GPU environments without the need for costly relational joins. Ilargi incorporates an ML-based cost estimator to intelligently selects between factorization and materialization based on data properties, algorithm complexity, hardware environments, and their interactions. This strategy ensures up to 8.9x speedups on GPUs and achieves over 20% acceleration in batch ML training workloads, thereby enhancing the practicability of ML training across diverse data integration scenarios and hardware platforms. To our knowledge, this work is the very first effort in GPU-compatible factorized learning.
KGIF: Optimizing Relation-Aware Recommendations with Knowledge Graph Information Fusion
Jan 07, 2025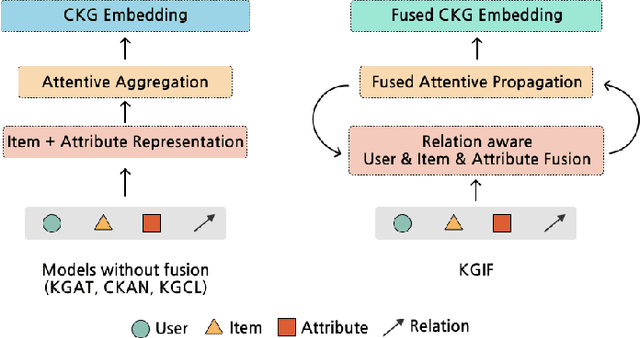
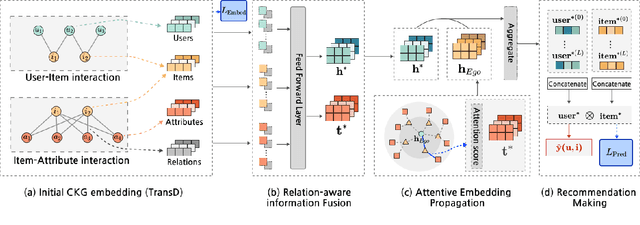
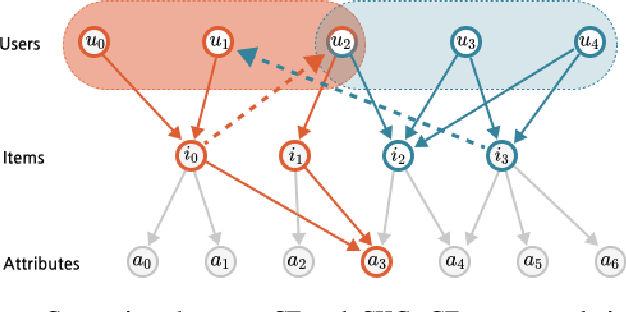
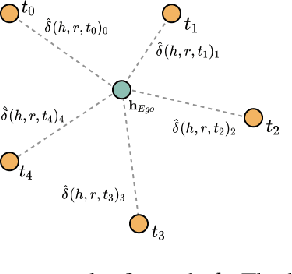
While deep-learning-enabled recommender systems demonstrate strong performance benchmarks, many struggle to adapt effectively in real-world environments due to limited use of user-item relationship data and insufficient transparency in recommendation generation. Traditional collaborative filtering approaches fail to integrate multifaceted item attributes, and although Factorization Machines account for item-specific details, they overlook broader relational patterns. Collaborative knowledge graph-based models have progressed by embedding user-item interactions with item-attribute relationships, offering a holistic perspective on interconnected entities. However, these models frequently aggregate attribute and interaction data in an implicit manner, leaving valuable relational nuances underutilized. This study introduces the Knowledge Graph Attention Network with Information Fusion (KGIF), a specialized framework designed to merge entity and relation embeddings explicitly through a tailored self-attention mechanism. The KGIF framework integrates reparameterization via dynamic projection vectors, enabling embeddings to adaptively represent intricate relationships within knowledge graphs. This explicit fusion enhances the interplay between user-item interactions and item-attribute relationships, providing a nuanced balance between user-centric and item-centric representations. An attentive propagation mechanism further optimizes knowledge graph embeddings, capturing multi-layered interaction patterns. The contributions of this work include an innovative method for explicit information fusion, improved robustness for sparse knowledge graphs, and the ability to generate explainable recommendations through interpretable path visualization.
Uncertainty-Aware Out-of-Distribution Detection with Gaussian Processes
Dec 30, 2024Deep neural networks (DNNs) are often constructed under the closed-world assumption, which may fail to generalize to the out-of-distribution (OOD) data. This leads to DNNs producing overconfident wrong predictions and can result in disastrous consequences in safety-critical applications. Existing OOD detection methods mainly rely on curating a set of OOD data for model training or hyper-parameter tuning to distinguish OOD data from training data (also known as in-distribution data or InD data). However, OOD samples are not always available during the training phase in real-world applications, hindering the OOD detection accuracy. To overcome this limitation, we propose a Gaussian-process-based OOD detection method to establish a decision boundary based on InD data only. The basic idea is to perform uncertainty quantification of the unconstrained softmax scores of a DNN via a multi-class Gaussian process (GP), and then define a score function to separate InD and potential OOD data based on their fundamental differences in the posterior predictive distribution from the GP. Two case studies on conventional image classification datasets and real-world image datasets are conducted to demonstrate that the proposed method outperforms the state-of-the-art OOD detection methods when OOD samples are not observed in the training phase.
SouLLMate: An Application Enhancing Diverse Mental Health Support with Adaptive LLMs, Prompt Engineering, and RAG Techniques
Oct 17, 2024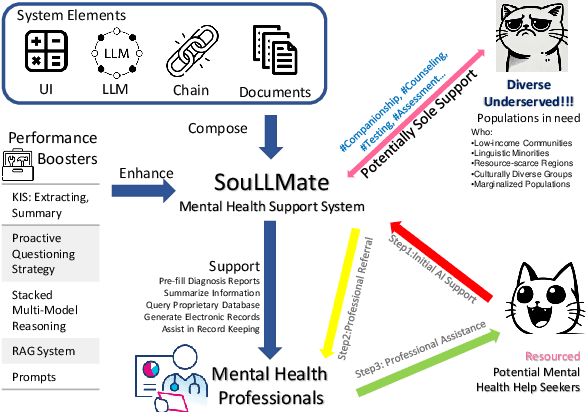
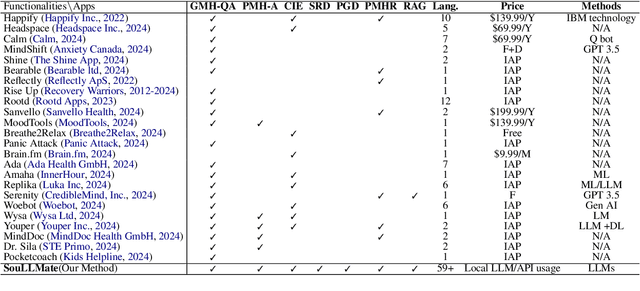
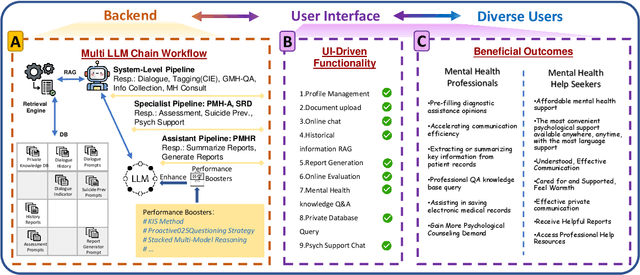

Mental health issues significantly impact individuals' daily lives, yet many do not receive the help they need even with available online resources. This study aims to provide diverse, accessible, stigma-free, personalized, and real-time mental health support through cutting-edge AI technologies. It makes the following contributions: (1) Conducting an extensive survey of recent mental health support methods to identify prevalent functionalities and unmet needs. (2) Introducing SouLLMate, an adaptive LLM-driven system that integrates LLM technologies, Chain, Retrieval-Augmented Generation (RAG), prompt engineering, and domain knowledge. This system offers advanced features such as Risk Detection and Proactive Guidance Dialogue, and utilizes RAG for personalized profile uploads and Conversational Information Extraction. (3) Developing novel evaluation approaches for preliminary assessments and risk detection via professionally annotated interview data and real-life suicide tendency data. (4) Proposing the Key Indicator Summarization (KIS), Proactive Questioning Strategy (PQS), and Stacked Multi-Model Reasoning (SMMR) methods to enhance model performance and usability through context-sensitive response adjustments, semantic coherence evaluations, and enhanced accuracy of long-context reasoning in language models. This study contributes to advancing mental health support technologies, potentially improving the accessibility and effectiveness of mental health care globally.
Automatic Identification of Driving Maneuver Patterns using a Robust Hidden Semi-Markov Models
Nov 13, 2023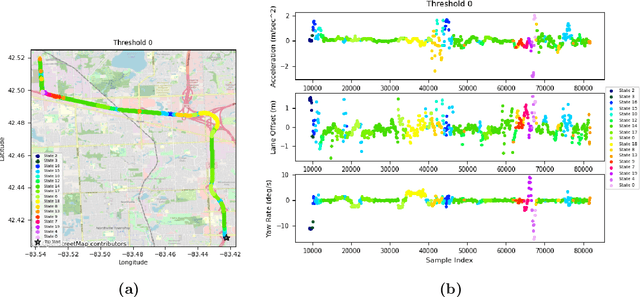

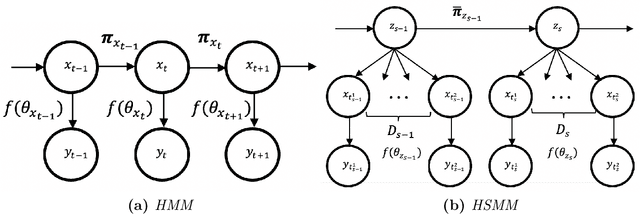
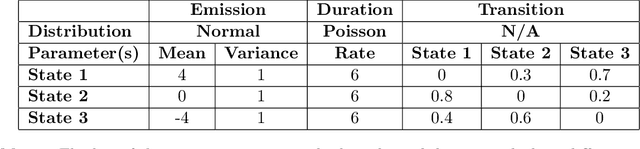
There is an increase in interest to model driving maneuver patterns via the automatic unsupervised clustering of naturalistic sequential kinematic driving data. The patterns learned are often used in transportation research areas such as eco-driving, road safety, and intelligent vehicles. One such model capable of modeling these patterns is the Hierarchical Dirichlet Process Hidden Semi-Markov Model (HDP-HSMM), as it is often used to estimate data segmentation, state duration, and transition probabilities. While this model is a powerful tool for automatically clustering observed sequential data, the existing HDP-HSMM estimation suffers from an inherent tendency to overestimate the number of states. This can result in poor estimation, which can potentially impact impact transportation research through incorrect inference of driving patterns. In this paper, a new robust HDP-HSMM (rHDP-HSMM) method is proposed to reduce the number of redundant states and improve the consistency of the model's estimation. Both a simulation study and a case study using naturalistic driving data are presented to demonstrate the effectiveness of the proposed rHDP-HSMM in identifying and inference of driving maneuver patterns.
SEE-OoD: Supervised Exploration For Enhanced Out-of-Distribution Detection
Oct 12, 2023
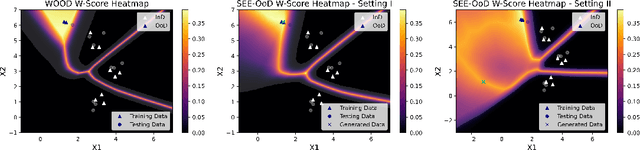
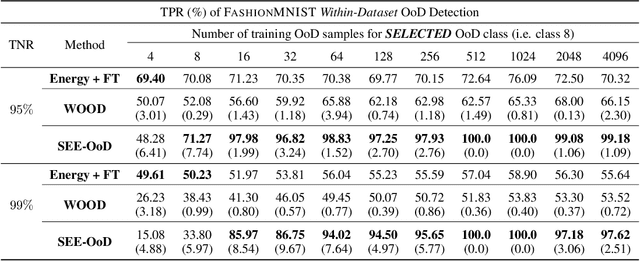
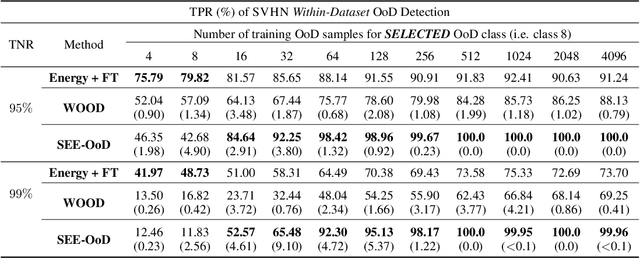
Current techniques for Out-of-Distribution (OoD) detection predominantly rely on quantifying predictive uncertainty and incorporating model regularization during the training phase, using either real or synthetic OoD samples. However, methods that utilize real OoD samples lack exploration and are prone to overfit the OoD samples at hand. Whereas synthetic samples are often generated based on features extracted from training data, rendering them less effective when the training and OoD data are highly overlapped in the feature space. In this work, we propose a Wasserstein-score-based generative adversarial training scheme to enhance OoD detection accuracy, which, for the first time, performs data augmentation and exploration simultaneously under the supervision of limited OoD samples. Specifically, the generator explores OoD spaces and generates synthetic OoD samples using feedback from the discriminator, while the discriminator exploits both the observed and synthesized samples for OoD detection using a predefined Wasserstein score. We provide theoretical guarantees that the optimal solutions of our generative scheme are statistically achievable through adversarial training in empirical settings. We then demonstrate that the proposed method outperforms state-of-the-art techniques on various computer vision datasets and exhibits superior generalizability to unseen OoD data.
Efficient Subgraph Isomorphism using Graph Topology
Sep 15, 2022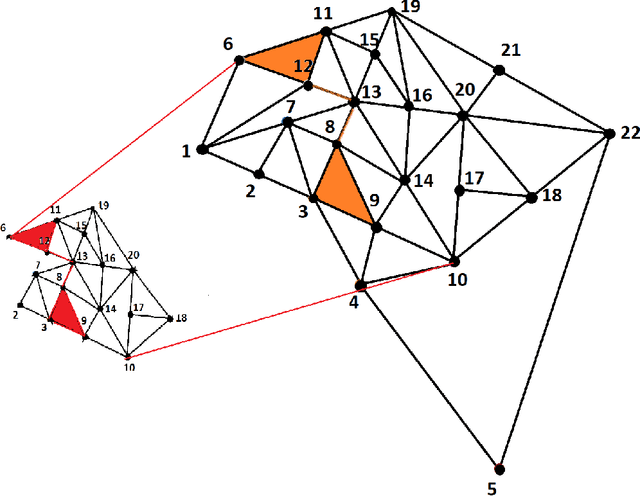
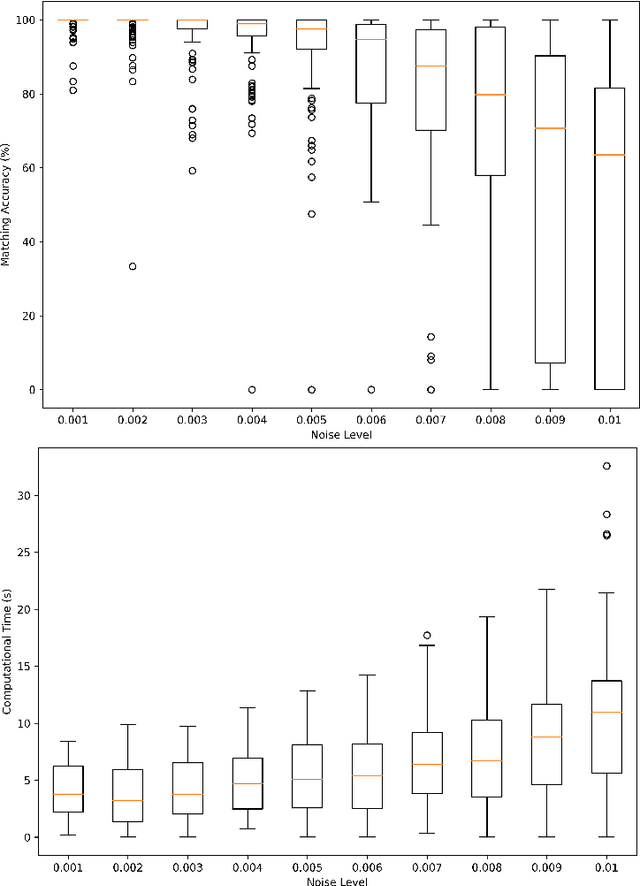

Subgraph isomorphism or subgraph matching is generally considered as an NP-complete problem, made more complex in practical applications where the edge weights take real values and are subject to measurement noise and possible anomalies. To the best of our knowledge, almost all subgraph matching methods utilize node labels to perform node-node matching. In the absence of such labels (in applications such as image matching and map matching among others), these subgraph matching methods do not work. We propose a method for identifying the node correspondence between a subgraph and a full graph in the inexact case without node labels in two steps - (a) extract the minimal unique topology preserving subset from the subgraph and find its feasible matching in the full graph, and (b) implement a consensus-based algorithm to expand the matched node set by pairing unique paths based on boundary commutativity. Going beyond the existing subgraph matching approaches, the proposed method is shown to have realistically sub-linear computational efficiency, robustness to random measurement noise, and good statistical properties. Our method is also readily applicable to the exact matching case without loss of generality. To demonstrate the effectiveness of the proposed method, a simulation and a case study is performed on the Erdos-Renyi random graphs and the image-based affine covariant features dataset respectively.