 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Model Stitching In the Foundation Model Era
Mar 16, 2026Model stitching, connecting early layers of one model (source) to later layers of another (target) via a light stitch layer, has served as a probe of representational compatibility. Prior work finds that models trained on the same dataset remain stitchable (negligible accuracy drop) despite different initializations or objectives. We revisit stitching for Vision Foundation Models (VFMs) that vary in objectives, data, and modality mix (e.g., CLIP, DINOv2, SigLIP 2) and ask: Are heterogeneous VFMs stitchable? We introduce a systematic protocol spanning the stitch points, stitch layer families, training losses, and downstream tasks. Three findings emerge. (1) Stitch layer training matters: conventional approaches that match the intermediate features at the stitch point or optimize the task loss end-to-end struggle to retain accuracy, especially at shallow stitch points. (2) With a simple feature-matching loss at the target model's penultimate layer, heterogeneous VFMs become reliably stitchable across vision tasks. (3) For deep stitch points, the stitched model can surpass either constituent model at only a small inference overhead (for the stitch layer). Building on these findings, we further propose the VFM Stitch Tree (VST), which shares early layers across VFMs while retaining their later layers, yielding a controllable accuracy-latency trade-off for multimodal LLMs that often leverage multiple VFMs. Taken together, our study elevates stitching from a diagnostic probe to a practical recipe for integrating complementary VFM strengths and pinpointing where their representations align or diverge.
ETT-CKGE: Efficient Task-driven Tokens for Continual Knowledge Graph Embedding
Jun 09, 2025Continual Knowledge Graph Embedding (CKGE) seeks to integrate new knowledge while preserving past information. However, existing methods struggle with efficiency and scalability due to two key limitations: (1) suboptimal knowledge preservation between snapshots caused by manually designed node/relation importance scores that ignore graph dependencies relevant to the downstream task, and (2) computationally expensive graph traversal for node/relation importance calculation, leading to slow training and high memory overhead. To address these limitations, we introduce ETT-CKGE (Efficient, Task-driven, Tokens for Continual Knowledge Graph Embedding), a novel task-guided CKGE method that leverages efficient task-driven tokens for efficient and effective knowledge transfer between snapshots. Our method introduces a set of learnable tokens that directly capture task-relevant signals, eliminating the need for explicit node scoring or traversal. These tokens serve as consistent and reusable guidance across snapshots, enabling efficient token-masked embedding alignment between snapshots. Importantly, knowledge transfer is achieved through simple matrix operations, significantly reducing training time and memory usage. Extensive experiments across six benchmark datasets demonstrate that ETT-CKGE consistently achieves superior or competitive predictive performance, while substantially improving training efficiency and scalability compared to state-of-the-art CKGE methods. The code is available at: https://github.com/lijingzhu1/ETT-CKGE/tree/main
AdamL: A fast adaptive gradient method incorporating loss function
Dec 23, 2023Adaptive first-order optimizers are fundamental tools in deep learning, although they may suffer from poor generalization due to the nonuniform gradient scaling. In this work, we propose AdamL, a novel variant of the Adam optimizer, that takes into account the loss function information to attain better generalization results. We provide sufficient conditions that together with the Polyak-Lojasiewicz inequality, ensure the linear convergence of AdamL. As a byproduct of our analysis, we prove similar convergence properties for the EAdam, and AdaBelief optimizers. Experimental results on benchmark functions show that AdamL typically achieves either the fastest convergence or the lowest objective function values when compared to Adam, EAdam, and AdaBelief. These superior performances are confirmed when considering deep learning tasks such as training convolutional neural networks, training generative adversarial networks using vanilla convolutional neural networks, and long short-term memory networks. Finally, in the case of vanilla convolutional neural networks, AdamL stands out from the other Adam's variants and does not require the manual adjustment of the learning rate during the later stage of the training.
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023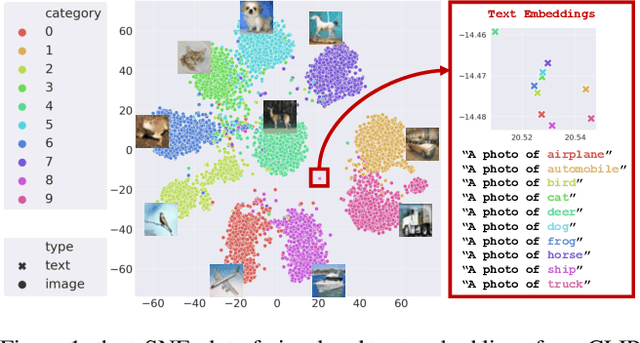
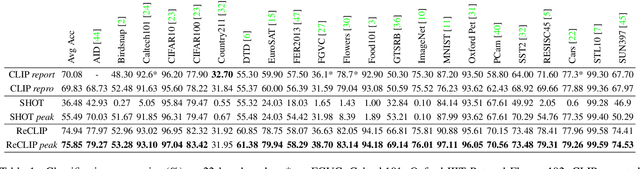
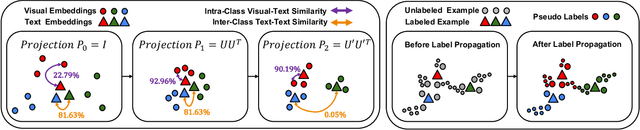
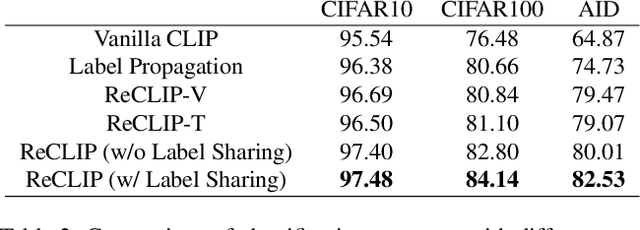
Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
On the Convergence of the Gradient Descent Method with Stochastic Fixed-point Rounding Errors under the Polyak-Lojasiewicz Inequality
Jan 23, 2023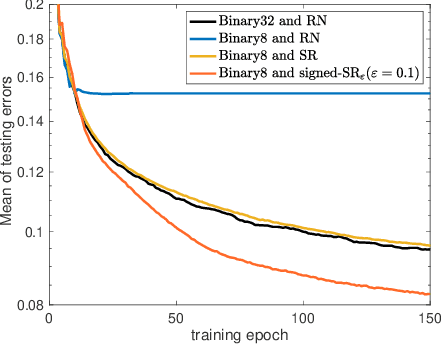

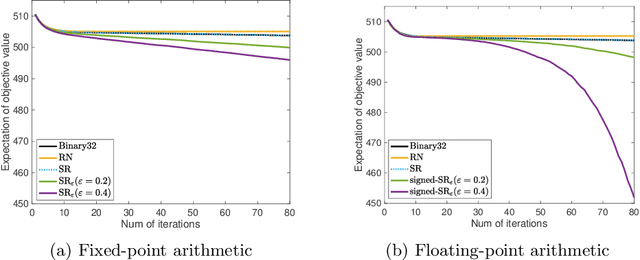
When training neural networks with low-precision computation, rounding errors often cause stagnation or are detrimental to the convergence of the optimizers; in this paper we study the influence of rounding errors on the convergence of the gradient descent method for problems satisfying the Polyak-Lojasiewicz inequality. Within this context, we show that, in contrast, biased stochastic rounding errors may be beneficial since choosing a proper rounding strategy eliminates the vanishing gradient problem and forces the rounding bias in a descent direction. Furthermore, we obtain a bound on the convergence rate that is stricter than the one achieved by unbiased stochastic rounding. The theoretical analysis is validated by comparing the performances of various rounding strategies when optimizing several examples using low-precision fixed-point number formats.
CameraPose: Weakly-Supervised Monocular 3D Human Pose Estimation by Leveraging In-the-wild 2D Annotations
Jan 08, 2023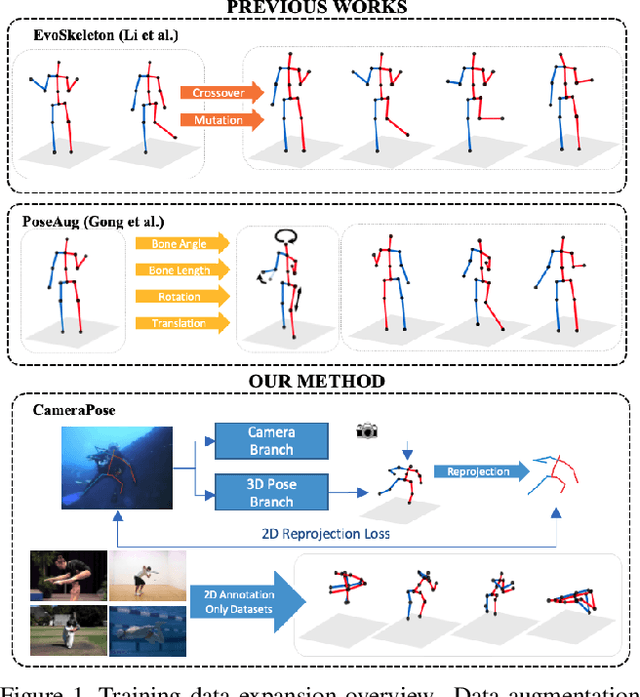
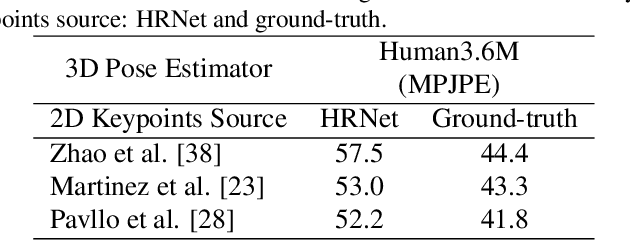
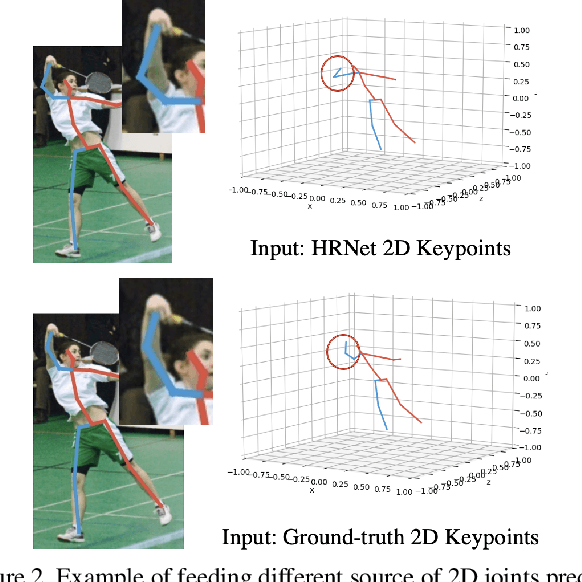

To improve the generalization of 3D human pose estimators, many existing deep learning based models focus on adding different augmentations to training poses. However, data augmentation techniques are limited to the "seen" pose combinations and hard to infer poses with rare "unseen" joint positions. To address this problem, we present CameraPose, a weakly-supervised framework for 3D human pose estimation from a single image, which can not only be applied on 2D-3D pose pairs but also on 2D alone annotations. By adding a camera parameter branch, any in-the-wild 2D annotations can be fed into our pipeline to boost the training diversity and the 3D poses can be implicitly learned by reprojecting back to 2D. Moreover, CameraPose introduces a refinement network module with confidence-guided loss to further improve the quality of noisy 2D keypoints extracted by 2D pose estimators. Experimental results demonstrate that the CameraPose brings in clear improvements on cross-scenario datasets. Notably, it outperforms the baseline method by 3mm on the most challenging dataset 3DPW. In addition, by combining our proposed refinement network module with existing 3D pose estimators, their performance can be improved in cross-scenario evaluation.
On the influence of roundoff errors on the convergence of the gradient descent method with low-precision floating-point computation
Feb 24, 2022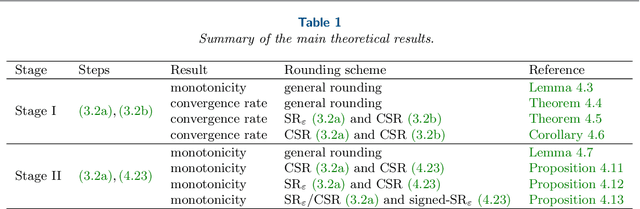
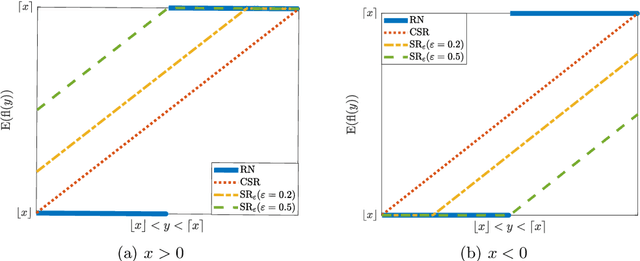

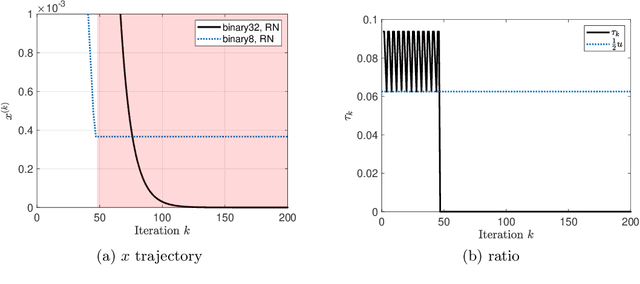
The employment of stochastic rounding schemes helps prevent stagnation of convergence, due to vanishing gradient effect when implementing the gradient descent method in low precision. Conventional stochastic rounding achieves zero bias by preserving small updates with probabilities proportional to their relative magnitudes. In this study, we propose a new stochastic rounding scheme that trades the zero bias property with a larger probability to preserve small gradients. Our method yields a constant rounding bias that, at each iteration, lies in a descent direction. For convex problems, we prove that the proposed rounding method has a beneficial effect on the convergence rate of gradient descent. We validate our theoretical analysis by comparing the performances of various rounding schemes when optimizing a multinomial logistic regression model and when training a simple neural network with 8-bit floating-point format.
A Simple and Efficient Stochastic Rounding Method for Training Neural Networks in Low Precision
Mar 24, 2021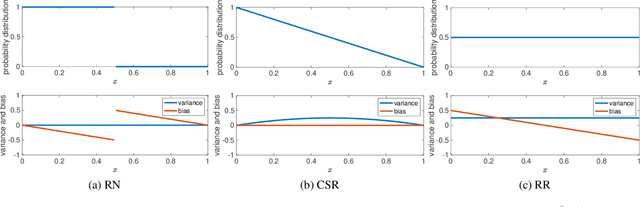
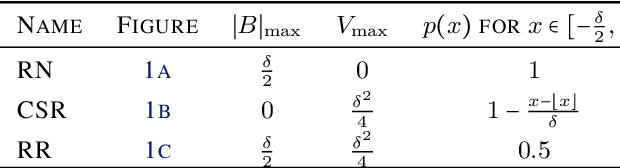
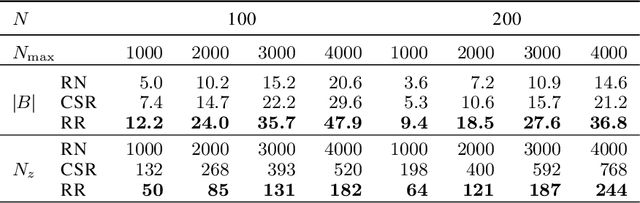
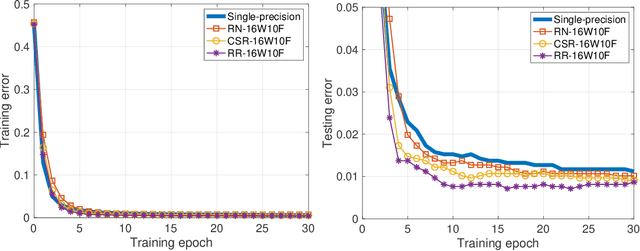
Conventional stochastic rounding (CSR) is widely employed in the training of neural networks (NNs), showing promising training results even in low-precision computations. We introduce an improved stochastic rounding method, that is simple and efficient. The proposed method succeeds in training NNs with 16-bit fixed-point numbers and provides faster convergence and higher classification accuracy than both CSR and deterministic rounding-to-the-nearest method.
Improved stochastic rounding
May 31, 2020
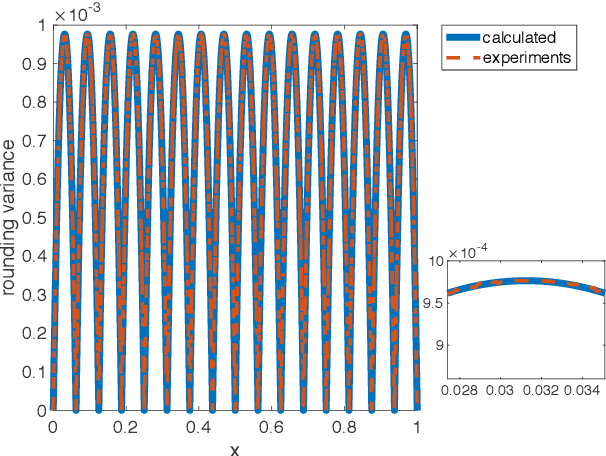
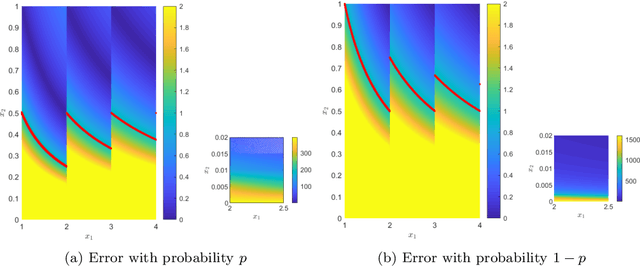
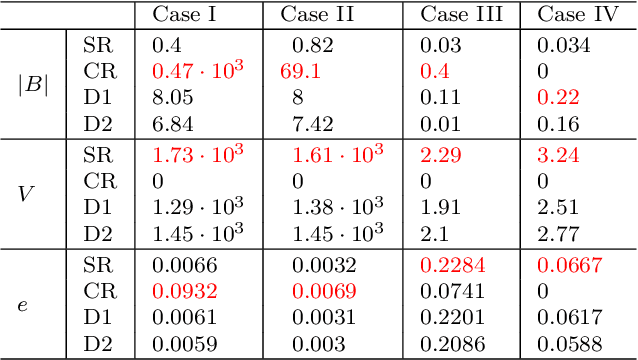
Due to the limited number of bits in floating-point or fixed-point arithmetic, rounding is a necessary step in many computations. Although rounding methods can be tailored for different applications, round-off errors are generally unavoidable. When a sequence of computations is implemented, round-off errors may be magnified or accumulated. The magnification of round-off errors may cause serious failures. Stochastic rounding (SR) was introduced as an unbiased rounding method, which is widely employed in, for instance, the training of neural networks (NNs), showing a promising training result even in low-precision computations. Although the employment of SR in training NNs is consistently increasing, the error analysis of SR is still to be improved. Additionally, the unbiased rounding results of SR are always accompanied by large variances. In this study, some general properties of SR are stated and proven. Furthermore, an upper bound of rounding variance is introduced and validated. Two new probability distributions of SR are proposed to study the trade-off between variance and bias, by solving a multiple objective optimization problem. In the simulation study, the rounding variance, bias, and relative errors of SR are studied for different operations, such as summation, square root calculation through Newton iteration and inner product computation, with specific rounding precision.
Early Recognition of Human Activities from First-Person Videos Using Onset Representations
Jul 06, 2015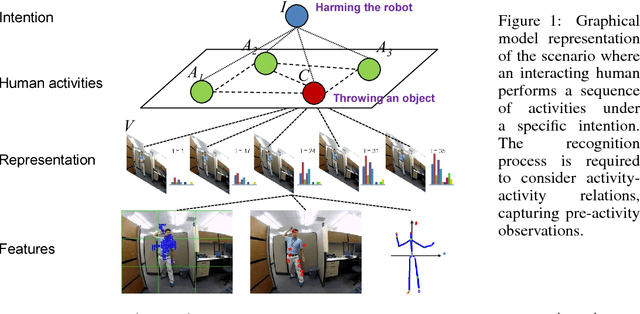
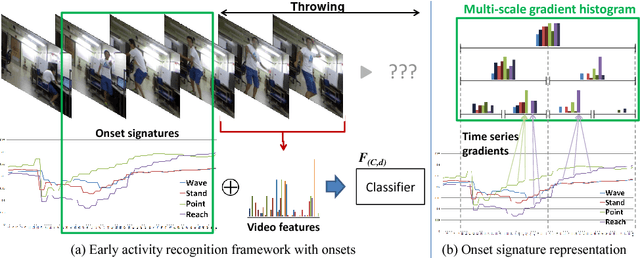

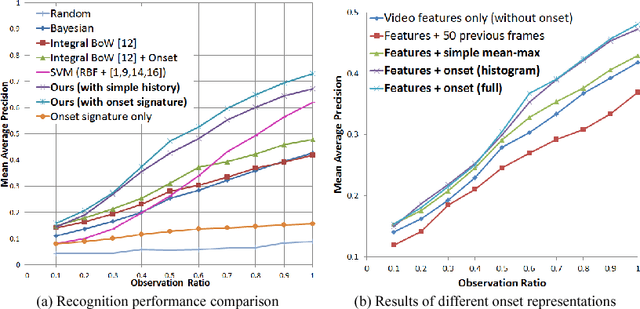
In this paper, we propose a methodology for early recognition of human activities from videos taken with a first-person viewpoint. Early recognition, which is also known as activity prediction, is an ability to infer an ongoing activity at its early stage. We present an algorithm to perform recognition of activities targeted at the camera from streaming videos, making the system to predict intended activities of the interacting person and avoid harmful events before they actually happen. We introduce the novel concept of 'onset' that efficiently summarizes pre-activity observations, and design an approach to consider event history in addition to ongoing video observation for early first-person recognition of activities. We propose to represent onset using cascade histograms of time series gradients, and we describe a novel algorithmic setup to take advantage of onset for early recognition of activities. The experimental results clearly illustrate that the proposed concept of onset enables better/earlier recognition of human activities from first-person videos.