 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Social Affordance for Human-Robot Interaction
Apr 20, 2016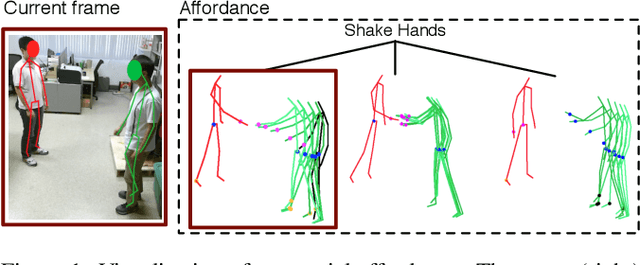
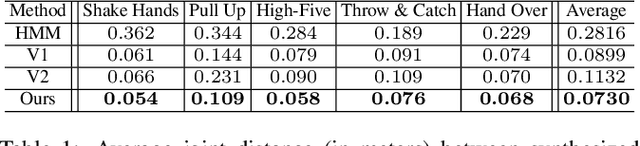
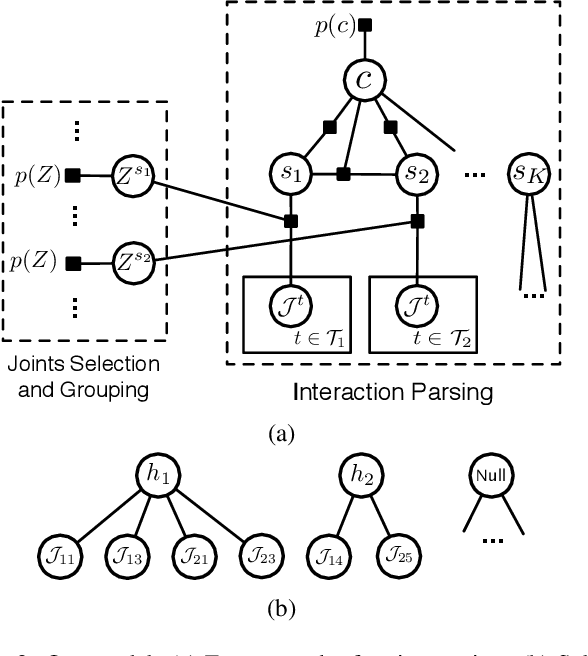
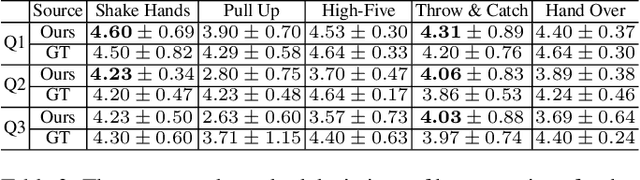
In this paper, we present an approach for robot learning of social affordance from human activity videos. We consider the problem in the context of human-robot interaction: Our approach learns structural representations of human-human (and human-object-human) interactions, describing how body-parts of each agent move with respect to each other and what spatial relations they should maintain to complete each sub-event (i.e., sub-goal). This enables the robot to infer its own movement in reaction to the human body motion, allowing it to naturally replicate such interactions. We introduce the representation of social affordance and propose a generative model for its weakly supervised learning from human demonstration videos. Our approach discovers critical steps (i.e., latent sub-events) in an interaction and the typical motion associated with them, learning what body-parts should be involved and how. The experimental results demonstrate that our Markov Chain Monte Carlo (MCMC) based learning algorithm automatically discovers semantically meaningful interactive affordance from RGB-D videos, which allows us to generate appropriate full body motion for an agent.
Early Recognition of Human Activities from First-Person Videos Using Onset Representations
Jul 06, 2015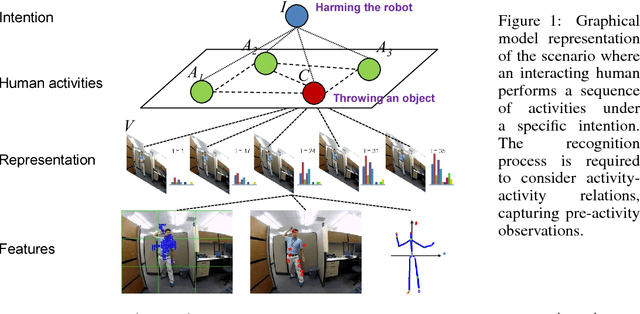
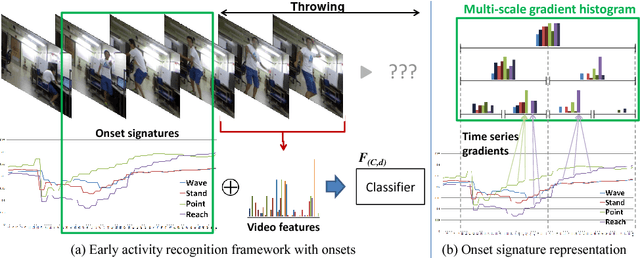

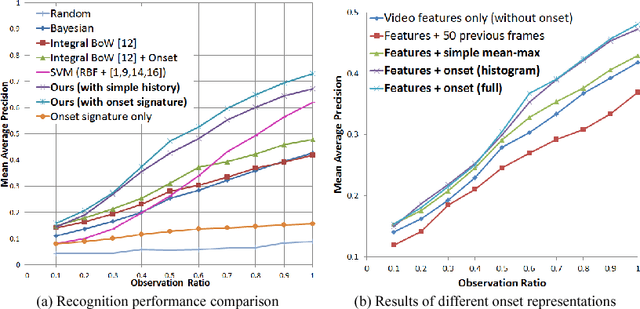
In this paper, we propose a methodology for early recognition of human activities from videos taken with a first-person viewpoint. Early recognition, which is also known as activity prediction, is an ability to infer an ongoing activity at its early stage. We present an algorithm to perform recognition of activities targeted at the camera from streaming videos, making the system to predict intended activities of the interacting person and avoid harmful events before they actually happen. We introduce the novel concept of 'onset' that efficiently summarizes pre-activity observations, and design an approach to consider event history in addition to ongoing video observation for early first-person recognition of activities. We propose to represent onset using cascade histograms of time series gradients, and we describe a novel algorithmic setup to take advantage of onset for early recognition of activities. The experimental results clearly illustrate that the proposed concept of onset enables better/earlier recognition of human activities from first-person videos.
Pooled Motion Features for First-Person Videos
May 06, 2015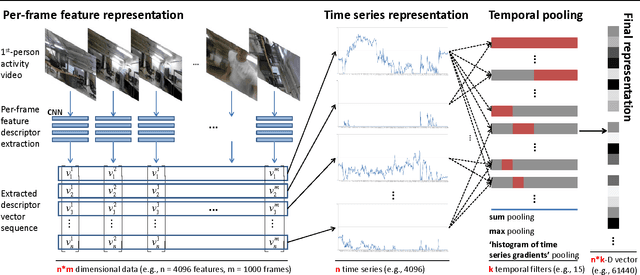
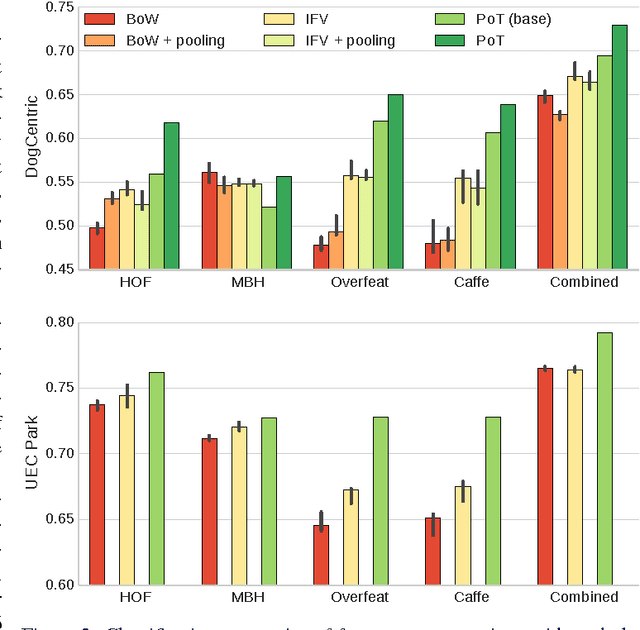
In this paper, we present a new feature representation for first-person videos. In first-person video understanding (e.g., activity recognition), it is very important to capture both entire scene dynamics (i.e., egomotion) and salient local motion observed in videos. We describe a representation framework based on time series pooling, which is designed to abstract short-term/long-term changes in feature descriptor elements. The idea is to keep track of how descriptor values are changing over time and summarize them to represent motion in the activity video. The framework is general, handling any types of per-frame feature descriptors including conventional motion descriptors like histogram of optical flows (HOF) as well as appearance descriptors from more recent convolutional neural networks (CNN). We experimentally confirm that our approach clearly outperforms previous feature representations including bag-of-visual-words and improved Fisher vector (IFV) when using identical underlying feature descriptors. We also confirm that our feature representation has superior performance to existing state-of-the-art features like local spatio-temporal features and Improved Trajectory Features (originally developed for 3rd-person videos) when handling first-person videos. Multiple first-person activity datasets were tested under various settings to confirm these findings.