 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowNav: Autonomous Global Localization for Lunar Navigation in Darkness
May 06, 2024The ability to determine the pose of a rover in an inertial frame autonomously is a crucial capability necessary for the next generation of surface rover missions on other planetary bodies. Currently, most on-going rover missions utilize ground-in-the-loop interventions to manually correct for drift in the pose estimate and this human supervision bottlenecks the distance over which rovers can operate autonomously and carry out scientific measurements. In this paper, we present ShadowNav, an autonomous approach for global localization on the Moon with an emphasis on driving in darkness and at nighttime. Our approach uses the leading edge of Lunar craters as landmarks and a particle filtering approach is used to associate detected craters with known ones on an offboard map. We discuss the key design decisions in developing the ShadowNav framework for use with a Lunar rover concept equipped with a stereo camera and an external illumination source. Finally, we demonstrate the efficacy of our proposed approach in both a Lunar simulation environment and on data collected during a field test at Cinder Lakes, Arizona.
ShadowNav: Crater-Based Localization for Nighttime and Permanently Shadowed Region Lunar Navigation
Jan 11, 2023



There has been an increase in interest in missions that drive significantly longer distances per day than what has currently been performed. Further, some of these proposed missions require autonomous driving and absolute localization in darkness. For example, the Endurance A mission proposes to drive 1200km of its total traverse at night. The lack of natural light available during such missions limits what can be used as visual landmarks and the range at which landmarks can be observed. In order for planetary rovers to traverse long ranges, onboard absolute localization is critical to the ability of the rover to maintain its planned trajectory and avoid known hazardous regions. Currently, to accomplish absolute localization, a ground in the loop (GITL) operation is performed wherein a human operator matches local maps or images from onboard with orbital images and maps. This GITL operation limits the distance that can be driven in a day to a few hundred meters, which is the distance that the rover can maintain acceptable localization error via relative methods. Previous work has shown that using craters as landmarks is a promising approach for performing absolute localization on the moon during the day. In this work we present a method of absolute localization that utilizes craters as landmarks and matches detected crater edges on the surface with known craters in orbital maps. We focus on a localization method based on a perception system which has an external illuminator and a stereo camera. We evaluate (1) both monocular and stereo based surface crater edge detection techniques, (2) methods of scoring the crater edge matches for optimal localization, and (3) localization performance on simulated Lunar surface imagery at night. We demonstrate that this technique shows promise for maintaining absolute localization error of less than 10m required for most planetary rover missions.
LunarNav: Crater-based Localization for Long-range Autonomous Lunar Rover Navigation
Jan 03, 2023



The Artemis program requires robotic and crewed lunar rovers for resource prospecting and exploitation, construction and maintenance of facilities, and human exploration. These rovers must support navigation for 10s of kilometers (km) from base camps. A lunar science rover mission concept - Endurance-A, has been recommended by the new Decadal Survey as the highest priority medium-class mission of the Lunar Discovery and Exploration Program, and would be required to traverse approximately 2000 km in the South Pole-Aitkin (SPA) Basin, with individual drives of several kilometers between stops for downlink. These rover mission scenarios require functionality that provides onboard, autonomous, global position knowledge ( aka absolute localization). However, planetary rovers have no onboard global localization capability to date; they have only used relative localization, by integrating combinations of wheel odometry, visual odometry, and inertial measurements during each drive to track position relative to the start of each drive. In this work, we summarize recent developments from the LunarNav project, where we have developed algorithms and software to enable lunar rovers to estimate their global position and heading on the Moon with a goal performance of position error less than 5 meters (m) and heading error less than 3-degree, 3-sigma, in sunlit areas. This will be achieved autonomously onboard by detecting craters in the vicinity of the rover and matching them to a database of known craters mapped from orbit. The overall technical framework consists of three main elements: 1) crater detection, 2) crater matching, and 3) state estimation. In previous work, we developed crater detection algorithms for three different sensing modalities. Our results suggest that rover localization with an error less than 5 m is highly probable during daytime operations.
Lunar Rover Localization Using Craters as Landmarks
Mar 18, 2022

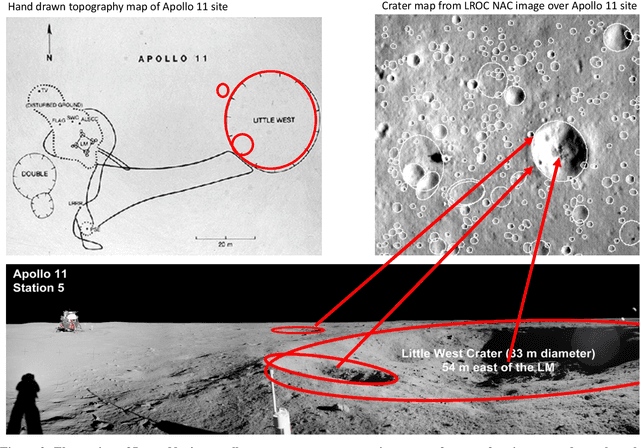
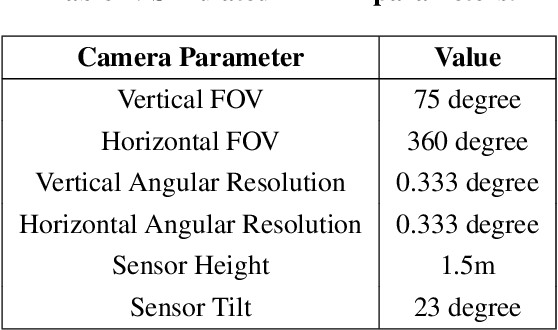
Onboard localization capabilities for planetary rovers to date have used relative navigation, by integrating combinations of wheel odometry, visual odometry, and inertial measurements during each drive to track position relative to the start of each drive. At the end of each drive, a ground-in-the-loop (GITL) interaction is used to get a position update from human operators in a more global reference frame, by matching images or local maps from onboard the rover to orbital reconnaissance images or maps of a large region around the rover's current position. Autonomous rover drives are limited in distance so that accumulated relative navigation error does not risk the possibility of the rover driving into hazards known from orbital images. However, several rover mission concepts have recently been studied that require much longer drives between GITL cycles, particularly for the Moon. These concepts require greater autonomy to minimize GITL cycles to enable such large range; onboard global localization is a key element of such autonomy. Multiple techniques have been studied in the past for onboard rover global localization, but a satisfactory solution has not yet emerged. For the Moon, the ubiquitous craters offer a new possibility, which involves mapping craters from orbit, then recognizing crater landmarks with cameras and-or a lidar onboard the rover. This approach is applicable everywhere on the Moon, does not require high resolution stereo imaging from orbit as some other approaches do, and has potential to enable position knowledge with order of 5 to 10 m accuracy at all times. This paper describes our technical approach to crater-based lunar rover localization and presents initial results on crater detection using 3D point cloud data from onboard lidar or stereo cameras, as well as using shading cues in monocular onboard imagery.
Mid-Air Helicopter Delivery at Mars Using a Jetpack
Mar 07, 2022
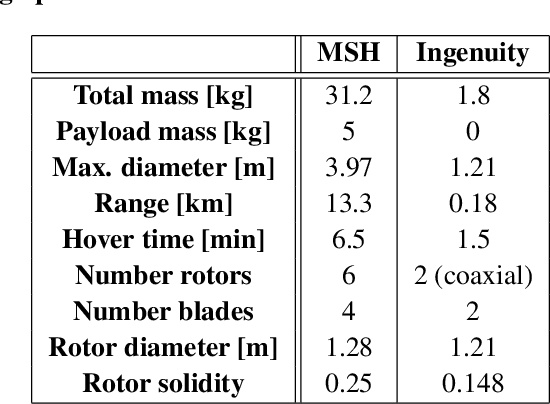
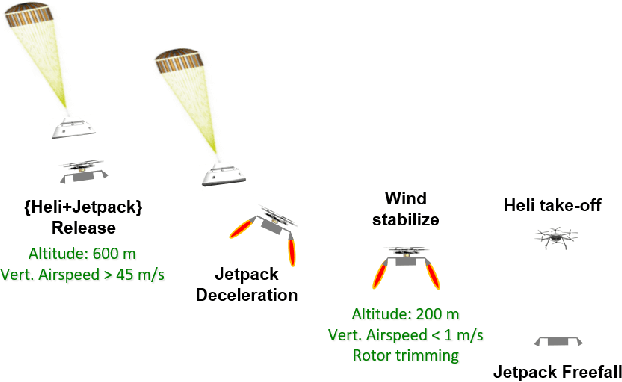
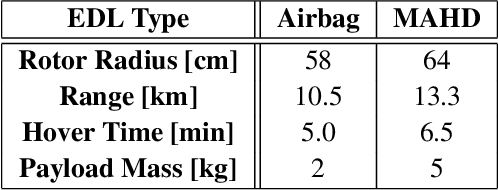
Mid-Air Helicopter Delivery (MAHD) is a new Entry, Descent and Landing (EDL) architecture to enable in situ mobility for Mars science at lower cost than previous missions. It uses a jetpack to slow down a Mars Science Helicopter (MSH) after separation from the backshell, and reach aerodynamic conditions suitable for helicopter take-off in mid air. For given aeroshell dimensions, only MAHD's lander-free approach leaves enough room in the aeroshell to accommodate the largest rotor option for MSH. This drastically improves flight performance, notably allowing +150\% increased science payload mass. Compared to heritage EDL approaches, the simpler MAHD architecture is also likely to reduce cost, and enables access to more hazardous and higher-elevation terrains on Mars. This paper introduces a design for the MAHD system architecture and operations. We present a mechanical configuration that fits both MSH and the jetpack within the 2.65-m Mars heritage aeroshell, and a jetpack control architecture which fully leverages the available helicopter avionics. We discuss preliminary numerical models of the flow dynamics resulting from the interaction between the jets, the rotors and the side winds. We define a force-torque sensing architecture capable of handling the wind and trimming the rotors to prepare for safe take-off. Finally, we analyze the dynamic environment and closed-loop control simulation results to demonstrate the preliminary feasibility of MAHD.
Multi-Resolution Elevation Mapping and Safe Landing Site Detection with Applications to Planetary Rotorcraft
Nov 11, 2021
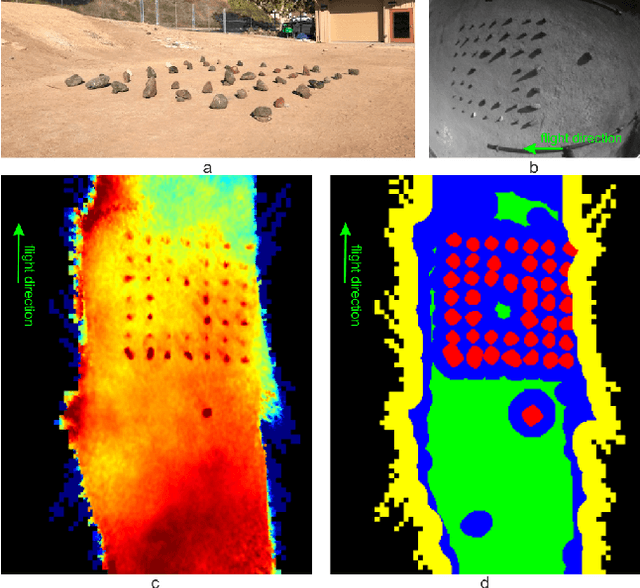
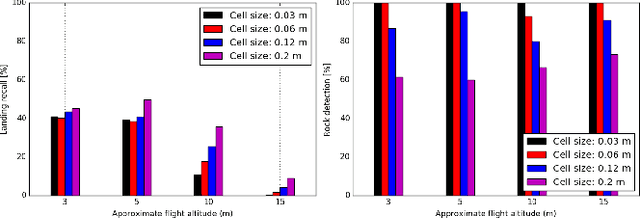

In this paper, we propose a resource-efficient approach to provide an autonomous UAV with an on-board perception method to detect safe, hazard-free landing sites during flights over complex 3D terrain. We aggregate 3D measurements acquired from a sequence of monocular images by a Structure-from-Motion approach into a local, robot-centric, multi-resolution elevation map of the overflown terrain, which fuses depth measurements according to their lateral surface resolution (pixel-footprint) in a probabilistic framework based on the concept of dynamic Level of Detail. Map aggregation only requires depth maps and the associated poses, which are obtained from an onboard Visual Odometry algorithm. An efficient landing site detection method then exploits the features of the underlying multi-resolution map to detect safe landing sites based on slope, roughness, and quality of the reconstructed terrain surface. The evaluation of the performance of the mapping and landing site detection modules are analyzed independently and jointly in simulated and real-world experiments in order to establish the efficacy of the proposed approach.
Online Photometric Calibration of Automatic Gain Thermal Infrared Cameras
Jan 11, 2021
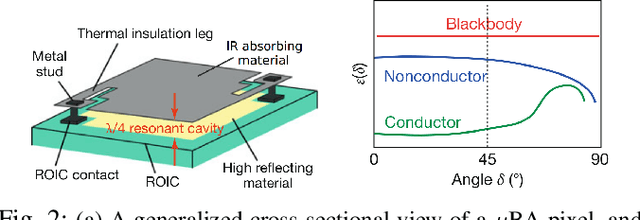

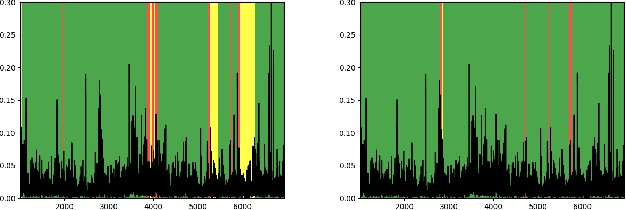
Thermal infrared cameras are increasingly being used in various applications such as robot vision, industrial inspection and medical imaging, thanks to their improved resolution and portability. However, the performance of traditional computer vision techniques developed for electro-optical imagery does not directly translate to the thermal domain due to two major reasons: these algorithms require photometric assumptions to hold, and methods for photometric calibration of RGB cameras cannot be applied to thermal-infrared cameras due to difference in data acquisition and sensor phenomenology. In this paper, we take a step in this direction, and introduce a novel algorithm for online photometric calibration of thermal-infrared cameras. Our proposed method does not require any specific driver/hardware support and hence can be applied to any commercial off-the-shelf thermal IR camera. We present this in the context of visual odometry and SLAM algorithms, and demonstrate the efficacy of our proposed system through extensive experiments for both standard benchmark datasets, and real-world field tests with a thermal-infrared camera in natural outdoor environments.
Online Self-supervised Scene Segmentation for Micro Aerial Vehicles
Jun 13, 2018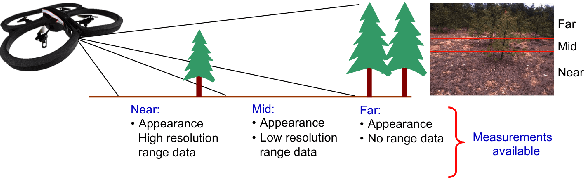
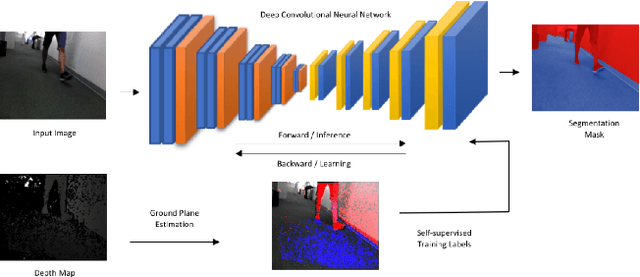


Recently, there have been numerous advances in the development of payload and power constrained lightweight Micro Aerial Vehicles (MAVs). As these robots aspire for high-speed autonomous flights in complex dynamic environments, robust scene understanding at long-range becomes critical. The problem is heavily characterized by either the limitations imposed by sensor capabilities for geometry-based methods, or the need for large-amounts of manually annotated training data required by data-driven methods. This motivates the need to build systems that have the capability to alleviate these problems by exploiting the complimentary strengths of both geometry and data-driven methods. In this paper, we take a step in this direction and propose a generic framework for adaptive scene segmentation using self-supervised online learning. We present this in the context of vision-based autonomous MAV flight, and demonstrate the efficacy of our proposed system through extensive experiments on benchmark datasets and real-world field tests.
Multi-Type Activity Recognition in Robot-Centric Scenarios
Apr 12, 2016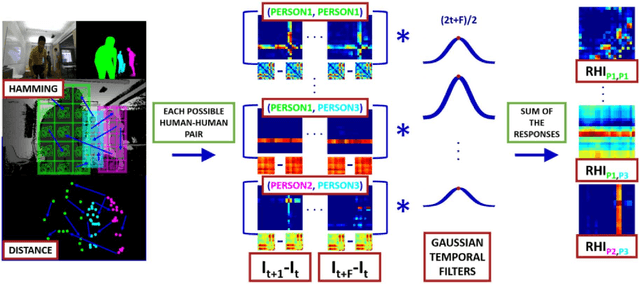
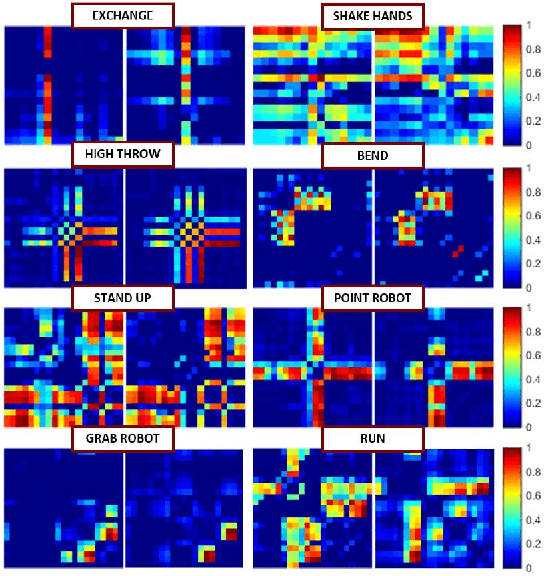


Activity recognition is very useful in scenarios where robots interact with, monitor or assist humans. In the past years many types of activities -- single actions, two persons interactions or ego-centric activities, to name a few -- have been analyzed. Whereas traditional methods treat such types of activities separately, an autonomous robot should be able to detect and recognize multiple types of activities to effectively fulfill its tasks. We propose a method that is intrinsically able to detect and recognize activities of different types that happen in sequence or concurrently. We present a new unified descriptor, called Relation History Image (RHI), which can be extracted from all the activity types we are interested in. We then formulate an optimization procedure to detect and recognize activities of different types. We apply our approach to a new dataset recorded from a robot-centric perspective and systematically evaluate its quality compared to multiple baselines. Finally, we show the efficacy of the RHI descriptor on publicly available datasets performing extensive comparisons.
Early Recognition of Human Activities from First-Person Videos Using Onset Representations
Jul 06, 2015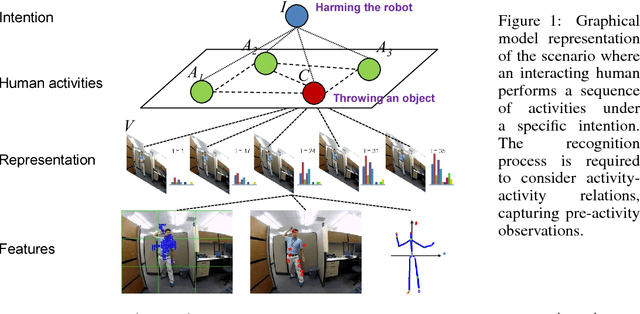
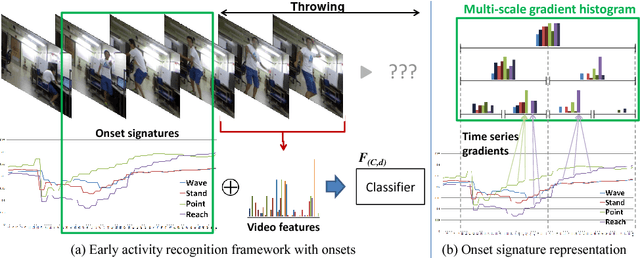

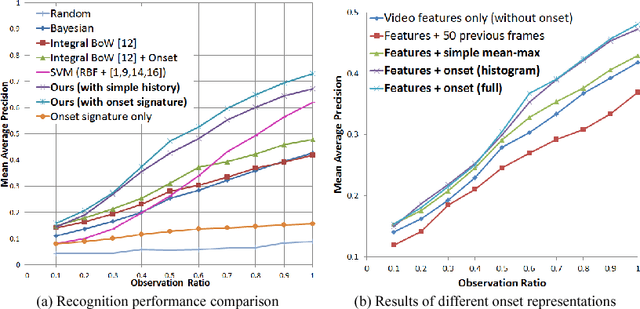
In this paper, we propose a methodology for early recognition of human activities from videos taken with a first-person viewpoint. Early recognition, which is also known as activity prediction, is an ability to infer an ongoing activity at its early stage. We present an algorithm to perform recognition of activities targeted at the camera from streaming videos, making the system to predict intended activities of the interacting person and avoid harmful events before they actually happen. We introduce the novel concept of 'onset' that efficiently summarizes pre-activity observations, and design an approach to consider event history in addition to ongoing video observation for early first-person recognition of activities. We propose to represent onset using cascade histograms of time series gradients, and we describe a novel algorithmic setup to take advantage of onset for early recognition of activities. The experimental results clearly illustrate that the proposed concept of onset enables better/earlier recognition of human activities from first-person videos.