 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLunarNav: Crater-based Localization for Long-range Autonomous Lunar Rover Navigation
Jan 03, 2023



The Artemis program requires robotic and crewed lunar rovers for resource prospecting and exploitation, construction and maintenance of facilities, and human exploration. These rovers must support navigation for 10s of kilometers (km) from base camps. A lunar science rover mission concept - Endurance-A, has been recommended by the new Decadal Survey as the highest priority medium-class mission of the Lunar Discovery and Exploration Program, and would be required to traverse approximately 2000 km in the South Pole-Aitkin (SPA) Basin, with individual drives of several kilometers between stops for downlink. These rover mission scenarios require functionality that provides onboard, autonomous, global position knowledge ( aka absolute localization). However, planetary rovers have no onboard global localization capability to date; they have only used relative localization, by integrating combinations of wheel odometry, visual odometry, and inertial measurements during each drive to track position relative to the start of each drive. In this work, we summarize recent developments from the LunarNav project, where we have developed algorithms and software to enable lunar rovers to estimate their global position and heading on the Moon with a goal performance of position error less than 5 meters (m) and heading error less than 3-degree, 3-sigma, in sunlit areas. This will be achieved autonomously onboard by detecting craters in the vicinity of the rover and matching them to a database of known craters mapped from orbit. The overall technical framework consists of three main elements: 1) crater detection, 2) crater matching, and 3) state estimation. In previous work, we developed crater detection algorithms for three different sensing modalities. Our results suggest that rover localization with an error less than 5 m is highly probable during daytime operations.
Deep Learning with Experience Ranking Convolutional Neural Network for Robot Manipulator
Sep 16, 2018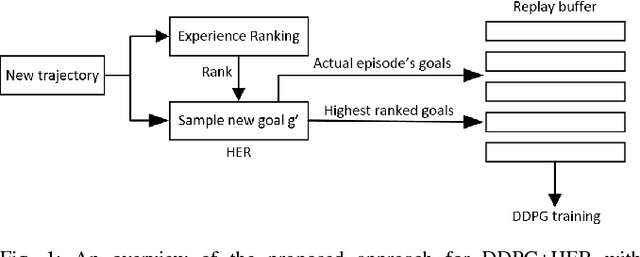
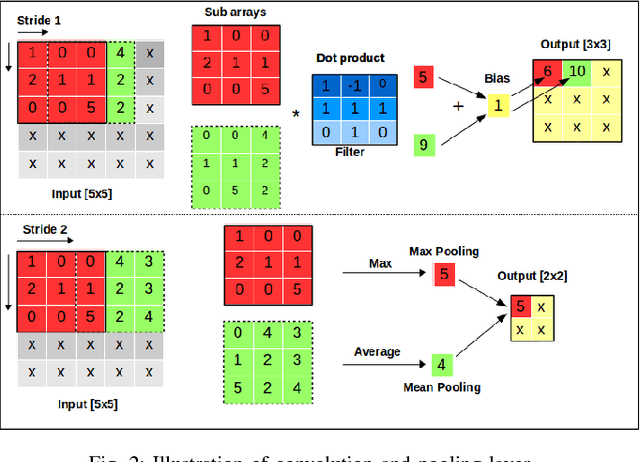
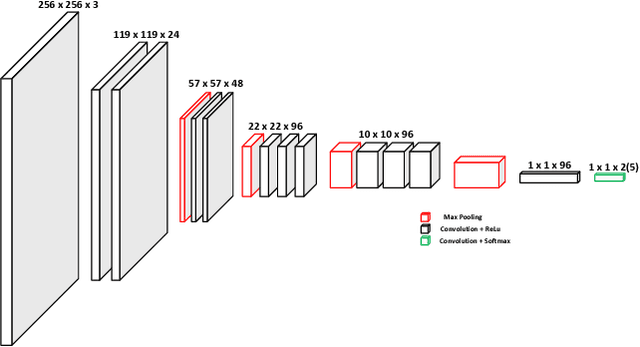

Supervised learning, more specifically Convolutional Neural Networks (CNN), has surpassed human ability in some visual recognition tasks such as detection of traffic signs, faces and handwritten numbers. On the other hand, even state-of-the-art reinforcement learning (RL) methods have difficulties in environments with sparse and binary rewards. They requires manually shaping reward functions, which might be challenging to come up with. These tasks, however, are trivial to human. One of the reasons that human are better learners in these tasks is that we are embedded with much prior knowledge of the world. These knowledge might be either embedded in our genes or learned from imitation - a type of supervised learning. For that reason, the best way to narrow the gap between machine and human learning ability should be to mimic how we learn so well in various tasks by a combination of RL and supervised learning. Our method, which integrates Deep Deterministic Policy Gradients and Hindsight Experience Replay (RL method specifically dealing with sparse rewards) with an experience ranking CNN, provides a significant speedup over the learning curve on simulated robotics tasks. Experience ranking allows high-reward transitions to be replayed more frequently, and therefore help learn more efficiently. Our proposed approach can also speed up learning in any other tasks that provide additional information for experience ranking.
A Distributed Control Framework for a Team of Unmanned Aerial Vehicles for Dynamic Wildfire Tracking
Apr 09, 2017

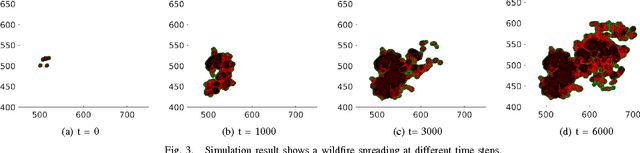
Wildland fire fighting is a very dangerous job, and the lack of information of the fire front is one of main reasons that causes many accidents. Using unmanned aerial vehicle (UAV) to cover wildfire is promising because it can replace human in hazardous fire tracking and save operation costs significantly. In this paper we propose a distributed control framework designed for a team of UAVs that can closely monitor a wildfire in open space, and precisely track its development. The UAV team, designed for flexible deployment, can effectively avoid in-flight collision as well as cooperate well with other neighbors. Experimental results are conducted to demonstrate the capabilites of the UAV team in covering a spreading wildfire.