 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLunarNav: Crater-based Localization for Long-range Autonomous Lunar Rover Navigation
Jan 03, 2023



The Artemis program requires robotic and crewed lunar rovers for resource prospecting and exploitation, construction and maintenance of facilities, and human exploration. These rovers must support navigation for 10s of kilometers (km) from base camps. A lunar science rover mission concept - Endurance-A, has been recommended by the new Decadal Survey as the highest priority medium-class mission of the Lunar Discovery and Exploration Program, and would be required to traverse approximately 2000 km in the South Pole-Aitkin (SPA) Basin, with individual drives of several kilometers between stops for downlink. These rover mission scenarios require functionality that provides onboard, autonomous, global position knowledge ( aka absolute localization). However, planetary rovers have no onboard global localization capability to date; they have only used relative localization, by integrating combinations of wheel odometry, visual odometry, and inertial measurements during each drive to track position relative to the start of each drive. In this work, we summarize recent developments from the LunarNav project, where we have developed algorithms and software to enable lunar rovers to estimate their global position and heading on the Moon with a goal performance of position error less than 5 meters (m) and heading error less than 3-degree, 3-sigma, in sunlit areas. This will be achieved autonomously onboard by detecting craters in the vicinity of the rover and matching them to a database of known craters mapped from orbit. The overall technical framework consists of three main elements: 1) crater detection, 2) crater matching, and 3) state estimation. In previous work, we developed crater detection algorithms for three different sensing modalities. Our results suggest that rover localization with an error less than 5 m is highly probable during daytime operations.
Forest Fire Clustering: Cluster-oriented Label Propagation Clustering and Monte Carlo Verification Inspired by Forest Fire Dynamics
Mar 30, 2021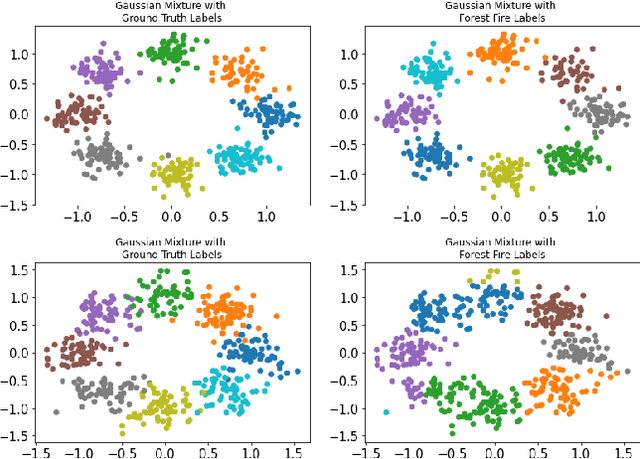
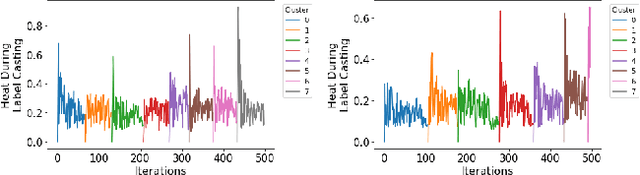
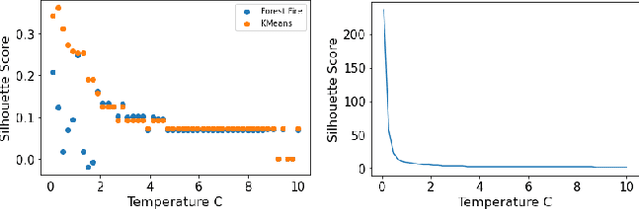
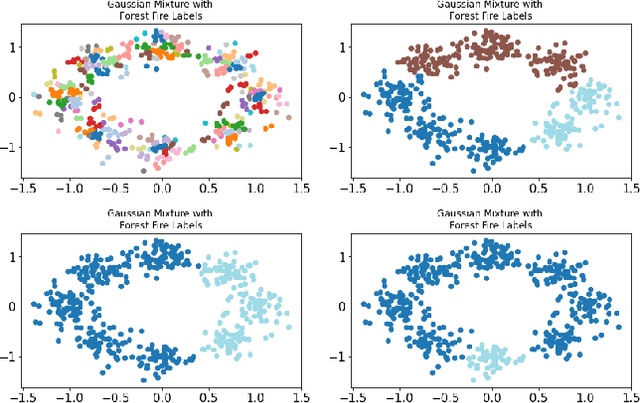
Clustering methods group data points together and assign them group-level labels. However, it has been difficult to evaluate the confidence of the clustering results. Here, we introduce a novel method that could not only find robust clusters but also provide a confidence score for the labels of each data point. Specifically, we reformulated label-propagation clustering to model after forest fire dynamics. The method has only one parameter - a fire temperature term describing how easily one label propagates from one node to the next. Through iteratively starting label propagations through a graph, we can discover the number of clusters in a dataset with minimum prior assumptions. Further, we can validate our predictions and uncover the posterior probability distribution of the labels using Monte Carlo simulations. Lastly, our iterative method is inductive and does not need to be retrained with the arrival of new data. Here, we describe the method and provide a summary of how the method performs against common clustering benchmarks.