 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Image Counterfactuals and Feature Attributions with Latent-Space Adversarial Attacks
Apr 21, 2025

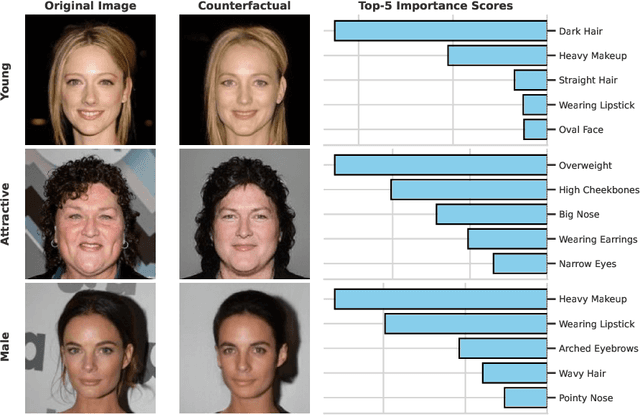
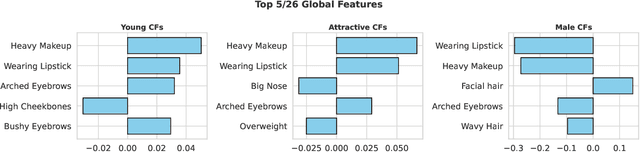
Counterfactuals are a popular framework for interpreting machine learning predictions. These what if explanations are notoriously challenging to create for computer vision models: standard gradient-based methods are prone to produce adversarial examples, in which imperceptible modifications to image pixels provoke large changes in predictions. We introduce a new, easy-to-implement framework for counterfactual images that can flexibly adapt to contemporary advances in generative modeling. Our method, Counterfactual Attacks, resembles an adversarial attack on the representation of the image along a low-dimensional manifold. In addition, given an auxiliary dataset of image descriptors, we show how to accompany counterfactuals with feature attribution that quantify the changes between the original and counterfactual images. These importance scores can be aggregated into global counterfactual explanations that highlight the overall features driving model predictions. While this unification is possible for any counterfactual method, it has particular computational efficiency for ours. We demonstrate the efficacy of our approach with the MNIST and CelebA datasets.
Provably Stable Feature Rankings with SHAP and LIME
Jan 28, 2024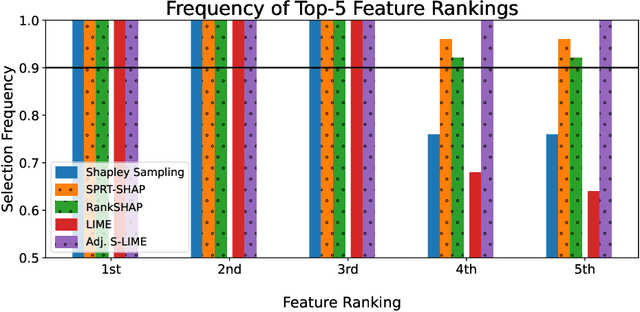
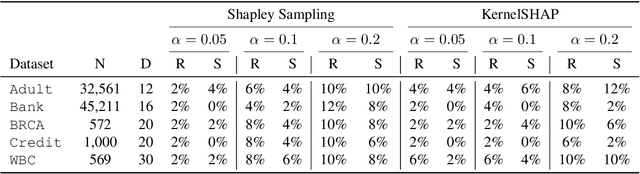
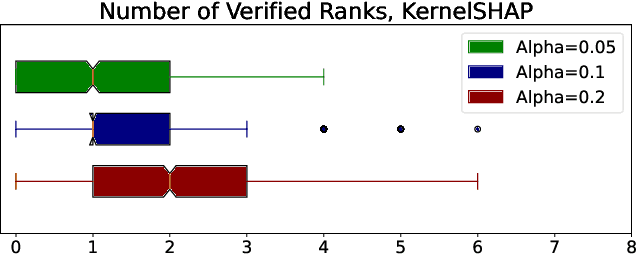
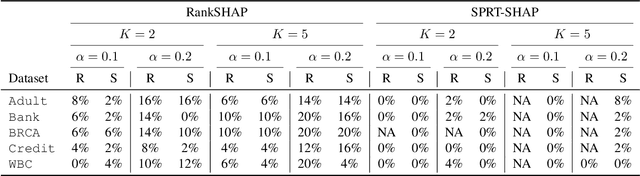
Feature attributions are ubiquitous tools for understanding the predictions of machine learning models. However, popular methods for scoring input variables such as SHAP and LIME suffer from high instability due to random sampling. Leveraging ideas from multiple hypothesis testing, we devise attribution methods that correctly rank the most important features with high probability. Our algorithm RankSHAP guarantees that the $K$ highest Shapley values have the proper ordering with probability exceeding $1-\alpha$. Empirical results demonstrate its validity and impressive computational efficiency. We also build on previous work to yield similar results for LIME, ensuring the most important features are selected in the right order.
MedGen: A Python Natural Language Processing Toolkit for Medical Text Processing
Nov 28, 2023
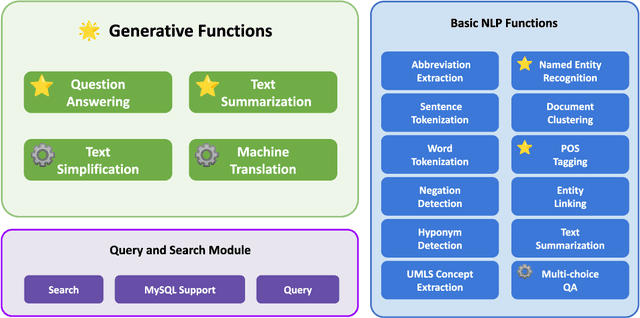
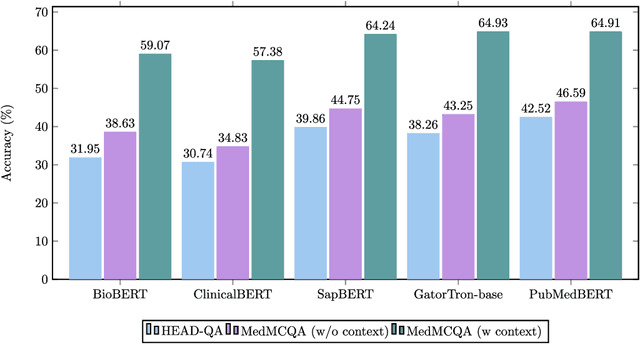
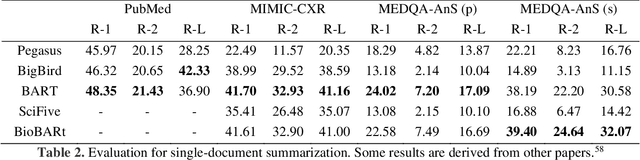
This study introduces MedGen, a comprehensive natural language processing (NLP) toolkit designed for medical text processing. MedGen is tailored for biomedical researchers and healthcare professionals with an easy-to-use, all-in-one solution that requires minimal programming expertise. It includes (1) Generative Functions: For the first time, MedGen includes four advanced generative functions: question answering, text summarization, text simplification, and machine translation; (2) Basic NLP Functions: MedGen integrates 12 essential NLP functions such as word tokenization and sentence segmentation; and (3) Query and Search Capabilities: MedGen provides user-friendly query and search functions on text corpora. We fine-tuned 32 domain-specific language models, evaluated them thoroughly on 24 established benchmarks and conducted manual reviews with clinicians. Additionally, we expanded our toolkit by introducing query and search functions, while also standardizing and integrating functions from third-party libraries. The toolkit, its models, and associated data are publicly available via https://github.com/Yale-LILY/MedGen.
Stabilizing Estimates of Shapley Values with Control Variates
Oct 11, 2023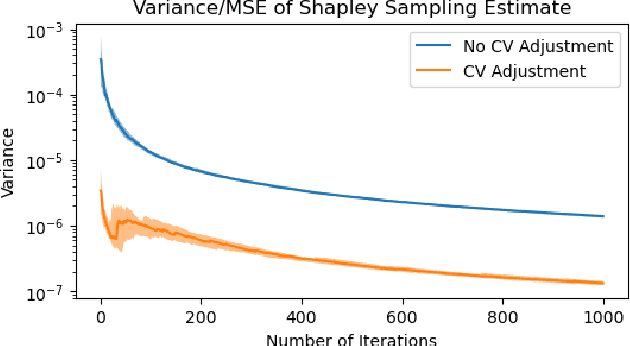
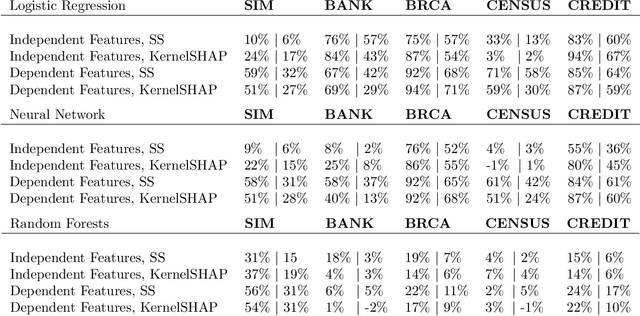
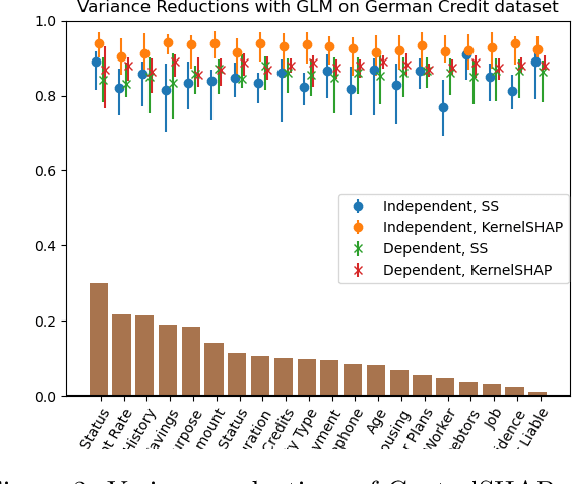
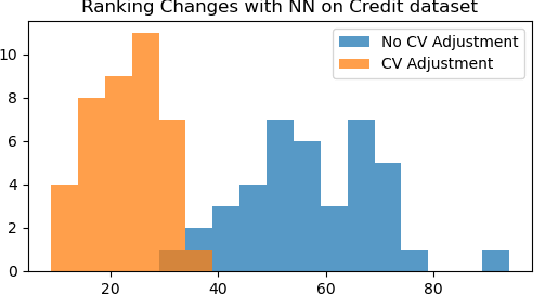
Shapley values are among the most popular tools for explaining predictions of blackbox machine learning models. However, their high computational cost motivates the use of sampling approximations, inducing a considerable degree of uncertainty. To stabilize these model explanations, we propose ControlSHAP, an approach based on the Monte Carlo technique of control variates. Our methodology is applicable to any machine learning model and requires virtually no extra computation or modeling effort. On several high-dimensional datasets, we find it can produce dramatic reductions in the Monte Carlo variability of Shapley estimates.
Neural Natural Language Processing for Unstructured Data in Electronic Health Records: a Review
Jul 07, 2021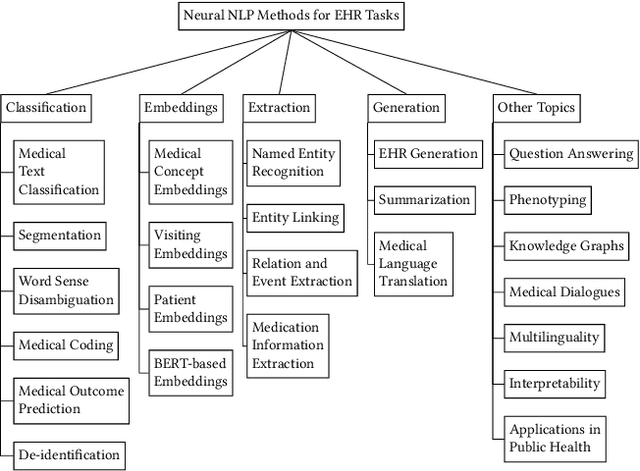
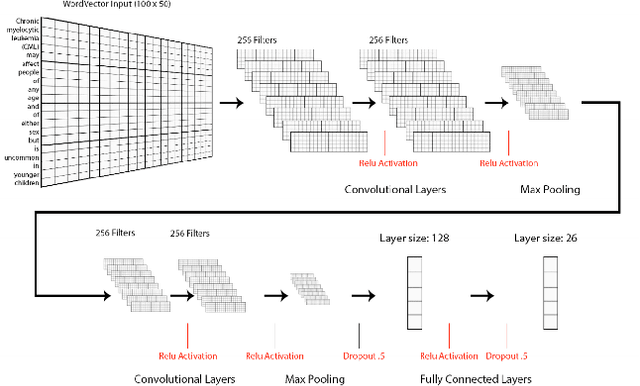
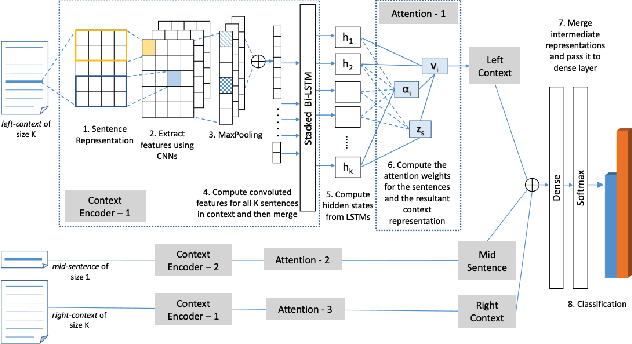

Electronic health records (EHRs), digital collections of patient healthcare events and observations, are ubiquitous in medicine and critical to healthcare delivery, operations, and research. Despite this central role, EHRs are notoriously difficult to process automatically. Well over half of the information stored within EHRs is in the form of unstructured text (e.g. provider notes, operation reports) and remains largely untapped for secondary use. Recently, however, newer neural network and deep learning approaches to Natural Language Processing (NLP) have made considerable advances, outperforming traditional statistical and rule-based systems on a variety of tasks. In this survey paper, we summarize current neural NLP methods for EHR applications. We focus on a broad scope of tasks, namely, classification and prediction, word embeddings, extraction, generation, and other topics such as question answering, phenotyping, knowledge graphs, medical dialogue, multilinguality, interpretability, etc.
Forest Fire Clustering: Cluster-oriented Label Propagation Clustering and Monte Carlo Verification Inspired by Forest Fire Dynamics
Mar 30, 2021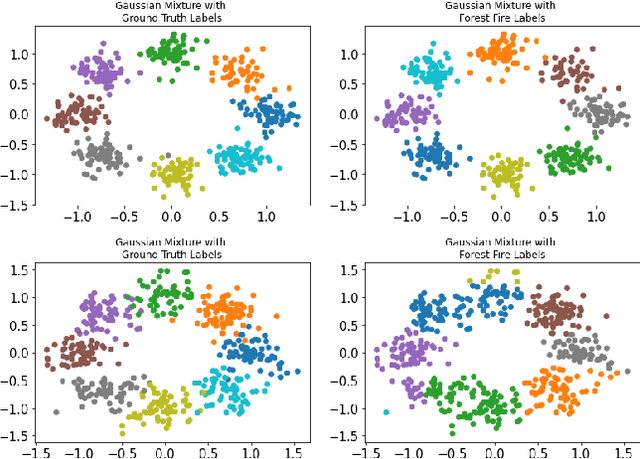
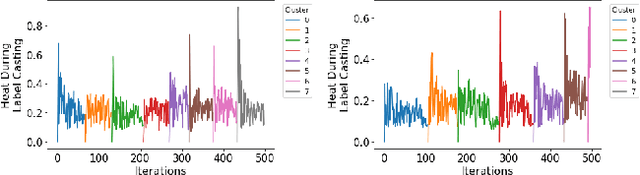
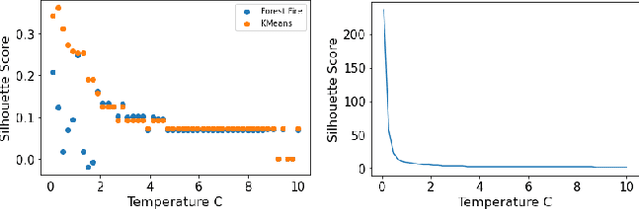
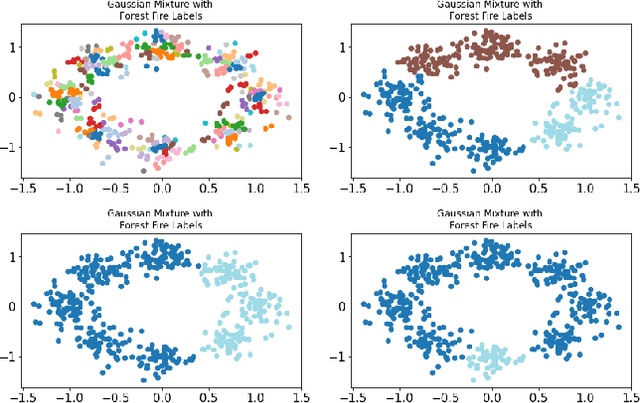
Clustering methods group data points together and assign them group-level labels. However, it has been difficult to evaluate the confidence of the clustering results. Here, we introduce a novel method that could not only find robust clusters but also provide a confidence score for the labels of each data point. Specifically, we reformulated label-propagation clustering to model after forest fire dynamics. The method has only one parameter - a fire temperature term describing how easily one label propagates from one node to the next. Through iteratively starting label propagations through a graph, we can discover the number of clusters in a dataset with minimum prior assumptions. Further, we can validate our predictions and uncover the posterior probability distribution of the labels using Monte Carlo simulations. Lastly, our iterative method is inductive and does not need to be retrained with the arrival of new data. Here, we describe the method and provide a summary of how the method performs against common clustering benchmarks.