 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemodeLing: A Novel Dataset for Testing Linguistic Reasoning in Language Models
Jun 24, 2024We introduce modeLing, a novel benchmark of Linguistics Olympiad-style puzzles which tests few-shot reasoning in AI systems. Solving these puzzles necessitates inferring aspects of a language's grammatical structure from a small number of examples. Such puzzles provide a natural testbed for language models, as they require compositional generalization and few-shot inductive reasoning. Consisting solely of new puzzles written specifically for this work, modeLing has no risk of appearing in the training data of existing AI systems: this ameliorates the risk of data leakage, a potential confounder for many prior evaluations of reasoning. Evaluating several large open source language models and GPT on our benchmark, we observe non-negligible accuracy, demonstrating few-shot emergent reasoning ability which cannot merely be attributed to shallow memorization. However, imperfect model performance suggests that modeLing can be used to measure further progress in linguistic reasoning.
MedGen: A Python Natural Language Processing Toolkit for Medical Text Processing
Nov 28, 2023
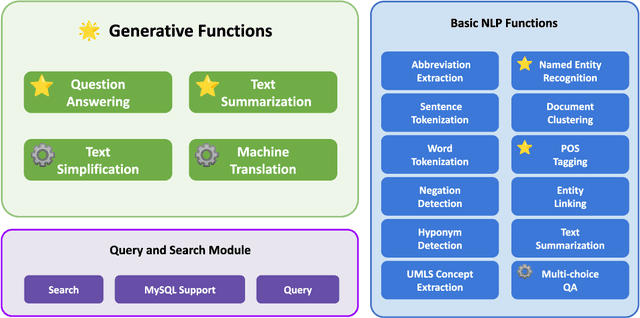
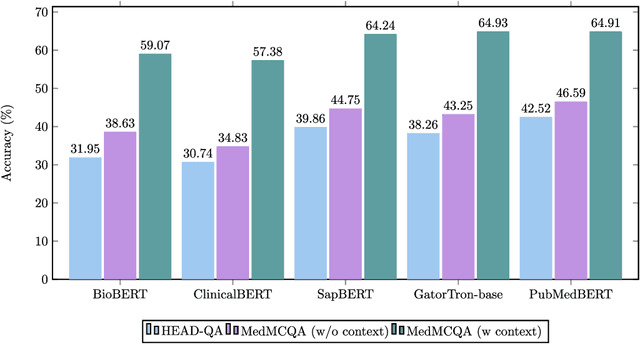
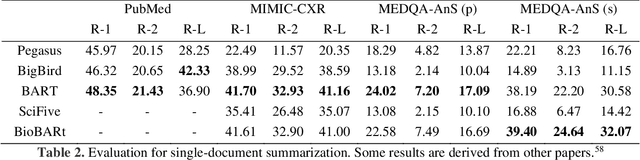
This study introduces MedGen, a comprehensive natural language processing (NLP) toolkit designed for medical text processing. MedGen is tailored for biomedical researchers and healthcare professionals with an easy-to-use, all-in-one solution that requires minimal programming expertise. It includes (1) Generative Functions: For the first time, MedGen includes four advanced generative functions: question answering, text summarization, text simplification, and machine translation; (2) Basic NLP Functions: MedGen integrates 12 essential NLP functions such as word tokenization and sentence segmentation; and (3) Query and Search Capabilities: MedGen provides user-friendly query and search functions on text corpora. We fine-tuned 32 domain-specific language models, evaluated them thoroughly on 24 established benchmarks and conducted manual reviews with clinicians. Additionally, we expanded our toolkit by introducing query and search functions, while also standardizing and integrating functions from third-party libraries. The toolkit, its models, and associated data are publicly available via https://github.com/Yale-LILY/MedGen.
EHRKit: A Python Natural Language Processing Toolkit for Electronic Health Record Texts
Apr 13, 2022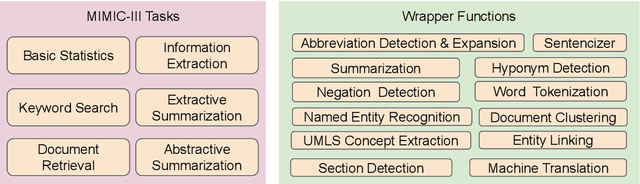


The Electronic Health Record (EHR) is an essential part of the modern medical system and impacts healthcare delivery, operations, and research. Unstructured text is attracting much attention despite structured information in the EHRs and has become an exciting research field. The success of the recent neural Natural Language Processing (NLP) method has led to a new direction for processing unstructured clinical notes. In this work, we create a python library for clinical texts, EHRKit. This library contains two main parts: MIMIC-III-specific functions and tasks specific functions. The first part introduces a list of interfaces for accessing MIMIC-III NOTEEVENTS data, including basic search, information retrieval, and information extraction. The second part integrates many third-party libraries for up to 12 off-shelf NLP tasks such as named entity recognition, summarization, machine translation, etc.