 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemodeLing: A Novel Dataset for Testing Linguistic Reasoning in Language Models
Jun 24, 2024We introduce modeLing, a novel benchmark of Linguistics Olympiad-style puzzles which tests few-shot reasoning in AI systems. Solving these puzzles necessitates inferring aspects of a language's grammatical structure from a small number of examples. Such puzzles provide a natural testbed for language models, as they require compositional generalization and few-shot inductive reasoning. Consisting solely of new puzzles written specifically for this work, modeLing has no risk of appearing in the training data of existing AI systems: this ameliorates the risk of data leakage, a potential confounder for many prior evaluations of reasoning. Evaluating several large open source language models and GPT on our benchmark, we observe non-negligible accuracy, demonstrating few-shot emergent reasoning ability which cannot merely be attributed to shallow memorization. However, imperfect model performance suggests that modeLing can be used to measure further progress in linguistic reasoning.
FeTaQA: Free-form Table Question Answering
Apr 01, 2021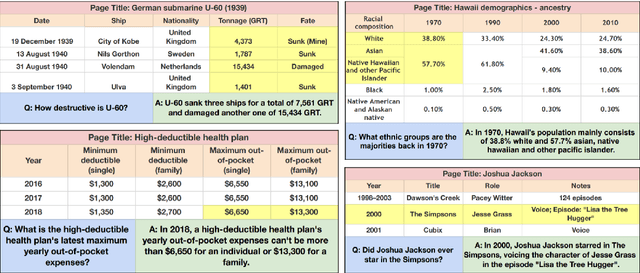

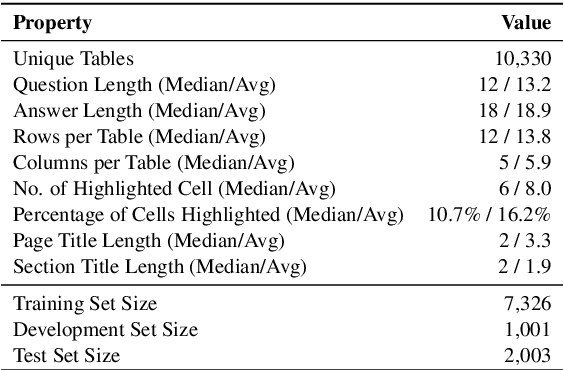
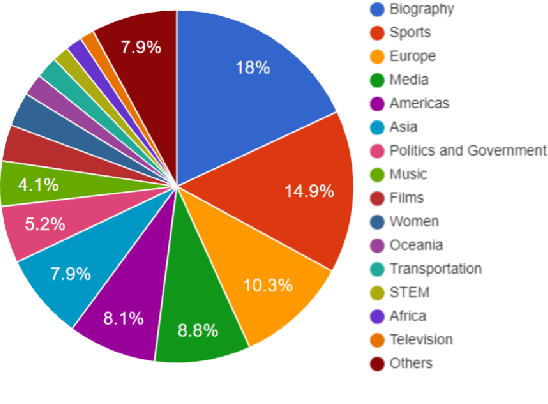
Existing table question answering datasets contain abundant factual questions that primarily evaluate the query and schema comprehension capability of a system, but they fail to include questions that require complex reasoning and integration of information due to the constraint of the associated short-form answers. To address these issues and to demonstrate the full challenge of table question answering, we introduce FeTaQA, a new dataset with 10K Wikipedia-based {table, question, free-form answer, supporting table cells} pairs. FeTaQA yields a more challenging table question answering setting because it requires generating free-form text answers after retrieval, inference, and integration of multiple discontinuous facts from a structured knowledge source. Unlike datasets of generative QA over text in which answers are prevalent with copies of short text spans from the source, answers in our dataset are human-generated explanations involving entities and their high-level relations. We provide two benchmark methods for the proposed task: a pipeline method based on semantic-parsing-based QA systems and an end-to-end method based on large pretrained text generation models, and show that FeTaQA poses a challenge for both methods.