 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemodeLing: A Novel Dataset for Testing Linguistic Reasoning in Language Models
Jun 24, 2024We introduce modeLing, a novel benchmark of Linguistics Olympiad-style puzzles which tests few-shot reasoning in AI systems. Solving these puzzles necessitates inferring aspects of a language's grammatical structure from a small number of examples. Such puzzles provide a natural testbed for language models, as they require compositional generalization and few-shot inductive reasoning. Consisting solely of new puzzles written specifically for this work, modeLing has no risk of appearing in the training data of existing AI systems: this ameliorates the risk of data leakage, a potential confounder for many prior evaluations of reasoning. Evaluating several large open source language models and GPT on our benchmark, we observe non-negligible accuracy, demonstrating few-shot emergent reasoning ability which cannot merely be attributed to shallow memorization. However, imperfect model performance suggests that modeLing can be used to measure further progress in linguistic reasoning.
Classifying Autism from Crowdsourced Semi-Structured Speech Recordings: A Machine Learning Approach
Jan 04, 2022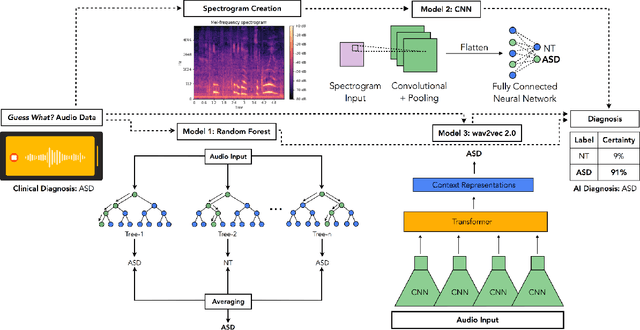

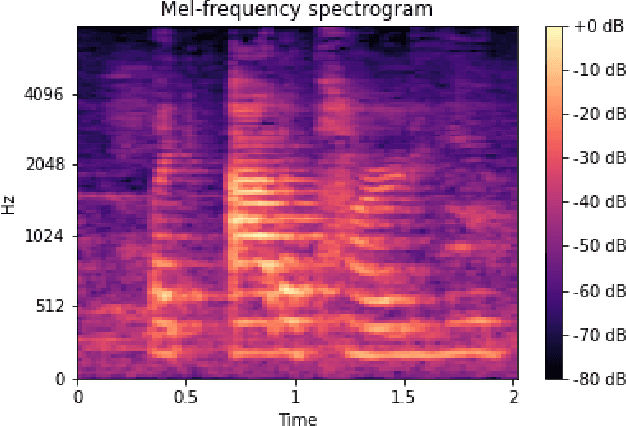
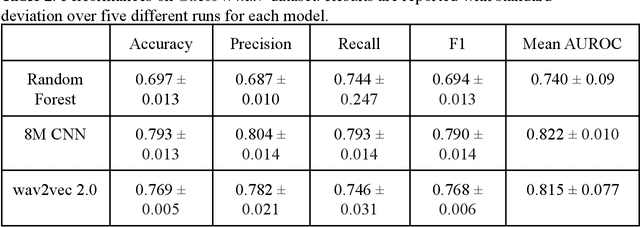
Autism spectrum disorder (ASD) is a neurodevelopmental disorder which results in altered behavior, social development, and communication patterns. In past years, autism prevalence has tripled, with 1 in 54 children now affected. Given that traditional diagnosis is a lengthy, labor-intensive process, significant attention has been given to developing systems that automatically screen for autism. Prosody abnormalities are among the clearest signs of autism, with affected children displaying speech idiosyncrasies including echolalia, monotonous intonation, atypical pitch, and irregular linguistic stress patterns. In this work, we present a suite of machine learning approaches to detect autism in self-recorded speech audio captured from autistic and neurotypical (NT) children in home environments. We consider three methods to detect autism in child speech: first, Random Forests trained on extracted audio features (including Mel-frequency cepstral coefficients); second, convolutional neural networks (CNNs) trained on spectrograms; and third, fine-tuned wav2vec 2.0--a state-of-the-art Transformer-based ASR model. We train our classifiers on our novel dataset of cellphone-recorded child speech audio curated from Stanford's Guess What? mobile game, an app designed to crowdsource videos of autistic and neurotypical children in a natural home environment. The Random Forest classifier achieves 70% accuracy, the fine-tuned wav2vec 2.0 model achieves 77% accuracy, and the CNN achieves 79% accuracy when classifying children's audio as either ASD or NT. Our models were able to predict autism status when training on a varied selection of home audio clips with inconsistent recording quality, which may be more generalizable to real world conditions. These results demonstrate that machine learning methods offer promise in detecting autism automatically from speech without specialized equipment.