 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Interventions on Continuous Variables: A Case Study on Verb Bias in Steering Vectors for In-Context Learning
May 28, 2026Causal interventions in language model representations have largely targeted discrete features, like grammatical number. However, language models must also make use of features that are graded. We introduce a method for causal intervention on continuous variables: given activation vectors paired with a graded target variable, we localize a low-dimensional direction for that variable and use this direction to edit a vectors toward counterfactual target values. We apply this method to a continuous feature that is well-studied in psycholinguistics, namely verb bias (which reflects which syntactic structures tend to follow a given verb). We show that verb bias is causally represented in steering vectors extracted from large language models: counterfactual edits to verb bias systematically shift downstream structural preferences. Verb bias has also previously been linked to in-context learning; in further analyses, we find that steering vectors encode error signals that could drive the error-driven update behavior seen in in-context learning but that these aspects of the steering vectors are not causally used in downstream production. Overall, these results show causal interventions can be applied to continuous variables, though connecting continuous variables to in-context learning remains a challenge.
Collocational bootstrapping: A hypothesis about the learning of subject-verb agreement in humans and neural networks
May 19, 2026In what ways might statistical signals in linguistic input assist with the acquisition of syntax? Here we hypothesize a mechanism called collocational bootstrapping, in which regularities in word co-occurrence patterns can provide cues to syntactic dependencies. We investigate whether this mechanism can support the acquisition of English subject-verb agreement. First, we simulate language acquisition by training neural networks on synthetic datasets that vary in how predictable their subject-verb pairings are. We find that there is a range of variability levels at which these statistical learners robustly learn subject-verb agreement. We then analyze the variability of subject-verb pairings in child-directed language, and we find that the variability in such data falls within the range that supported robust generalization in our computational simulations. Taken together, these results suggest that collocational bootstrapping is a viable learning strategy for the type of input that children receive.
Not-So-Strange Love: Language Models and Generative Linguistic Theories are More Compatible than They Appear
May 11, 2026Futrell and Mahowald (2025) frame the success of neural language models (LMs) as supporting gradient, usage-based linguistic theories. I argue that LMs can also instantiate theories based on formal structures - the types of theories seen in the generative tradition. This argument expands the space of theories that can be tested with LMs, potentially enabling reconciliations between usage-based and generative accounts.
What Exactly do Children Receive in Language Acquisition? A Case Study on CHILDES with Automated Detection of Filler-Gap Dependencies
Mar 02, 2026Children's acquisition of filler-gap dependencies has been argued by some to depend on innate grammatical knowledge, while others suggest that the distributional evidence available in child-directed speech suffices. Unfortunately, the relevant input is difficult to quantify at scale with fine granularity, making this question difficult to resolve. We present a system that identifies three core filler-gap constructions in spoken English corpora -- matrix wh-questions, embedded wh-questions, and relative clauses -- and further identifies the extraction site (i.e., subject vs. object vs. adjunct). Our approach combines constituency and dependency parsing, leveraging their complementary strengths for construction classification and extraction site identification. We validate the system on human-annotated data and find that it scores well across most categories. Applying the system to 57 English CHILDES corpora, we are able to characterize children's filler-gap input and their filler-gap production trajectories over the course of development, including construction-specific frequencies and extraction-site asymmetries. The resulting fine-grained labels enable future work in both acquisition and computational studies, which we demonstrate with a case study using filtered corpus training with language models.
Evaluating the Usage of African-American Vernacular English in Large Language Models
Feb 25, 2026In AI, most evaluations of natural language understanding tasks are conducted in standardized dialects such as Standard American English (SAE). In this work, we investigate how accurately large language models (LLMs) represent African American Vernacular English (AAVE). We analyze three LLMs to compare their usage of AAVE to the usage of humans who natively speak AAVE. We first analyzed interviews from the Corpus of Regional African American Language and TwitterAAE to identify the typical contexts where people use AAVE grammatical features such as ain't. We then prompted the LLMs to produce text in AAVE and compared the model-generated text to human usage patterns. We find that, in many cases, there are substantial differences between AAVE usage in LLMs and humans: LLMs usually underuse and misuse grammatical features characteristic of AAVE. Furthermore, through sentiment analysis and manual inspection, we found that the models replicated stereotypes about African Americans. These results highlight the need for more diversity in training data and the incorporation of fairness methods to mitigate the perpetuation of stereotypes.
The Structural Sources of Verb Meaning Revisited: Large Language Models Display Syntactic Bootstrapping
Aug 17, 2025Syntactic bootstrapping (Gleitman, 1990) is the hypothesis that children use the syntactic environments in which a verb occurs to learn its meaning. In this paper, we examine whether large language models exhibit a similar behavior. We do this by training RoBERTa and GPT-2 on perturbed datasets where syntactic information is ablated. Our results show that models' verb representation degrades more when syntactic cues are removed than when co-occurrence information is removed. Furthermore, the representation of mental verbs, for which syntactic bootstrapping has been shown to be particularly crucial in human verb learning, is more negatively impacted in such training regimes than physical verbs. In contrast, models' representation of nouns is affected more when co-occurrences are distorted than when syntax is distorted. In addition to reinforcing the important role of syntactic bootstrapping in verb learning, our results demonstrated the viability of testing developmental hypotheses on a larger scale through manipulating the learning environments of large language models.
Learning to Reason via Mixture-of-Thought for Logical Reasoning
May 21, 2025Human beings naturally utilize multiple reasoning modalities to learn and solve logical problems, i.e., different representational formats such as natural language, code, and symbolic logic. In contrast, most existing LLM-based approaches operate with a single reasoning modality during training, typically natural language. Although some methods explored modality selection or augmentation at inference time, the training process remains modality-blind, limiting synergy among modalities. To fill in this gap, we propose Mixture-of-Thought (MoT), a framework that enables LLMs to reason across three complementary modalities: natural language, code, and a newly introduced symbolic modality, truth-table, which systematically enumerates logical cases and partially mitigates key failure modes in natural language reasoning. MoT adopts a two-phase design: (1) self-evolving MoT training, which jointly learns from filtered, self-generated rationales across modalities; and (2) MoT inference, which fully leverages the synergy of three modalities to produce better predictions. Experiments on logical reasoning benchmarks including FOLIO and ProofWriter demonstrate that our MoT framework consistently and significantly outperforms strong LLM baselines with single-modality chain-of-thought approaches, achieving up to +11.7pp average accuracy gain. Further analyses show that our MoT framework benefits both training and inference stages; that it is particularly effective on harder logical reasoning problems; and that different modalities contribute complementary strengths, with truth-table reasoning helping to overcome key bottlenecks in natural language inference.
Creativity or Brute Force? Using Brainteasers as a Window into the Problem-Solving Abilities of Large Language Models
May 16, 2025
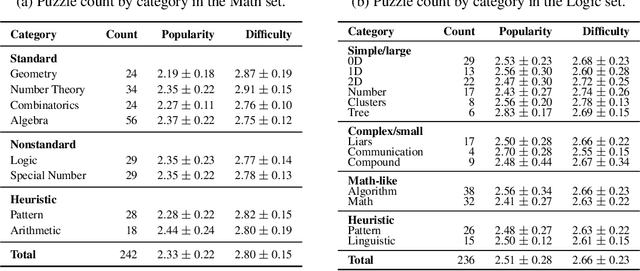

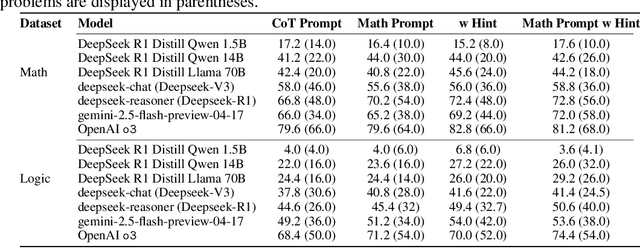
Accuracy remains a standard metric for evaluating AI systems, but it offers limited insight into how models arrive at their solutions. In this work, we introduce a benchmark based on brainteasers written in long narrative form to probe more deeply into the types of reasoning strategies that models use. Brainteasers are well-suited for this goal because they can be solved with multiple approaches, such as a few-step solution that uses a creative insight or a longer solution that uses more brute force. We investigate large language models (LLMs) across multiple layers of reasoning, focusing not only on correctness but also on the quality and creativity of their solutions. We investigate many aspects of the reasoning process: (1) semantic parsing of the brainteasers into precise mathematical competition style formats; (2) generating solutions from these mathematical forms; (3) self-correcting solutions based on gold solutions; (4) producing step-by-step sketches of solutions; and (5) making use of hints. We find that LLMs are in many cases able to find creative, insightful solutions to brainteasers, suggesting that they capture some of the capacities needed to solve novel problems in creative ways. Nonetheless, there also remain situations where they rely on brute force despite the availability of more efficient, creative solutions, highlighting a potential direction for improvement in the reasoning abilities of LLMs.
Identifying and Mitigating the Influence of the Prior Distribution in Large Language Models
Apr 17, 2025Large language models (LLMs) sometimes fail to respond appropriately to deterministic tasks -- such as counting or forming acronyms -- because the implicit prior distribution they have learned over sequences of tokens influences their responses. In this work, we show that, in at least some cases, LLMs actually compute the information needed to perform these tasks correctly, and we identify some interventions that can allow them to access this information to improve their performance. First, we show that simply prompting the language model to not rely on its prior knowledge leads to dramatic improvements in prior-dominated tasks. We then use mechanistic interpretability techniques to localize the prior within the LLM and manipulate the extent to which that prior influences its responses. Specifically, we show that it is possible to identify layers of the underlying neural network that correlate with the prior probability of a response and that lightweight finetuning of these layers with basic prompts on prior-dominated tasks achieves high performance on held-out answers. These results suggest that the information required to produce a correct response is contained within the representations of the problems formed by the models. Furthermore, we show that this finetuning is significantly more effective for prior-dominated tasks, and that the error after finetuning is no longer correlated with the prior. Our results suggest that it may be possible to define effective methods for manipulating the extent to which LLMs rely upon their priors in solving problems, potentially increasing their performance in settings where LLMs hallucinate for reasons related to the prior probability of token sequences.
Convolutional Neural Networks Can (Meta-)Learn the Same-Different Relation
Apr 01, 2025While convolutional neural networks (CNNs) have come to match and exceed human performance in many settings, the tasks these models optimize for are largely constrained to the level of individual objects, such as classification and captioning. Humans remain vastly superior to CNNs in visual tasks involving relations, including the ability to identify two objects as `same' or `different'. A number of studies have shown that while CNNs can be coaxed into learning the same-different relation in some settings, they tend to generalize poorly to other instances of this relation. In this work we show that the same CNN architectures that fail to generalize the same-different relation with conventional training are able to succeed when trained via meta-learning, which explicitly encourages abstraction and generalization across tasks.