 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Bayesian Meta-Learning for Low-Rank Adaptation of Large Language Models
Aug 19, 2025Fine-tuning large language models (LLMs) with low-rank adaptaion (LoRA) is a cost-effective way to incorporate information from a specific dataset. However, it is often unclear how well the fine-tuned LLM will generalize, i.e., how well it will perform on unseen datasets. Methods have been proposed to improve generalization by optimizing with in-context prompts, or by using meta-learning to fine-tune LLMs. However, these methods are expensive in memory and computation, requiring either long-context prompts or saving copies of parameters and using second-order gradient updates. To address these challenges, we propose Amortized Bayesian Meta-Learning for LoRA (ABMLL). This method builds on amortized Bayesian meta-learning for smaller models, adapting this approach to LLMs while maintaining its computational efficiency. We reframe task-specific and global parameters in the context of LoRA and use a set of new hyperparameters to balance reconstruction accuracy and the fidelity of task-specific parameters to the global ones. ABMLL provides effective generalization and scales to large models such as Llama3-8B. Furthermore, as a result of using a Bayesian framework, ABMLL provides improved uncertainty quantification. We test ABMLL on Unified-QA and CrossFit datasets and find that it outperforms existing methods on these benchmarks in terms of both accuracy and expected calibration error.
Identifying and Mitigating the Influence of the Prior Distribution in Large Language Models
Apr 17, 2025Large language models (LLMs) sometimes fail to respond appropriately to deterministic tasks -- such as counting or forming acronyms -- because the implicit prior distribution they have learned over sequences of tokens influences their responses. In this work, we show that, in at least some cases, LLMs actually compute the information needed to perform these tasks correctly, and we identify some interventions that can allow them to access this information to improve their performance. First, we show that simply prompting the language model to not rely on its prior knowledge leads to dramatic improvements in prior-dominated tasks. We then use mechanistic interpretability techniques to localize the prior within the LLM and manipulate the extent to which that prior influences its responses. Specifically, we show that it is possible to identify layers of the underlying neural network that correlate with the prior probability of a response and that lightweight finetuning of these layers with basic prompts on prior-dominated tasks achieves high performance on held-out answers. These results suggest that the information required to produce a correct response is contained within the representations of the problems formed by the models. Furthermore, we show that this finetuning is significantly more effective for prior-dominated tasks, and that the error after finetuning is no longer correlated with the prior. Our results suggest that it may be possible to define effective methods for manipulating the extent to which LLMs rely upon their priors in solving problems, potentially increasing their performance in settings where LLMs hallucinate for reasons related to the prior probability of token sequences.
Using the Tools of Cognitive Science to Understand Large Language Models at Different Levels of Analysis
Mar 17, 2025Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical difficulties in understanding the human mind, we argue that methods developed in cognitive science can be useful for understanding large language models. We propose a framework for applying these methods based on Marr's three levels of analysis. By revisiting established cognitive science techniques relevant to each level and illustrating their potential to yield insights into the behavior and internal organization of large language models, we aim to provide a toolkit for making sense of these new kinds of minds.
What Should Embeddings Embed? Autoregressive Models Represent Latent Generating Distributions
Jun 06, 2024



Autoregressive language models have demonstrated a remarkable ability to extract latent structure from text. The embeddings from large language models have been shown to capture aspects of the syntax and semantics of language. But what {\em should} embeddings represent? We connect the autoregressive prediction objective to the idea of constructing predictive sufficient statistics to summarize the information contained in a sequence of observations, and use this connection to identify three settings where the optimal content of embeddings can be identified: independent identically distributed data, where the embedding should capture the sufficient statistics of the data; latent state models, where the embedding should encode the posterior distribution over states given the data; and discrete hypothesis spaces, where the embedding should reflect the posterior distribution over hypotheses given the data. We then conduct empirical probing studies to show that transformers encode these three kinds of latent generating distributions, and that they perform well in out-of-distribution cases and without token memorization in these settings.
Analyzing the Benefits of Prototypes for Semi-Supervised Category Learning
Jun 04, 2024



Categories can be represented at different levels of abstraction, from prototypes focused on the most typical members to remembering all observed exemplars of the category. These representations have been explored in the context of supervised learning, where stimuli are presented with known category labels. We examine the benefits of prototype-based representations in a less-studied domain: semi-supervised learning, where agents must form unsupervised representations of stimuli before receiving category labels. We study this problem in a Bayesian unsupervised learning model called a variational auto-encoder, and we draw on recent advances in machine learning to implement a prior that encourages the model to use abstract prototypes to represent data. We apply this approach to image datasets and show that forming prototypes can improve semi-supervised category learning. Additionally, we study the latent embeddings of the models and show that these prototypes allow the models to form clustered representations without supervision, contributing to their success in downstream categorization performance.
Using Contrastive Learning with Generative Similarity to Learn Spaces that Capture Human Inductive Biases
May 29, 2024



Humans rely on strong inductive biases to learn from few examples and abstract useful information from sensory data. Instilling such biases in machine learning models has been shown to improve their performance on various benchmarks including few-shot learning, robustness, and alignment. However, finding effective training procedures to achieve that goal can be challenging as psychologically-rich training data such as human similarity judgments are expensive to scale, and Bayesian models of human inductive biases are often intractable for complex, realistic domains. Here, we address this challenge by introducing a Bayesian notion of generative similarity whereby two datapoints are considered similar if they are likely to have been sampled from the same distribution. This measure can be applied to complex generative processes, including probabilistic programs. We show that generative similarity can be used to define a contrastive learning objective even when its exact form is intractable, enabling learning of spatial embeddings that express specific inductive biases. We demonstrate the utility of our approach by showing how it can be used to capture human inductive biases for geometric shapes, and to better distinguish different abstract drawing styles that are parameterized by probabilistic programs.
Deep de Finetti: Recovering Topic Distributions from Large Language Models
Dec 21, 2023Large language models (LLMs) can produce long, coherent passages of text, suggesting that LLMs, although trained on next-word prediction, must represent the latent structure that characterizes a document. Prior work has found that internal representations of LLMs encode one aspect of latent structure, namely syntax; here we investigate a complementary aspect, namely the document's topic structure. We motivate the hypothesis that LLMs capture topic structure by connecting LLM optimization to implicit Bayesian inference. De Finetti's theorem shows that exchangeable probability distributions can be represented as a mixture with respect to a latent generating distribution. Although text is not exchangeable at the level of syntax, exchangeability is a reasonable starting assumption for topic structure. We thus hypothesize that predicting the next token in text will lead LLMs to recover latent topic distributions. We examine this hypothesis using Latent Dirichlet Allocation (LDA), an exchangeable probabilistic topic model, as a target, and we show that the representations formed by LLMs encode both the topics used to generate synthetic data and those used to explain natural corpus data.
Transport Score Climbing: Variational Inference Using Forward KL and Adaptive Neural Transport
Feb 07, 2022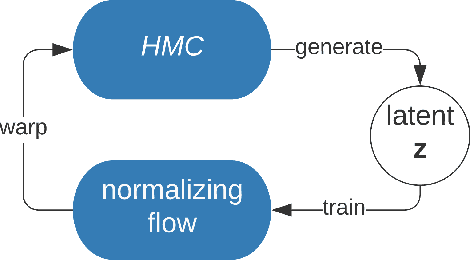
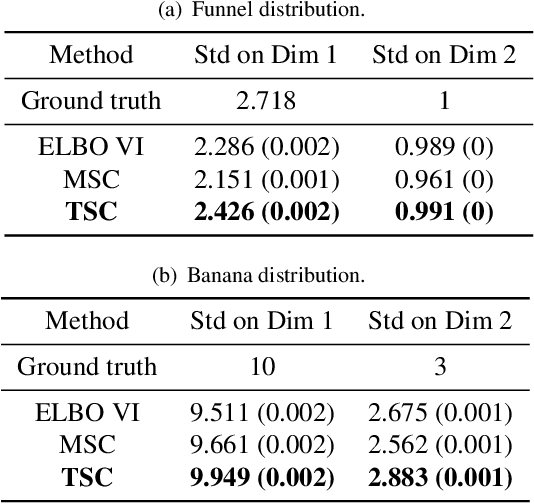
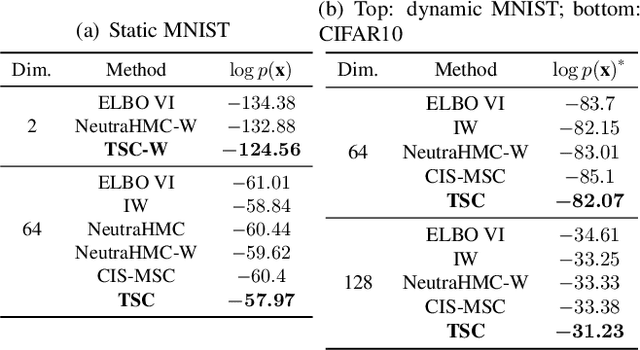
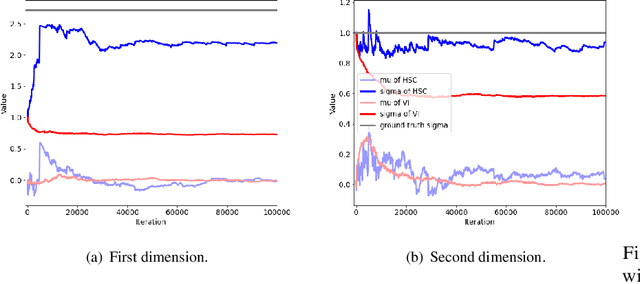
Variational inference often minimizes the "reverse" Kullbeck-Leibler (KL) KL(q||p) from the approximate distribution q to the posterior p. Recent work studies the "forward" KL KL(p||q), which unlike reverse KL does not lead to variational approximations that underestimate uncertainty. This paper introduces Transport Score Climbing (TSC), a method that optimizes KL(p||q) by using Hamiltonian Monte Carlo (HMC) and a novel adaptive transport map. The transport map improves the trajectory of HMC by acting as a change of variable between the latent variable space and a warped space. TSC uses HMC samples to dynamically train the transport map while optimizing KL(p||q). TSC leverages synergies, where better transport maps lead to better HMC sampling, which then leads to better transport maps. We demonstrate TSC on synthetic and real data. We find that TSC achieves competitive performance when training variational autoencoders on large-scale data.
Variational Combinatorial Sequential Monte Carlo Methods for Bayesian Phylogenetic Inference
Jun 17, 2021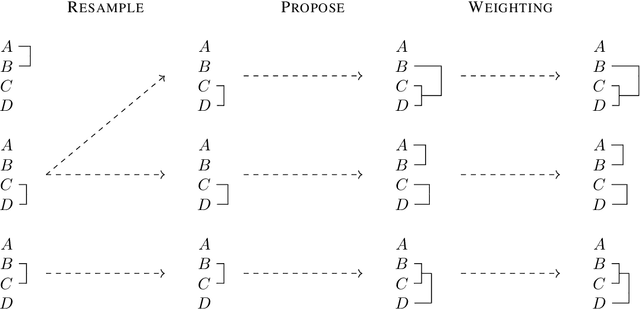
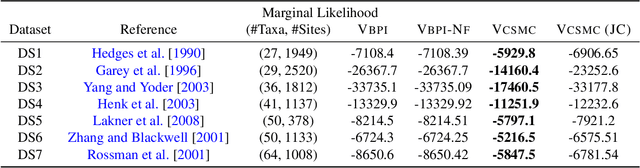
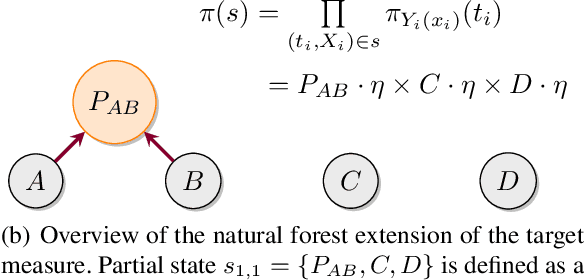
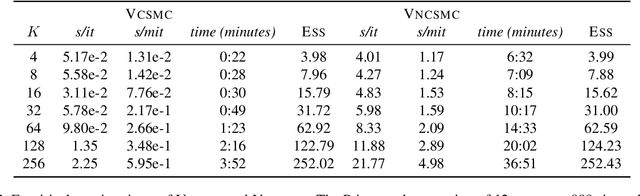
Bayesian phylogenetic inference is often conducted via local or sequential search over topologies and branch lengths using algorithms such as random-walk Markov chain Monte Carlo (MCMC) or Combinatorial Sequential Monte Carlo (CSMC). However, when MCMC is used for evolutionary parameter learning, convergence requires long runs with inefficient exploration of the state space. We introduce Variational Combinatorial Sequential Monte Carlo (VCSMC), a powerful framework that establishes variational sequential search to learn distributions over intricate combinatorial structures. We then develop nested CSMC, an efficient proposal distribution for CSMC and prove that nested CSMC is an exact approximation to the (intractable) locally optimal proposal. We use nested CSMC to define a second objective, VNCSMC which yields tighter lower bounds than VCSMC. We show that VCSMC and VNCSMC are computationally efficient and explore higher probability spaces than existing methods on a range of tasks.