 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Using Contrastive Learning with Generative Similarity to Learn Spaces that Capture Human Inductive Biases
May 29, 2024



Humans rely on strong inductive biases to learn from few examples and abstract useful information from sensory data. Instilling such biases in machine learning models has been shown to improve their performance on various benchmarks including few-shot learning, robustness, and alignment. However, finding effective training procedures to achieve that goal can be challenging as psychologically-rich training data such as human similarity judgments are expensive to scale, and Bayesian models of human inductive biases are often intractable for complex, realistic domains. Here, we address this challenge by introducing a Bayesian notion of generative similarity whereby two datapoints are considered similar if they are likely to have been sampled from the same distribution. This measure can be applied to complex generative processes, including probabilistic programs. We show that generative similarity can be used to define a contrastive learning objective even when its exact form is intractable, enabling learning of spatial embeddings that express specific inductive biases. We demonstrate the utility of our approach by showing how it can be used to capture human inductive biases for geometric shapes, and to better distinguish different abstract drawing styles that are parameterized by probabilistic programs.
Comparing Abstraction in Humans and Large Language Models Using Multimodal Serial Reproduction
Feb 06, 2024



Humans extract useful abstractions of the world from noisy sensory data. Serial reproduction allows us to study how people construe the world through a paradigm similar to the game of telephone, where one person observes a stimulus and reproduces it for the next to form a chain of reproductions. Past serial reproduction experiments typically employ a single sensory modality, but humans often communicate abstractions of the world to each other through language. To investigate the effect language on the formation of abstractions, we implement a novel multimodal serial reproduction framework by asking people who receive a visual stimulus to reproduce it in a linguistic format, and vice versa. We ran unimodal and multimodal chains with both humans and GPT-4 and find that adding language as a modality has a larger effect on human reproductions than GPT-4's. This suggests human visual and linguistic representations are more dissociable than those of GPT-4.
Human-Like Geometric Abstraction in Large Pre-trained Neural Networks
Feb 06, 2024
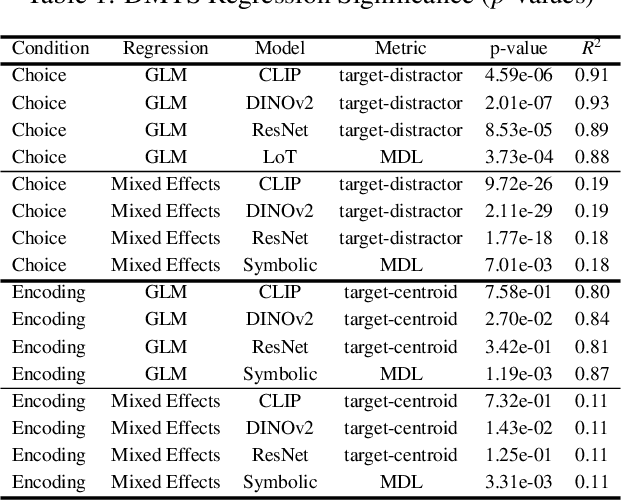


Humans possess a remarkable capacity to recognize and manipulate abstract structure, which is especially apparent in the domain of geometry. Recent research in cognitive science suggests neural networks do not share this capacity, concluding that human geometric abilities come from discrete symbolic structure in human mental representations. However, progress in artificial intelligence (AI) suggests that neural networks begin to demonstrate more human-like reasoning after scaling up standard architectures in both model size and amount of training data. In this study, we revisit empirical results in cognitive science on geometric visual processing and identify three key biases in geometric visual processing: a sensitivity towards complexity, regularity, and the perception of parts and relations. We test tasks from the literature that probe these biases in humans and find that large pre-trained neural network models used in AI demonstrate more human-like abstract geometric processing.
Learning to Abstract Visuomotor Mappings using Meta-Reinforcement Learning
Feb 05, 2024



We investigated the human capacity to acquire multiple visuomotor mappings for de novo skills. Using a grid navigation paradigm, we tested whether contextual cues implemented as different "grid worlds", allow participants to learn two distinct key-mappings more efficiently. Our results indicate that when contextual information is provided, task performance is significantly better. The same held true for meta-reinforcement learning agents that differed in whether or not they receive contextual information when performing the task. We evaluated their accuracy in predicting human performance in the task and analyzed their internal representations. The results indicate that contextual cues allow the formation of separate representations in space and time when using different visuomotor mappings, whereas the absence of them favors sharing one representation. While both strategies can allow learning of multiple visuomotor mappings, we showed contextual cues provide a computational advantage in terms of how many mappings can be learned.
Using Natural Language and Program Abstractions to Instill Human Inductive Biases in Machines
May 23, 2022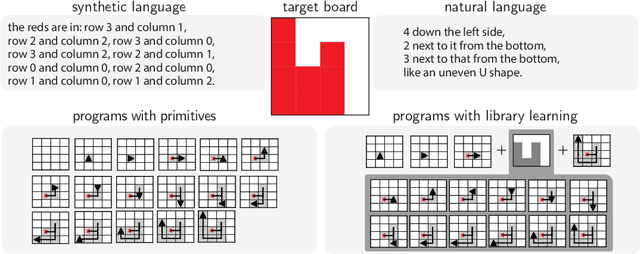
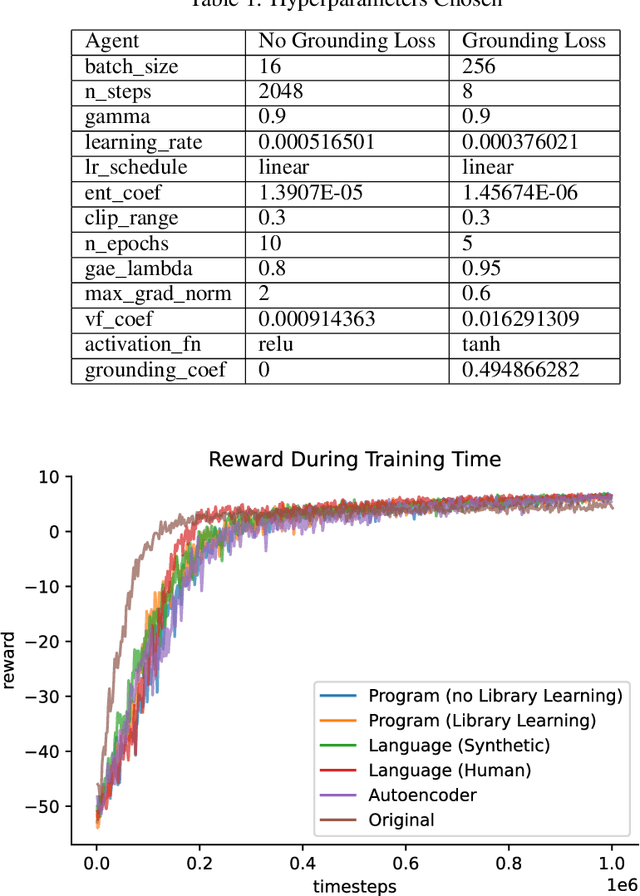
Strong inductive biases are a key component of human intelligence, allowing people to quickly learn a variety of tasks. Although meta-learning has emerged as an approach for endowing neural networks with useful inductive biases, agents trained by meta-learning may acquire very different strategies from humans. We show that co-training these agents on predicting representations from natural language task descriptions and from programs induced to generate such tasks guides them toward human-like inductive biases. Human-generated language descriptions and program induction with library learning both result in more human-like behavior in downstream meta-reinforcement learning agents than less abstract controls (synthetic language descriptions, program induction without library learning), suggesting that the abstraction supported by these representations is key.
Disentangling Abstraction from Statistical Pattern Matching in Human and Machine Learning
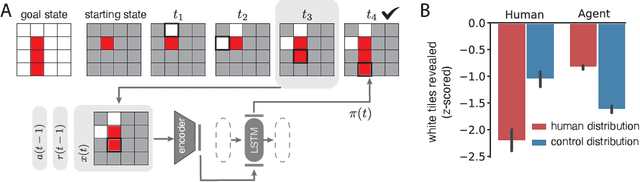
Apr 04, 2022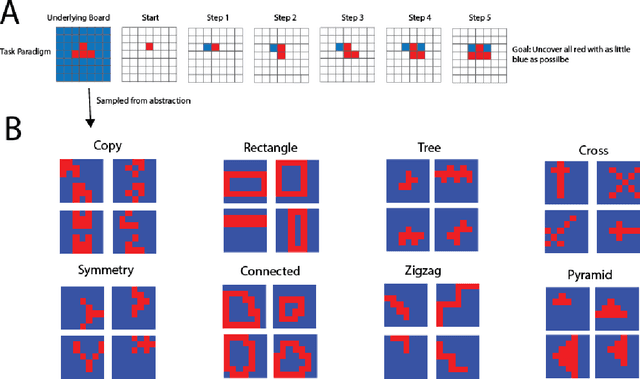
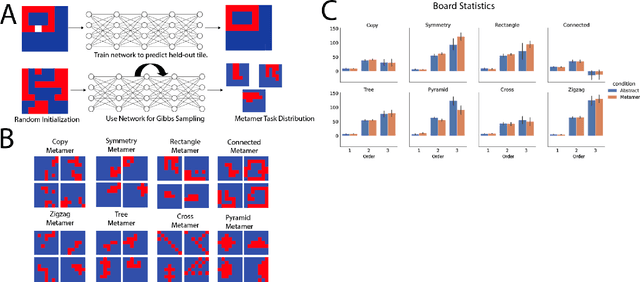
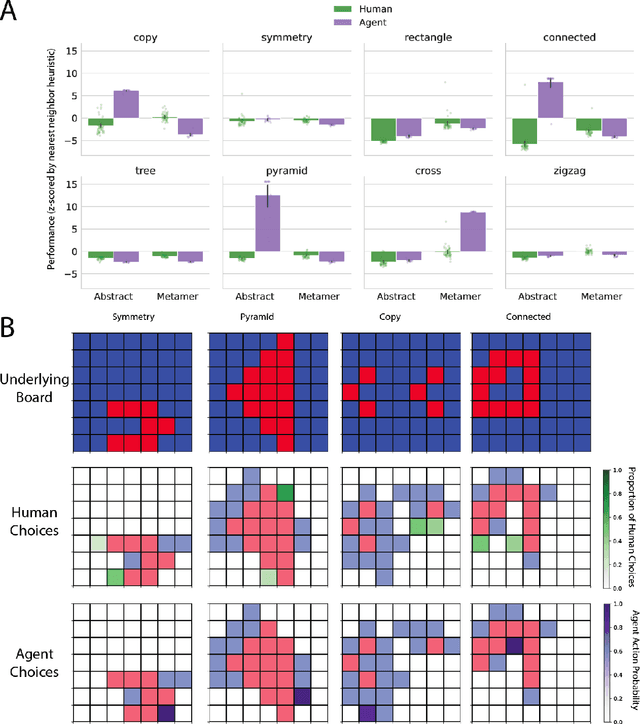
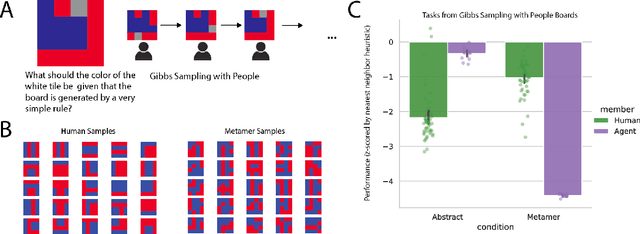
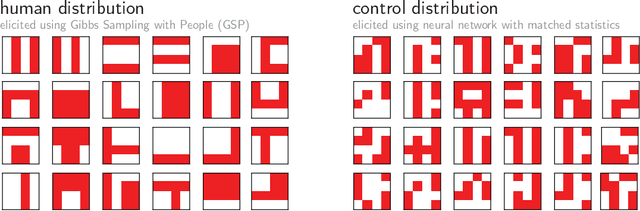
The ability to acquire abstract knowledge is a hallmark of human intelligence and is believed by many to be one of the core differences between humans and neural network models. Agents can be endowed with an inductive bias towards abstraction through meta-learning, where they are trained on a distribution of tasks that share some abstract structure that can be learned and applied. However, because neural networks are hard to interpret, it can be difficult to tell whether agents have learned the underlying abstraction, or alternatively statistical patterns that are characteristic of that abstraction. In this work, we compare the performance of humans and agents in a meta-reinforcement learning paradigm in which tasks are generated from abstract rules. We define a novel methodology for building "task metamers" that closely match the statistics of the abstract tasks but use a different underlying generative process, and evaluate performance on both abstract and metamer tasks. In our first set of experiments, we found that humans perform better at abstract tasks than metamer tasks whereas a widely-used meta-reinforcement learning agent performs worse on the abstract tasks than the matched metamers. In a second set of experiments, we base the tasks on abstractions derived directly from empirically identified human priors. We utilize the same procedure to generate corresponding metamer tasks, and see the same double dissociation between humans and agents. This work provides a foundation for characterizing differences between humans and machine learning that can be used in future work towards developing machines with human-like behavior.
Meta-Learning of Compositional Task Distributions in Humans and Machines
Oct 05, 2020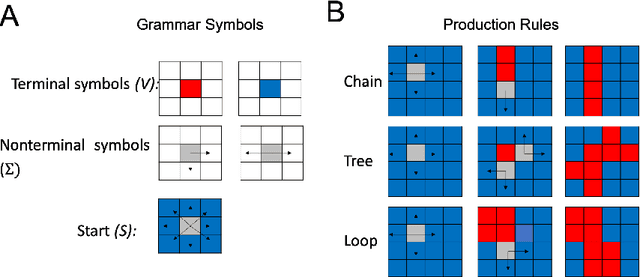
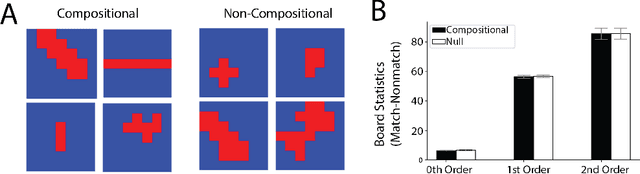
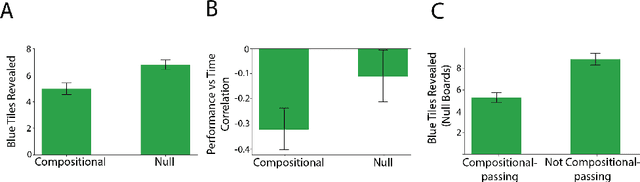
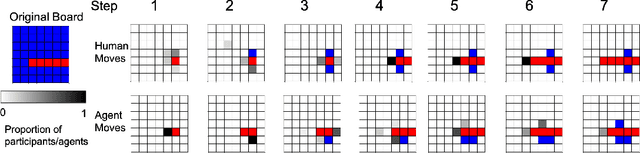
Modern machine learning systems struggle with sample efficiency and are usually trained with enormous amounts of data for each task. This is in sharp contrast with humans, who often learn with very little data. In recent years, meta-learning, in which one trains on a family of tasks (i.e. a task distribution), has emerged as an approach to improving the sample complexity of machine learning systems and to closing the gap between human and machine learning. However, in this paper, we argue that current meta-learning approaches still differ significantly from human learning. We argue that humans learn over tasks by constructing compositional generative models and using these to generalize, whereas current meta-learning methods are biased toward the use of simpler statistical patterns. To highlight this difference, we construct a new meta-reinforcement learning task with a compositional task distribution. We also introduce a novel approach to constructing a "null task distribution" with the same statistical complexity as the compositional distribution but without explicit compositionality. We train a standard meta-learning agent, a recurrent network trained with model-free reinforcement learning, and compare it with human performance across the two task distributions. We find that humans do better in the compositional task distribution whereas the agent does better in the non-compositional null task distribution -- despite comparable statistical complexity. This work highlights a particular difference between human learning and current meta-learning models, introduces a task that displays this difference, and paves the way for future work on human-like meta-learning.