 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Visual and Verbal Learning Through a Child's Egocentric Input
Jun 03, 2026Children learn the meanings of words from a continuous, temporally structured stream of egocentric experience. Recent work shows that neural networks can also learn word-referent mappings from a child's egocentric video recordings, but they cycle through the shuffled data for hundreds of epochs, contrasting with how children actually encounter their environment. We introduce BabyCL, a continual multimodal learning framework that processes the SAYCam dataset in a single chronological pass, combining streaming visual representation learning with an image-text contrastive objective. BabyCL combines a multi-stage temporal segmentation of the stream with a dual replay buffer that independently manages visual and multimodal histories, and it is jointly trained with three contrastive losses on a shared backbone. Under a matched optimization budget, BabyCL outperforms streaming learning baselines on the SAYCam Labeled-S 4AFC benchmark, substantially narrowing the gap to an upper bound of offline training. Ablations show that the gains are robust to the length of the online temporal segmentation window and the eviction rule of the replay buffer. Together, these results show that meaningful word-referent mappings can emerge under training conditions much closer to a child's actual experience.
An explainable transformer circuit for compositional generalization
Feb 19, 2025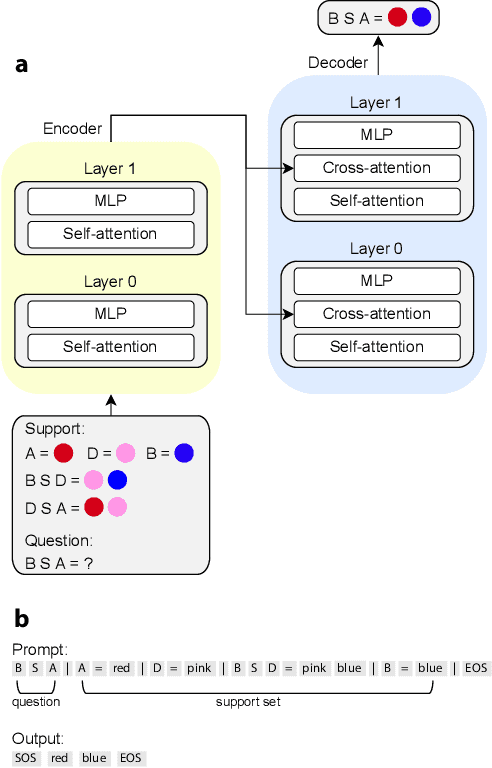
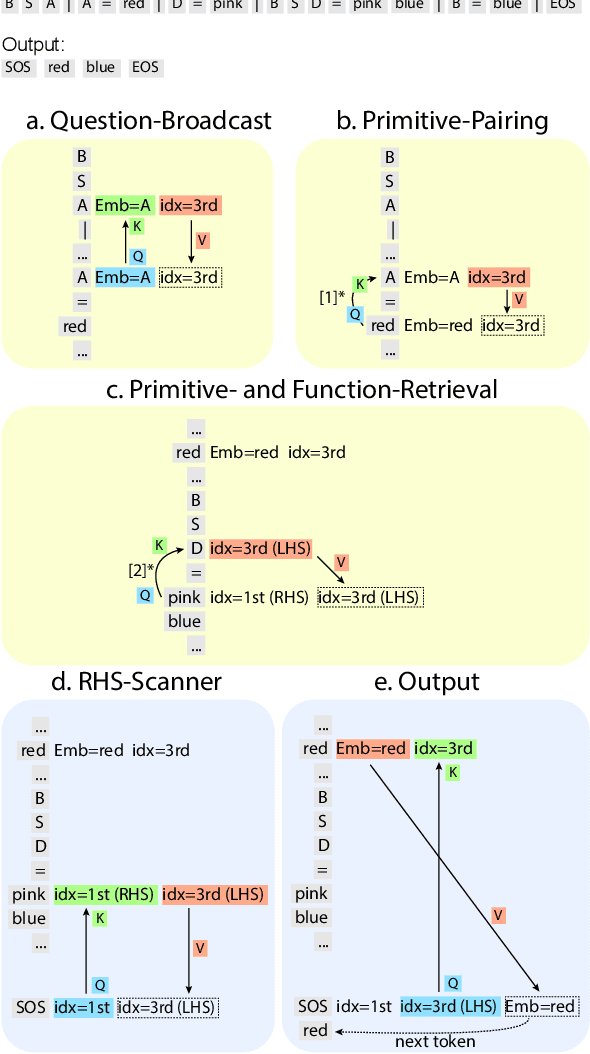
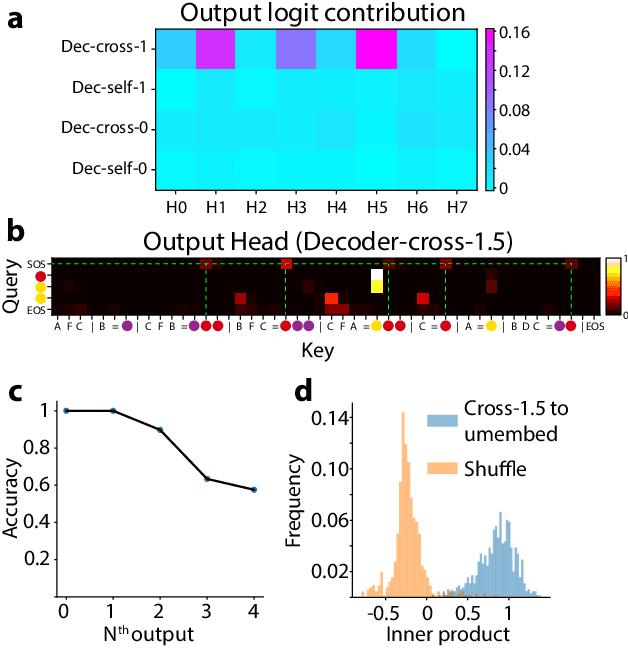
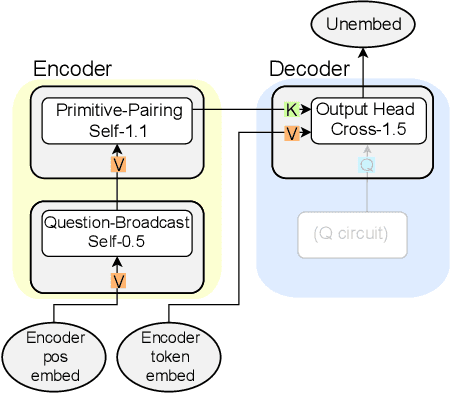
Compositional generalization-the systematic combination of known components into novel structures-remains a core challenge in cognitive science and machine learning. Although transformer-based large language models can exhibit strong performance on certain compositional tasks, the underlying mechanisms driving these abilities remain opaque, calling into question their interpretability. In this work, we identify and mechanistically interpret the circuit responsible for compositional induction in a compact transformer. Using causal ablations, we validate the circuit and formalize its operation using a program-like description. We further demonstrate that this mechanistic understanding enables precise activation edits to steer the model's behavior predictably. Our findings advance the understanding of complex behaviors in transformers and highlight such insights can provide a direct pathway for model control.
CoLLEGe: Concept Embedding Generation for Large Language Models
Mar 22, 2024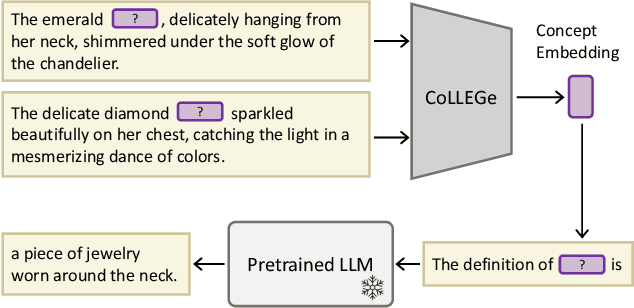

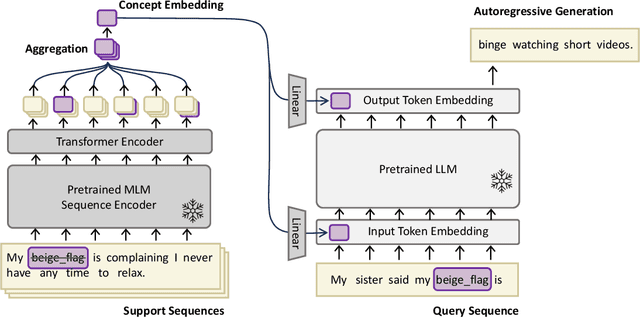

Current language models are unable to quickly learn new concepts on the fly, often requiring a more involved finetuning process to learn robustly. Prompting in-context is not robust to context distractions, and often fails to confer much information about the new concepts. Classic methods for few-shot word learning in NLP, relying on global word vectors, are less applicable to large language models. In this paper, we introduce a novel approach named CoLLEGe (Concept Learning with Language Embedding Generation) to modernize few-shot concept learning. CoLLEGe is a meta-learning framework capable of generating flexible embeddings for new concepts using a small number of example sentences or definitions. Our primary meta-learning objective is simply to facilitate a language model to make next word predictions in forthcoming sentences, making it compatible with language model pretraining. We design a series of tasks to test new concept learning in challenging real-world scenarios, including new word acquisition, definition inference, and verbal reasoning, and demonstrate that our method succeeds in each setting without task-specific training.
Comparing Abstraction in Humans and Large Language Models Using Multimodal Serial Reproduction
Feb 06, 2024



Humans extract useful abstractions of the world from noisy sensory data. Serial reproduction allows us to study how people construe the world through a paradigm similar to the game of telephone, where one person observes a stimulus and reproduces it for the next to form a chain of reproductions. Past serial reproduction experiments typically employ a single sensory modality, but humans often communicate abstractions of the world to each other through language. To investigate the effect language on the formation of abstractions, we implement a novel multimodal serial reproduction framework by asking people who receive a visual stimulus to reproduce it in a linguistic format, and vice versa. We ran unimodal and multimodal chains with both humans and GPT-4 and find that adding language as a modality has a larger effect on human reproductions than GPT-4's. This suggests human visual and linguistic representations are more dissociable than those of GPT-4.
Improving Systematic Generalization Through Modularity and Augmentation
Feb 22, 2022
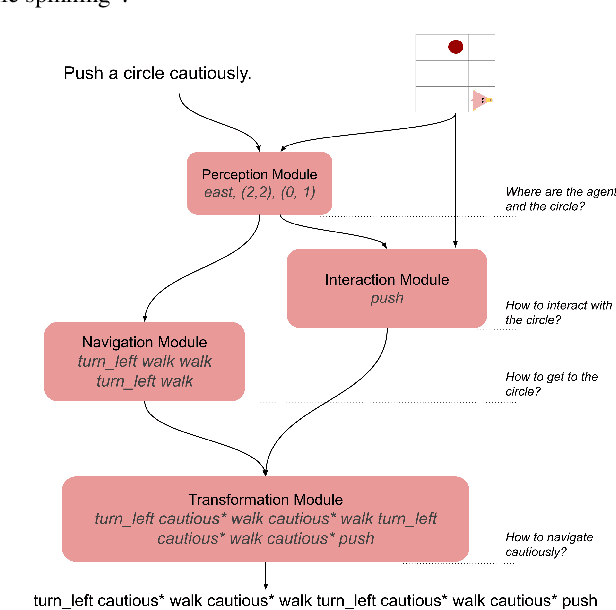
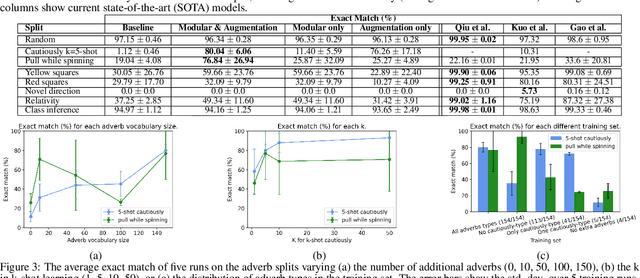
Systematic generalization is the ability to combine known parts into novel meaning; an important aspect of efficient human learning, but a weakness of neural network learning. In this work, we investigate how two well-known modeling principles -- modularity and data augmentation -- affect systematic generalization of neural networks in grounded language learning. We analyze how large the vocabulary needs to be to achieve systematic generalization and how similar the augmented data needs to be to the problem at hand. Our findings show that even in the controlled setting of a synthetic benchmark, achieving systematic generalization remains very difficult. After training on an augmented dataset with almost forty times more adverbs than the original problem, a non-modular baseline is not able to systematically generalize to a novel combination of a known verb and adverb. When separating the task into cognitive processes like perception and navigation, a modular neural network is able to utilize the augmented data and generalize more systematically, achieving 70% and 40% exact match increase over state-of-the-art on two gSCAN tests that have not previously been improved. We hope that this work gives insight into the drivers of systematic generalization, and what we still need to improve for neural networks to learn more like humans do.
CURI: A Benchmark for Productive Concept Learning Under Uncertainty
Oct 06, 2020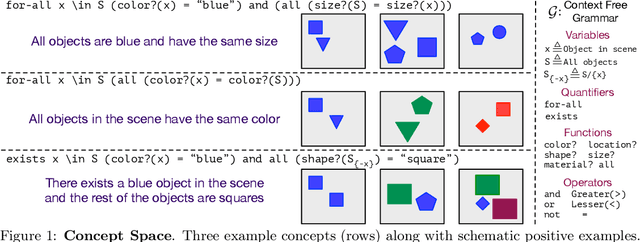
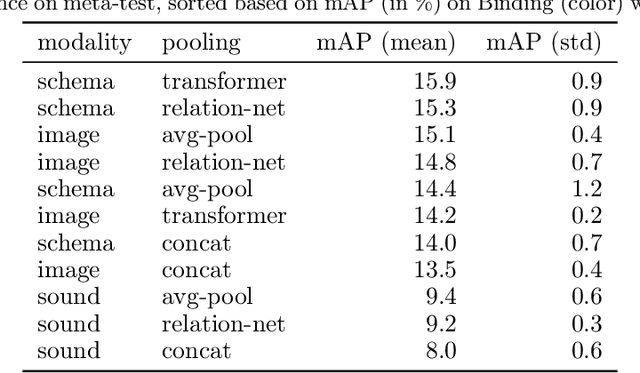
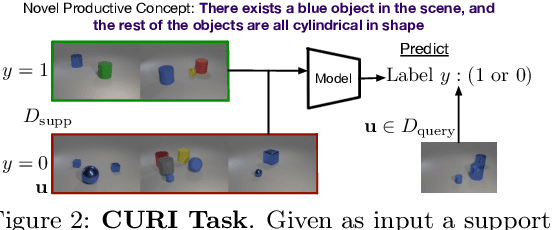
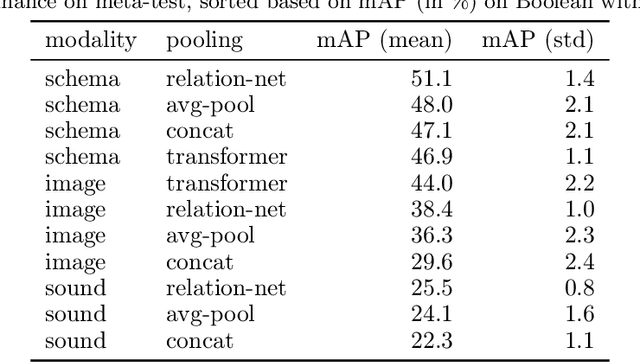
Humans can learn and reason under substantial uncertainty in a space of infinitely many concepts, including structured relational concepts ("a scene with objects that have the same color") and ad-hoc categories defined through goals ("objects that could fall on one's head"). In contrast, standard classification benchmarks: 1) consider only a fixed set of category labels, 2) do not evaluate compositional concept learning and 3) do not explicitly capture a notion of reasoning under uncertainty. We introduce a new few-shot, meta-learning benchmark, Compositional Reasoning Under Uncertainty (CURI) to bridge this gap. CURI evaluates different aspects of productive and systematic generalization, including abstract understandings of disentangling, productive generalization, learning boolean operations, variable binding, etc. Importantly, it also defines a model-independent "compositionality gap" to evaluate the difficulty of generalizing out-of-distribution along each of these axes. Extensive evaluations across a range of modeling choices spanning different modalities (image, schemas, and sounds), splits, privileged auxiliary concept information, and choices of negatives reveal substantial scope for modeling advances on the proposed task. All code and datasets will be available online.