 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmphasizing Discriminative Features for Dataset Distillation in Complex Scenarios
Oct 22, 2024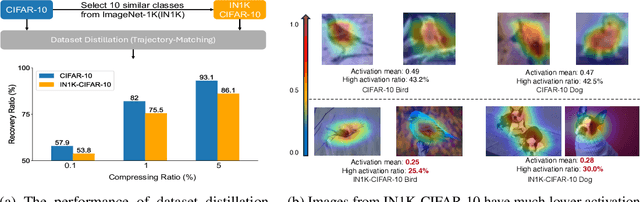
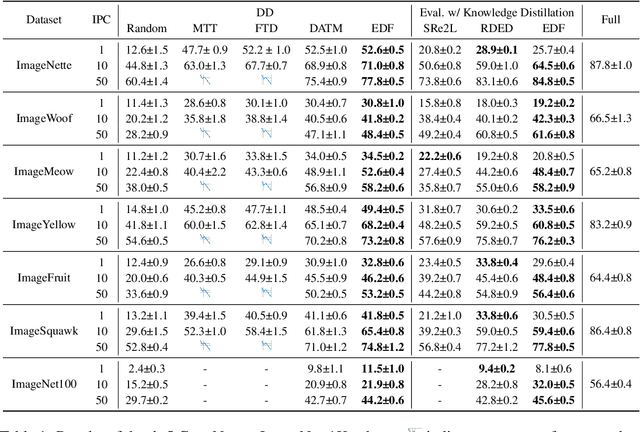
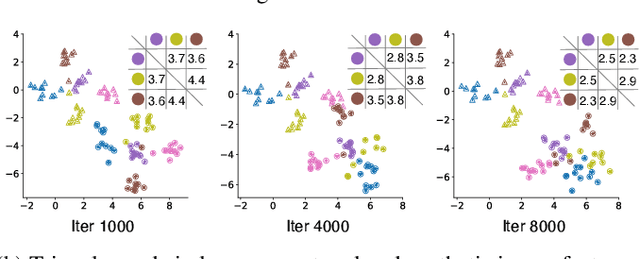

Dataset distillation has demonstrated strong performance on simple datasets like CIFAR, MNIST, and TinyImageNet but struggles to achieve similar results in more complex scenarios. In this paper, we propose EDF (emphasizes the discriminative features), a dataset distillation method that enhances key discriminative regions in synthetic images using Grad-CAM activation maps. Our approach is inspired by a key observation: in simple datasets, high-activation areas typically occupy most of the image, whereas in complex scenarios, the size of these areas is much smaller. Unlike previous methods that treat all pixels equally when synthesizing images, EDF uses Grad-CAM activation maps to enhance high-activation areas. From a supervision perspective, we downplay supervision signals that have lower losses, as they contain common patterns. Additionally, to help the DD community better explore complex scenarios, we build the Complex Dataset Distillation (Comp-DD) benchmark by meticulously selecting sixteen subsets, eight easy and eight hard, from ImageNet-1K. In particular, EDF consistently outperforms SOTA results in complex scenarios, such as ImageNet-1K subsets. Hopefully, more researchers will be inspired and encouraged to improve the practicality and efficacy of DD. Our code and benchmark will be made public at https://github.com/NUS-HPC-AI-Lab/EDF.
Embarassingly Simple Dataset Distillation
Nov 13, 2023



Dataset distillation extracts a small set of synthetic training samples from a large dataset with the goal of achieving competitive performance on test data when trained on this sample. In this work, we tackle dataset distillation at its core by treating it directly as a bilevel optimization problem. Re-examining the foundational back-propagation through time method, we study the pronounced variance in the gradients, computational burden, and long-term dependencies. We introduce an improved method: Random Truncated Backpropagation Through Time (RaT-BPTT) to address them. RaT-BPTT incorporates a truncation coupled with a random window, effectively stabilizing the gradients and speeding up the optimization while covering long dependencies. This allows us to establish new state-of-the-art for a variety of standard dataset benchmarks. A deeper dive into the nature of distilled data unveils pronounced intercorrelation. In particular, subsets of distilled datasets tend to exhibit much worse performance than directly distilled smaller datasets of the same size. Leveraging RaT-BPTT, we devise a boosting mechanism that generates distilled datasets that contain subsets with near optimal performance across different data budgets.
Improving Selective Visual Question Answering by Learning from Your Peers
Jun 14, 2023



Despite advances in Visual Question Answering (VQA), the ability of models to assess their own correctness remains underexplored. Recent work has shown that VQA models, out-of-the-box, can have difficulties abstaining from answering when they are wrong. The option to abstain, also called Selective Prediction, is highly relevant when deploying systems to users who must trust the system's output (e.g., VQA assistants for users with visual impairments). For such scenarios, abstention can be especially important as users may provide out-of-distribution (OOD) or adversarial inputs that make incorrect answers more likely. In this work, we explore Selective VQA in both in-distribution (ID) and OOD scenarios, where models are presented with mixtures of ID and OOD data. The goal is to maximize the number of questions answered while minimizing the risk of error on those questions. We propose a simple yet effective Learning from Your Peers (LYP) approach for training multimodal selection functions for making abstention decisions. Our approach uses predictions from models trained on distinct subsets of the training data as targets for optimizing a Selective VQA model. It does not require additional manual labels or held-out data and provides a signal for identifying examples that are easy/difficult to generalize to. In our extensive evaluations, we show this benefits a number of models across different architectures and scales. Overall, for ID, we reach 32.92% in the selective prediction metric coverage at 1% risk of error (C@1%) which doubles the previous best coverage of 15.79% on this task. For mixed ID/OOD, using models' softmax confidences for abstention decisions performs very poorly, answering <5% of questions at 1% risk of error even when faced with only 10% OOD examples, but a learned selection function with LYP can increase that to 25.38% C@1%.
Hyperbolic Image-Text Representations
Apr 18, 2023Visual and linguistic concepts naturally organize themselves in a hierarchy, where a textual concept ``dog'' entails all images that contain dogs. Despite being intuitive, current large-scale vision and language models such as CLIP do not explicitly capture such hierarchy. We propose MERU, a contrastive model that yields hyperbolic representations of images and text. Hyperbolic spaces have suitable geometric properties to embed tree-like data, so MERU can better capture the underlying hierarchy in image-text data. Our results show that MERU learns a highly interpretable representation space while being competitive with CLIP's performance on multi-modal tasks like image classification and image-text retrieval.
CURI: A Benchmark for Productive Concept Learning Under Uncertainty
Oct 06, 2020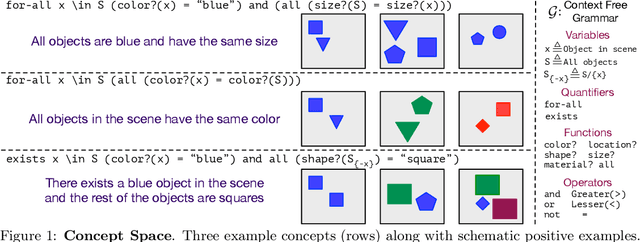
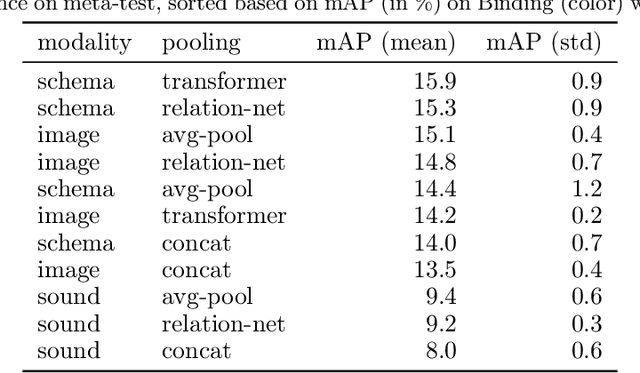
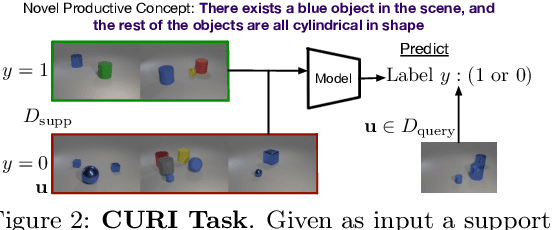
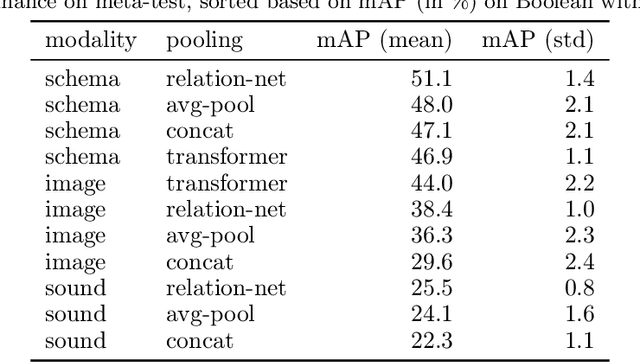
Humans can learn and reason under substantial uncertainty in a space of infinitely many concepts, including structured relational concepts ("a scene with objects that have the same color") and ad-hoc categories defined through goals ("objects that could fall on one's head"). In contrast, standard classification benchmarks: 1) consider only a fixed set of category labels, 2) do not evaluate compositional concept learning and 3) do not explicitly capture a notion of reasoning under uncertainty. We introduce a new few-shot, meta-learning benchmark, Compositional Reasoning Under Uncertainty (CURI) to bridge this gap. CURI evaluates different aspects of productive and systematic generalization, including abstract understandings of disentangling, productive generalization, learning boolean operations, variable binding, etc. Importantly, it also defines a model-independent "compositionality gap" to evaluate the difficulty of generalizing out-of-distribution along each of these axes. Extensive evaluations across a range of modeling choices spanning different modalities (image, schemas, and sounds), splits, privileged auxiliary concept information, and choices of negatives reveal substantial scope for modeling advances on the proposed task. All code and datasets will be available online.
Learning Optimal Representations with the Decodable Information Bottleneck
Sep 27, 2020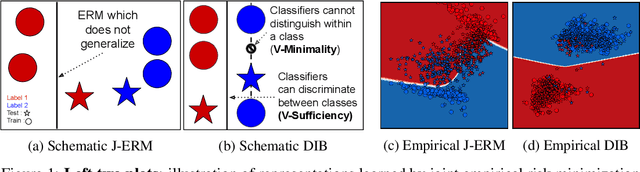
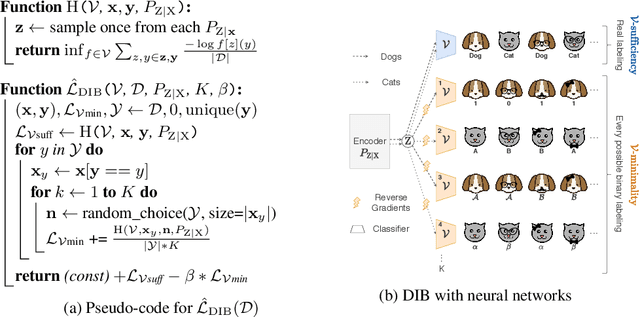

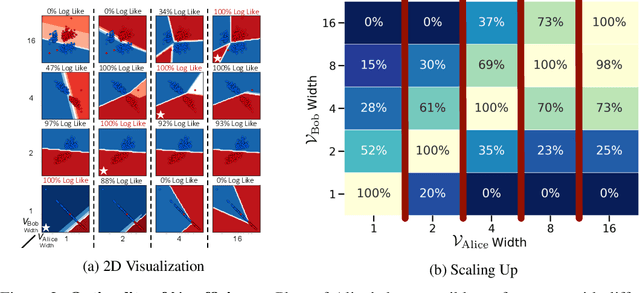
We address the question of characterizing and finding optimal representations for supervised learning. Traditionally, this question has been tackled using the Information Bottleneck, which compresses the inputs while retaining information about the targets, in a decoder-agnostic fashion. In machine learning, however, our goal is not compression but rather generalization, which is intimately linked to the predictive family or decoder of interest (e.g. linear classifier). We propose the Decodable Information Bottleneck (DIB) that considers information retention and compression from the perspective of the desired predictive family. As a result, DIB gives rise to representations that are optimal in terms of expected test performance and can be estimated with guarantees. Empirically, we show that the framework can be used to enforce a small generalization gap on downstream classifiers and to predict the generalization ability of neural networks.
Unsupervised Discovery of Decision States for Transfer in Reinforcement Learning
Aug 15, 2019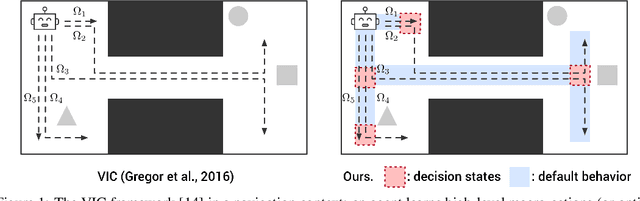
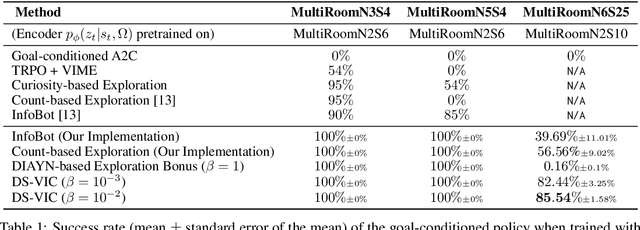
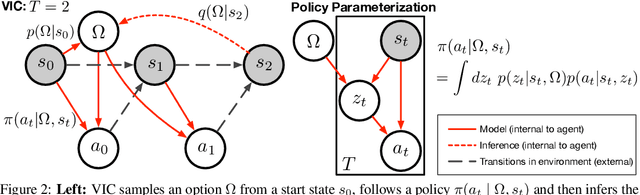
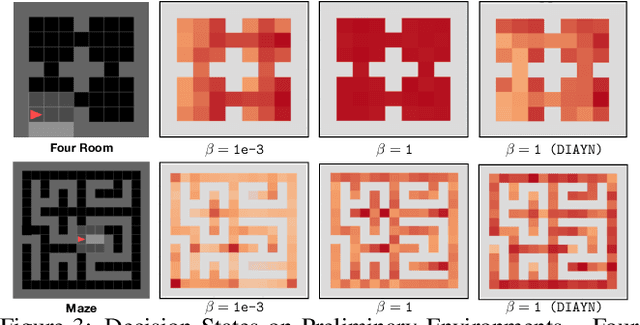
We present a hierarchical reinforcement learning (HRL) or options framework for identifying decision states. Informally speaking, these are states considered important by the agent's policy e.g. , for navigation, decision states would be crossroads or doors where an agent needs to make strategic decisions. While previous work (most notably Goyal et. al., 2019) discovers decision states in a task/goal specific (or 'supervised') manner, we do so in a goal-independent (or 'unsupervised') manner, i.e. entirely without any goal or extrinsic rewards. Our approach combines two hitherto disparate ideas - 1) \emph{intrinsic control} (Gregor et. al., 2016, Eysenbach et. al., 2018): learning a set of options that allow an agent to reliably reach a diverse set of states, and 2) \emph{information bottleneck} (Tishby et. al., 2000): penalizing mutual information between the option $\Omega$ and the states $s_t$ visited in the trajectory. The former encourages an agent to reliably explore the environment; the latter allows identification of decision states as the ones with high mutual information $I(\Omega; a_t | s_t)$ despite the bottleneck. Our results demonstrate that 1) our model learns interpretable decision states in an unsupervised manner, and 2) these learned decision states transfer to goal-driven tasks in new environments, effectively guide exploration, and improve performance.
Probabilistic Neural-symbolic Models for Interpretable Visual Question Answering
Feb 21, 2019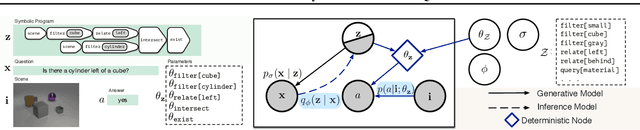
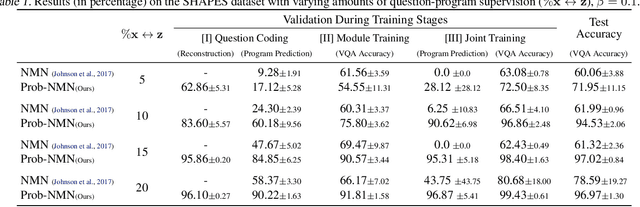
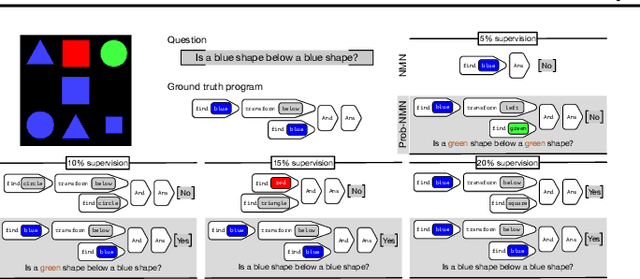

We propose a new class of probabilistic neural-symbolic models, that have symbolic functional programs as a latent, stochastic variable. Instantiated in the context of visual question answering, our probabilistic formulation offers two key conceptual advantages over prior neural-symbolic models for VQA. Firstly, the programs generated by our model are more understandable while requiring lesser number of teaching examples. Secondly, we show that one can pose counterfactual scenarios to the model, to probe its beliefs on the programs that could lead to a specified answer given an image. Our results on the CLEVR and SHAPES datasets verify our hypotheses, showing that the model gets better program (and answer) prediction accuracy even in the low data regime, and allows one to probe the coherence and consistency of reasoning performed.
Generative Models of Visually Grounded Imagination
Feb 25, 2018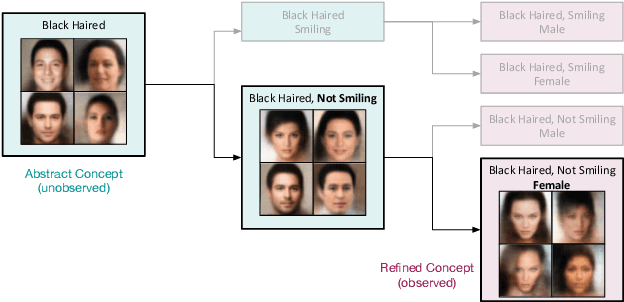
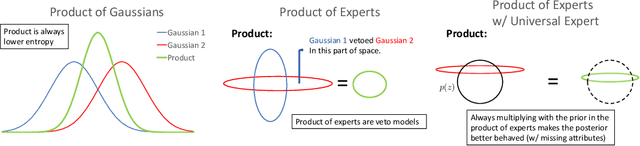
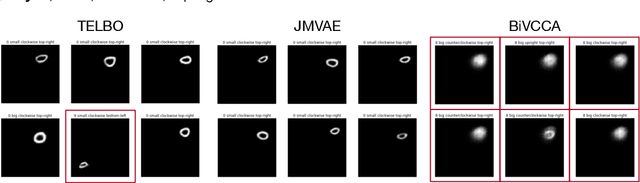
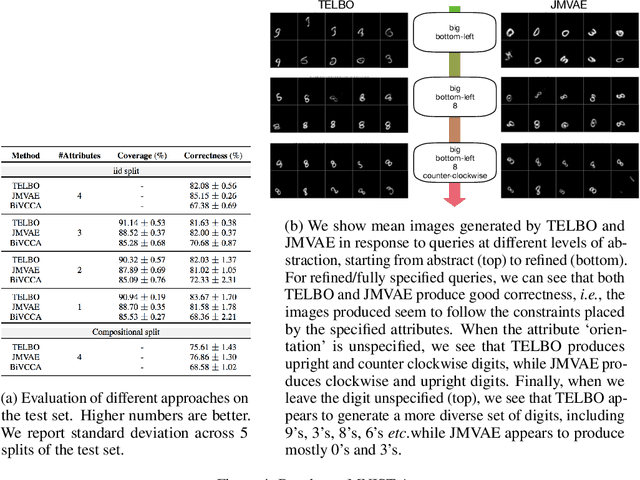
It is easy for people to imagine what a man with pink hair looks like, even if they have never seen such a person before. We call the ability to create images of novel semantic concepts visually grounded imagination. In this paper, we show how we can modify variational auto-encoders to perform this task. Our method uses a novel training objective, and a novel product-of-experts inference network, which can handle partially specified (abstract) concepts in a principled and efficient way. We also propose a set of easy-to-compute evaluation metrics that capture our intuitive notions of what it means to have good visual imagination, namely correctness, coverage, and compositionality (the 3 C's). Finally, we perform a detailed comparison of our method with two existing joint image-attribute VAE methods (the JMVAE method of Suzuki et.al. and the BiVCCA method of Wang et.al.) by applying them to two datasets: the MNIST-with-attributes dataset (which we introduce here), and the CelebA dataset.
Sound-Word2Vec: Learning Word Representations Grounded in Sounds
Aug 29, 2017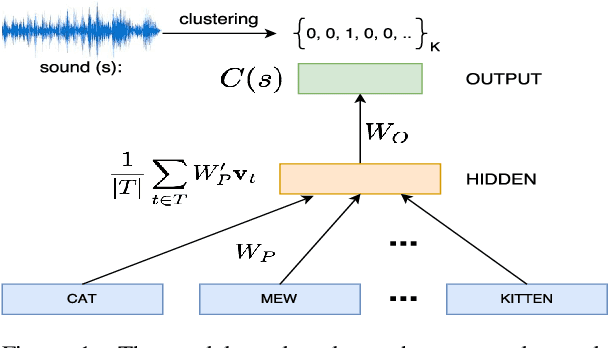

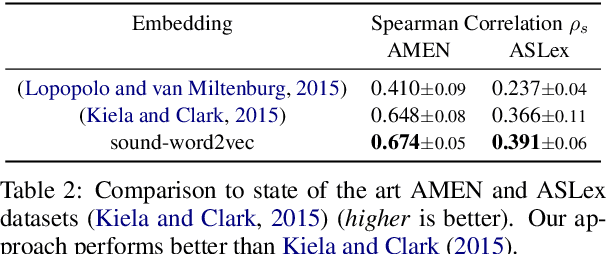
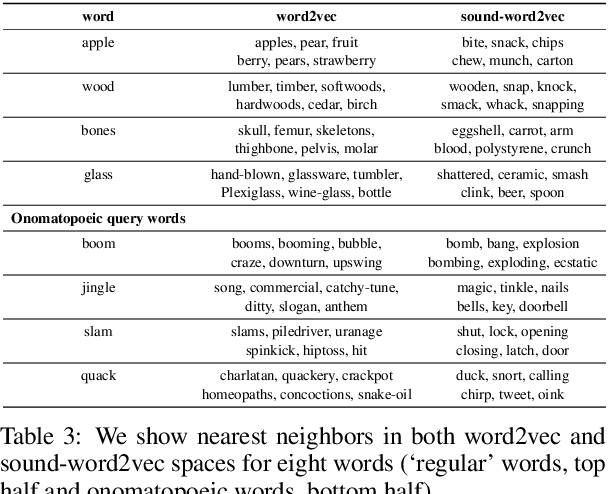
To be able to interact better with humans, it is crucial for machines to understand sound - a primary modality of human perception. Previous works have used sound to learn embeddings for improved generic textual similarity assessment. In this work, we treat sound as a first-class citizen, studying downstream textual tasks which require aural grounding. To this end, we propose sound-word2vec - a new embedding scheme that learns specialized word embeddings grounded in sounds. For example, we learn that two seemingly (semantically) unrelated concepts, like leaves and paper are similar due to the similar rustling sounds they make. Our embeddings prove useful in textual tasks requiring aural reasoning like text-based sound retrieval and discovering foley sound effects (used in movies). Moreover, our embedding space captures interesting dependencies between words and onomatopoeia and outperforms prior work on aurally-relevant word relatedness datasets such as AMEN and ASLex.