 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound-Word2Vec: Learning Word Representations Grounded in Sounds
Paper and Code
Aug 29, 2017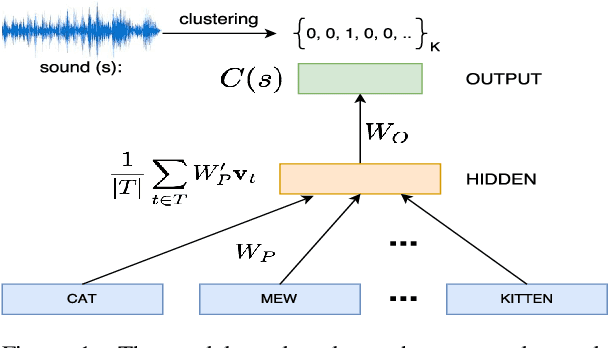

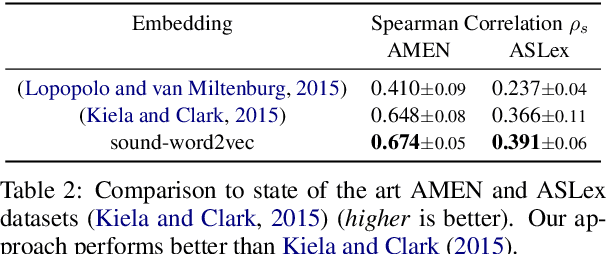
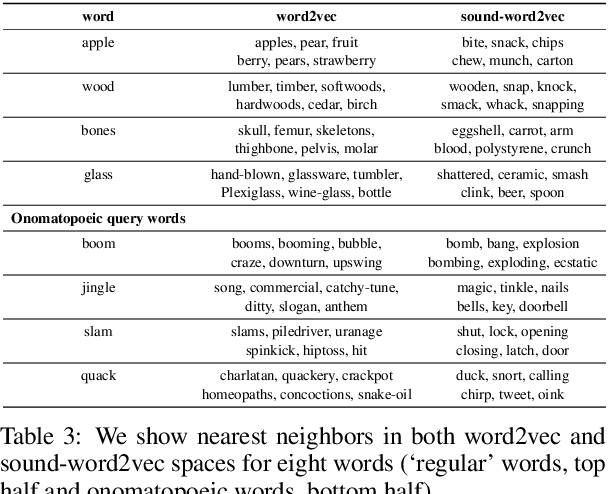
To be able to interact better with humans, it is crucial for machines to understand sound - a primary modality of human perception. Previous works have used sound to learn embeddings for improved generic textual similarity assessment. In this work, we treat sound as a first-class citizen, studying downstream textual tasks which require aural grounding. To this end, we propose sound-word2vec - a new embedding scheme that learns specialized word embeddings grounded in sounds. For example, we learn that two seemingly (semantically) unrelated concepts, like leaves and paper are similar due to the similar rustling sounds they make. Our embeddings prove useful in textual tasks requiring aural reasoning like text-based sound retrieval and discovering foley sound effects (used in movies). Moreover, our embedding space captures interesting dependencies between words and onomatopoeia and outperforms prior work on aurally-relevant word relatedness datasets such as AMEN and ASLex.