 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Generalization in Offline Reinforcement Learning via Unseen State Augmentations
Aug 07, 2023



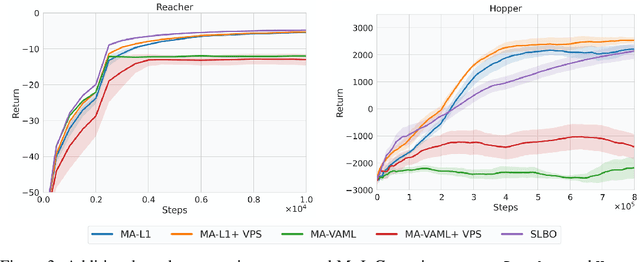
Offline reinforcement learning (RL) methods strike a balance between exploration and exploitation by conservative value estimation -- penalizing values of unseen states and actions. Model-free methods penalize values at all unseen actions, while model-based methods are able to further exploit unseen states via model rollouts. However, such methods are handicapped in their ability to find unseen states far away from the available offline data due to two factors -- (a) very short rollout horizons in models due to cascading model errors, and (b) model rollouts originating solely from states observed in offline data. We relax the second assumption and present a novel unseen state augmentation strategy to allow exploitation of unseen states where the learned model and value estimates generalize. Our strategy finds unseen states by value-informed perturbations of seen states followed by filtering out states with epistemic uncertainty estimates too high (high error) or too low (too similar to seen data). We observe improved performance in several offline RL tasks and find that our augmentation strategy consistently leads to overall lower average dataset Q-value estimates i.e. more conservative Q-value estimates than a baseline.
Model-Advantage Optimization for Model-Based Reinforcement Learning
Jun 26, 2021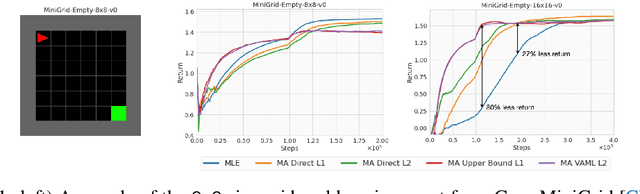


Model-based Reinforcement Learning (MBRL) algorithms have been traditionally designed with the goal of learning accurate dynamics of the environment. This introduces a mismatch between the objectives of model-learning and the overall learning problem of finding an optimal policy. Value-aware model learning, an alternative model-learning paradigm to maximum likelihood, proposes to inform model-learning through the value function of the learnt policy. While this paradigm is theoretically sound, it does not scale beyond toy settings. In this work, we propose a novel value-aware objective that is an upper bound on the absolute performance difference of a policy across two models. Further, we propose a general purpose algorithm that modifies the standard MBRL pipeline -- enabling learning with value aware objectives. Our proposed objective, in conjunction with this algorithm, is the first successful instantiation of value-aware MBRL on challenging continuous control environments, outperforming previous value-aware objectives and with competitive performance w.r.t. MLE-based MBRL approaches.
Unsupervised Discovery of Decision States for Transfer in Reinforcement Learning
Aug 15, 2019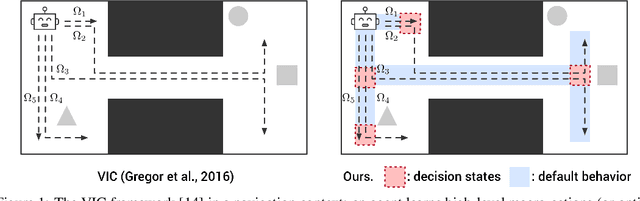
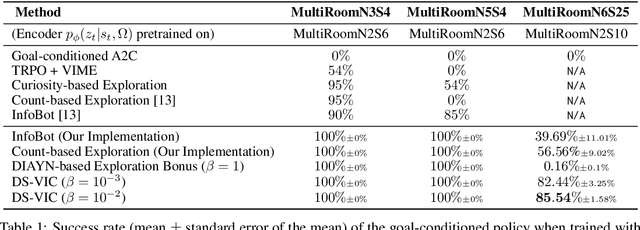
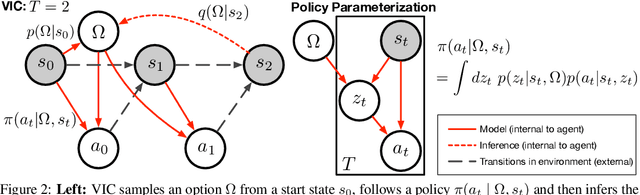
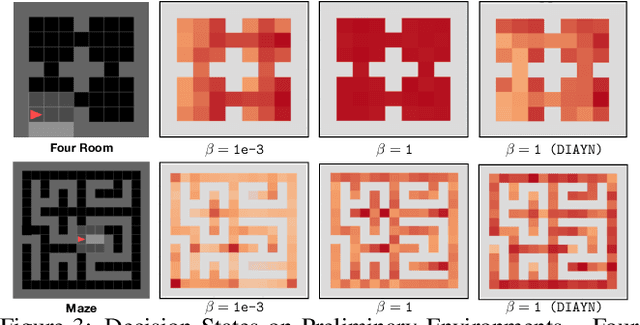
We present a hierarchical reinforcement learning (HRL) or options framework for identifying decision states. Informally speaking, these are states considered important by the agent's policy e.g. , for navigation, decision states would be crossroads or doors where an agent needs to make strategic decisions. While previous work (most notably Goyal et. al., 2019) discovers decision states in a task/goal specific (or 'supervised') manner, we do so in a goal-independent (or 'unsupervised') manner, i.e. entirely without any goal or extrinsic rewards. Our approach combines two hitherto disparate ideas - 1) \emph{intrinsic control} (Gregor et. al., 2016, Eysenbach et. al., 2018): learning a set of options that allow an agent to reliably reach a diverse set of states, and 2) \emph{information bottleneck} (Tishby et. al., 2000): penalizing mutual information between the option $\Omega$ and the states $s_t$ visited in the trajectory. The former encourages an agent to reliably explore the environment; the latter allows identification of decision states as the ones with high mutual information $I(\Omega; a_t | s_t)$ despite the bottleneck. Our results demonstrate that 1) our model learns interpretable decision states in an unsupervised manner, and 2) these learned decision states transfer to goal-driven tasks in new environments, effectively guide exploration, and improve performance.