 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHM3D-OVON: A Dataset and Benchmark for Open-Vocabulary Object Goal Navigation
Sep 22, 2024



We present the Habitat-Matterport 3D Open Vocabulary Object Goal Navigation dataset (HM3D-OVON), a large-scale benchmark that broadens the scope and semantic range of prior Object Goal Navigation (ObjectNav) benchmarks. Leveraging the HM3DSem dataset, HM3D-OVON incorporates over 15k annotated instances of household objects across 379 distinct categories, derived from photo-realistic 3D scans of real-world environments. In contrast to earlier ObjectNav datasets, which limit goal objects to a predefined set of 6-20 categories, HM3D-OVON facilitates the training and evaluation of models with an open-set of goals defined through free-form language at test-time. Through this open-vocabulary formulation, HM3D-OVON encourages progress towards learning visuo-semantic navigation behaviors that are capable of searching for any object specified by text in an open-vocabulary manner. Additionally, we systematically evaluate and compare several different types of approaches on HM3D-OVON. We find that HM3D-OVON can be used to train an open-vocabulary ObjectNav agent that achieves both higher performance and is more robust to localization and actuation noise than the state-of-the-art ObjectNav approach. We hope that our benchmark and baseline results will drive interest in developing embodied agents that can navigate real-world spaces to find household objects specified through free-form language, taking a step towards more flexible and human-like semantic visual navigation. Code and videos available at: naoki.io/ovon.
Distribution Learning for Molecular Regression
Jul 30, 2024



Using "soft" targets to improve model performance has been shown to be effective in classification settings, but the usage of soft targets for regression is a much less studied topic in machine learning. The existing literature on the usage of soft targets for regression fails to properly assess the method's limitations, and empirical evaluation is quite limited. In this work, we assess the strengths and drawbacks of existing methods when applied to molecular property regression tasks. Our assessment outlines key biases present in existing methods and proposes methods to address them, evaluated through careful ablation studies. We leverage these insights to propose Distributional Mixture of Experts (DMoE): A model-independent, and data-independent method for regression which trains a model to predict probability distributions of its targets. Our proposed loss function combines the cross entropy between predicted and target distributions and the L1 distance between their expected values to produce a loss function that is robust to the outlined biases. We evaluate the performance of DMoE on different molecular property prediction datasets -- Open Catalyst (OC20), MD17, and QM9 -- across different backbone model architectures -- SchNet, GemNet, and Graphormer. Our results demonstrate that the proposed method is a promising alternative to classical regression for molecular property prediction tasks, showing improvements over baselines on all datasets and architectures.
Generalizing Denoising to Non-Equilibrium Structures Improves Equivariant Force Fields
Mar 14, 2024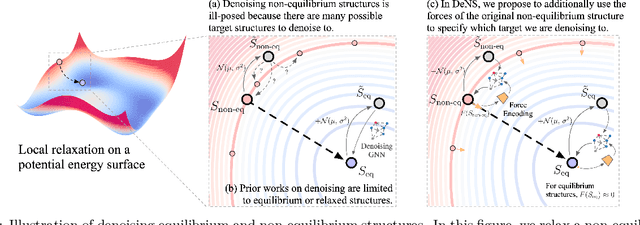
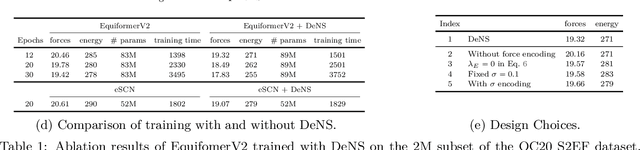
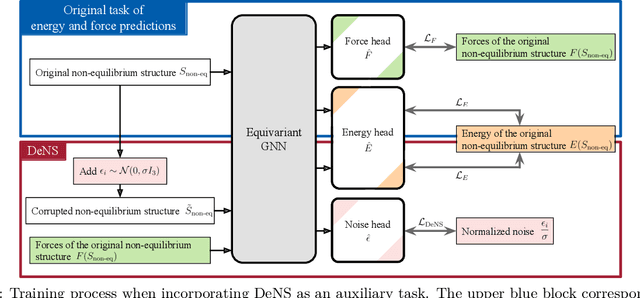
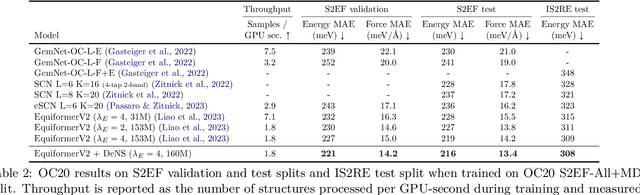
Understanding the interactions of atoms such as forces in 3D atomistic systems is fundamental to many applications like molecular dynamics and catalyst design. However, simulating these interactions requires compute-intensive ab initio calculations and thus results in limited data for training neural networks. In this paper, we propose to use denoising non-equilibrium structures (DeNS) as an auxiliary task to better leverage training data and improve performance. For training with DeNS, we first corrupt a 3D structure by adding noise to its 3D coordinates and then predict the noise. Different from previous works on denoising, which are limited to equilibrium structures, the proposed method generalizes denoising to a much larger set of non-equilibrium structures. The main difference is that a non-equilibrium structure does not correspond to local energy minima and has non-zero forces, and therefore it can have many possible atomic positions compared to an equilibrium structure. This makes denoising non-equilibrium structures an ill-posed problem since the target of denoising is not uniquely defined. Our key insight is to additionally encode the forces of the original non-equilibrium structure to specify which non-equilibrium structure we are denoising. Concretely, given a corrupted non-equilibrium structure and the forces of the original one, we predict the non-equilibrium structure satisfying the input forces instead of any arbitrary structures. Since DeNS requires encoding forces, DeNS favors equivariant networks, which can easily incorporate forces and other higher-order tensors in node embeddings. We study the effectiveness of training equivariant networks with DeNS on OC20, OC22 and MD17 datasets and demonstrate that DeNS can achieve new state-of-the-art results on OC20 and OC22 and significantly improve training efficiency on MD17.
The Open DAC 2023 Dataset and Challenges for Sorbent Discovery in Direct Air Capture
Nov 01, 2023
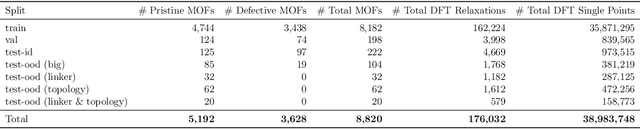
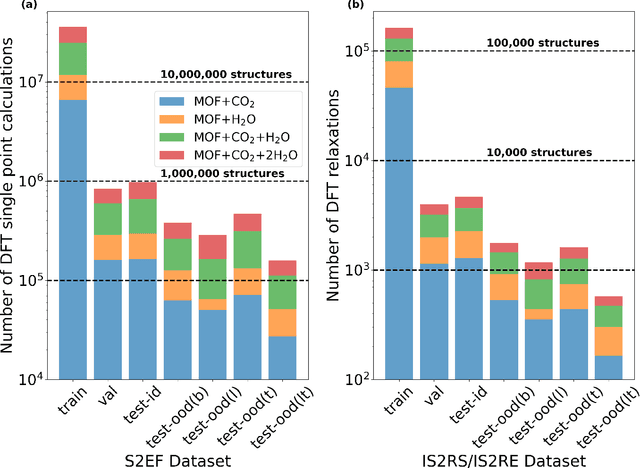

New methods for carbon dioxide removal are urgently needed to combat global climate change. Direct air capture (DAC) is an emerging technology to capture carbon dioxide directly from ambient air. Metal-organic frameworks (MOFs) have been widely studied as potentially customizable adsorbents for DAC. However, discovering promising MOF sorbents for DAC is challenging because of the vast chemical space to explore and the need to understand materials as functions of humidity and temperature. We explore a computational approach benefiting from recent innovations in machine learning (ML) and present a dataset named Open DAC 2023 (ODAC23) consisting of more than 38M density functional theory (DFT) calculations on more than 8,800 MOF materials containing adsorbed CO2 and/or H2O. ODAC23 is by far the largest dataset of MOF adsorption calculations at the DFT level of accuracy currently available. In addition to probing properties of adsorbed molecules, the dataset is a rich source of information on structural relaxation of MOFs, which will be useful in many contexts beyond specific applications for DAC. A large number of MOFs with promising properties for DAC are identified directly in ODAC23. We also trained state-of-the-art ML models on this dataset to approximate calculations at the DFT level. This open-source dataset and our initial ML models will provide an important baseline for future efforts to identify MOFs for a wide range of applications, including DAC.
EquiformerV2: Improved Equivariant Transformer for Scaling to Higher-Degree Representations
Jun 21, 2023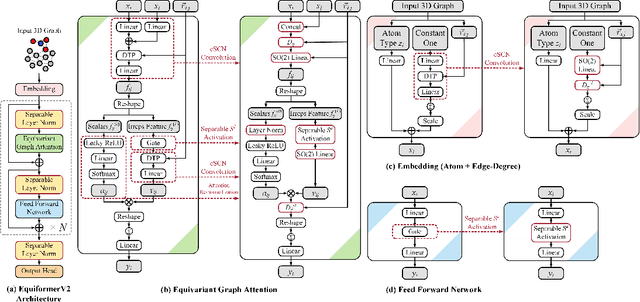
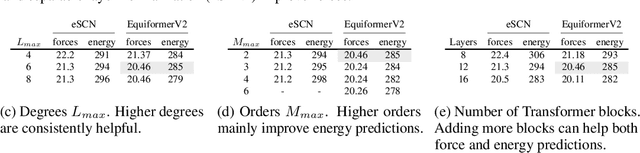
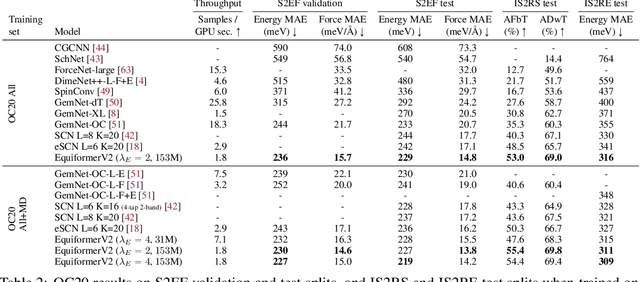
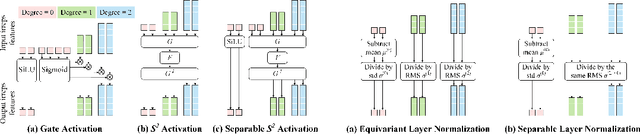
Equivariant Transformers such as Equiformer have demonstrated the efficacy of applying Transformers to the domain of 3D atomistic systems. However, they are still limited to small degrees of equivariant representations due to their computational complexity. In this paper, we investigate whether these architectures can scale well to higher degrees. Starting from Equiformer, we first replace $SO(3)$ convolutions with eSCN convolutions to efficiently incorporate higher-degree tensors. Then, to better leverage the power of higher degrees, we propose three architectural improvements -- attention re-normalization, separable $S^2$ activation and separable layer normalization. Putting this all together, we propose EquiformerV2, which outperforms previous state-of-the-art methods on the large-scale OC20 dataset by up to $12\%$ on forces, $4\%$ on energies, offers better speed-accuracy trade-offs, and $2\times$ reduction in DFT calculations needed for computing adsorption energies.
PIRLNav: Pretraining with Imitation and RL Finetuning for ObjectNav
Jan 18, 2023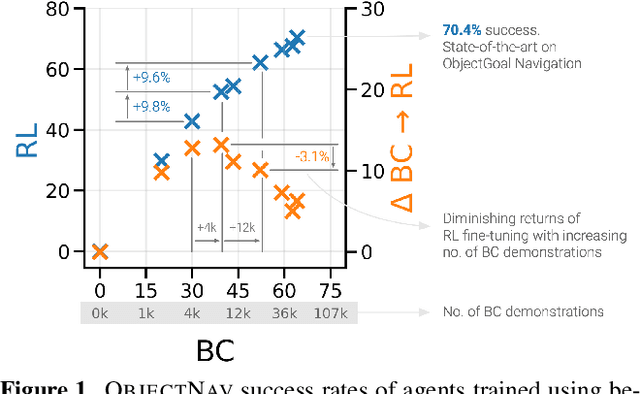

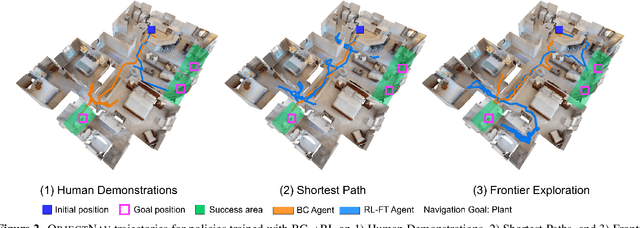
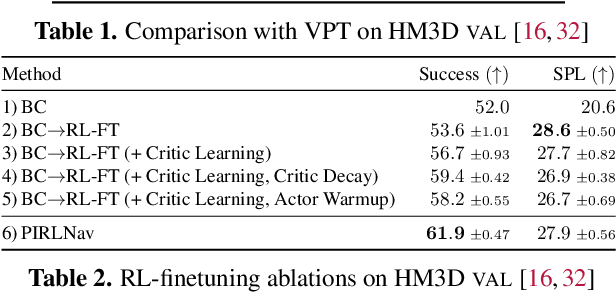
We study ObjectGoal Navigation - where a virtual robot situated in a new environment is asked to navigate to an object. Prior work has shown that imitation learning (IL) on a dataset of human demonstrations achieves promising results. However, this has limitations $-$ 1) IL policies generalize poorly to new states, since the training mimics actions not their consequences, and 2) collecting demonstrations is expensive. On the other hand, reinforcement learning (RL) is trivially scalable, but requires careful reward engineering to achieve desirable behavior. We present a two-stage learning scheme for IL pretraining on human demonstrations followed by RL-finetuning. This leads to a PIRLNav policy that advances the state-of-the-art on ObjectNav from $60.0\%$ success rate to $65.0\%$ ($+5.0\%$ absolute). Using this IL$\rightarrow$RL training recipe, we present a rigorous empirical analysis of design choices. First, we investigate whether human demonstrations can be replaced with `free' (automatically generated) sources of demonstrations, e.g. shortest paths (SP) or task-agnostic frontier exploration (FE) trajectories. We find that IL$\rightarrow$RL on human demonstrations outperforms IL$\rightarrow$RL on SP and FE trajectories, even when controlled for the same IL-pretraining success on TRAIN, and even on a subset of VAL episodes where IL-pretraining success favors the SP or FE policies. Next, we study how RL-finetuning performance scales with the size of the IL pretraining dataset. We find that as we increase the size of the IL-pretraining dataset and get to high IL accuracies, the improvements from RL-finetuning are smaller, and that $90\%$ of the performance of our best IL$\rightarrow$RL policy can be achieved with less than half the number of IL demonstrations. Finally, we analyze failure modes of our ObjectNav policies, and present guidelines for further improving them.
AdsorbML: Accelerating Adsorption Energy Calculations with Machine Learning
Nov 29, 2022Computational catalysis is playing an increasingly significant role in the design of catalysts across a wide range of applications. A common task for many computational methods is the need to accurately compute the minimum binding energy - the adsorption energy - for an adsorbate and a catalyst surface of interest. Traditionally, the identification of low energy adsorbate-surface configurations relies on heuristic methods and researcher intuition. As the desire to perform high-throughput screening increases, it becomes challenging to use heuristics and intuition alone. In this paper, we demonstrate machine learning potentials can be leveraged to identify low energy adsorbate-surface configurations more accurately and efficiently. Our algorithm provides a spectrum of trade-offs between accuracy and efficiency, with one balanced option finding the lowest energy configuration, within a 0.1 eV threshold, 86.63% of the time, while achieving a 1387x speedup in computation. To standardize benchmarking, we introduce the Open Catalyst Dense dataset containing nearly 1,000 diverse surfaces and 87,045 unique configurations.
Spherical Channels for Modeling Atomic Interactions
Jun 29, 2022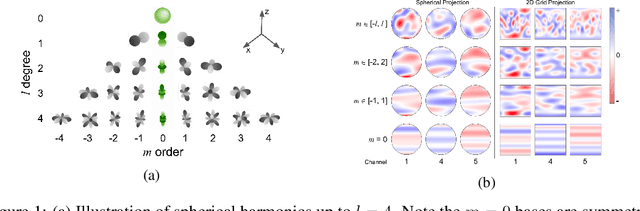
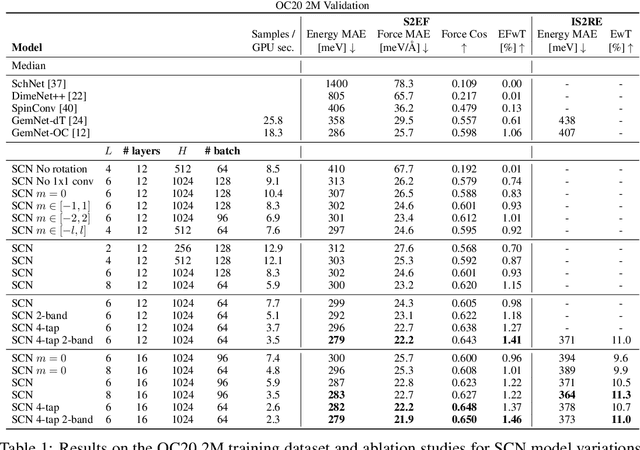
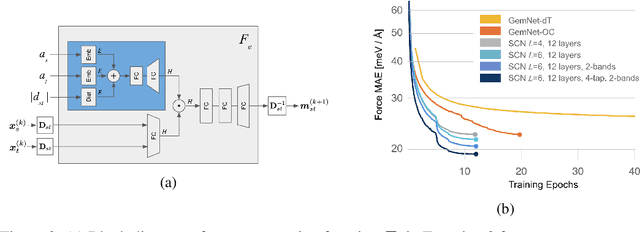
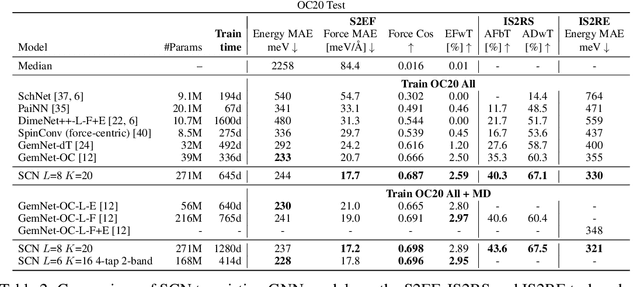
Modeling the energy and forces of atomic systems is a fundamental problem in computational chemistry with the potential to help address many of the world's most pressing problems, including those related to energy scarcity and climate change. These calculations are traditionally performed using Density Functional Theory, which is computationally very expensive. Machine learning has the potential to dramatically improve the efficiency of these calculations from days or hours to seconds. We propose the Spherical Channel Network (SCN) to model atomic energies and forces. The SCN is a graph neural network where nodes represent atoms and edges their neighboring atoms. The atom embeddings are a set of spherical functions, called spherical channels, represented using spherical harmonics. We demonstrate, that by rotating the embeddings based on the 3D edge orientation, more information may be utilized while maintaining the rotational equivariance of the messages. While equivariance is a desirable property, we find that by relaxing this constraint in both message passing and aggregation, improved accuracy may be achieved. We demonstrate state-of-the-art results on the large-scale Open Catalyst 2020 dataset in both energy and force prediction for numerous tasks and metrics.
The Open Catalyst 2022 Dataset and Challenges for Oxide Electrocatalysis
Jun 17, 2022
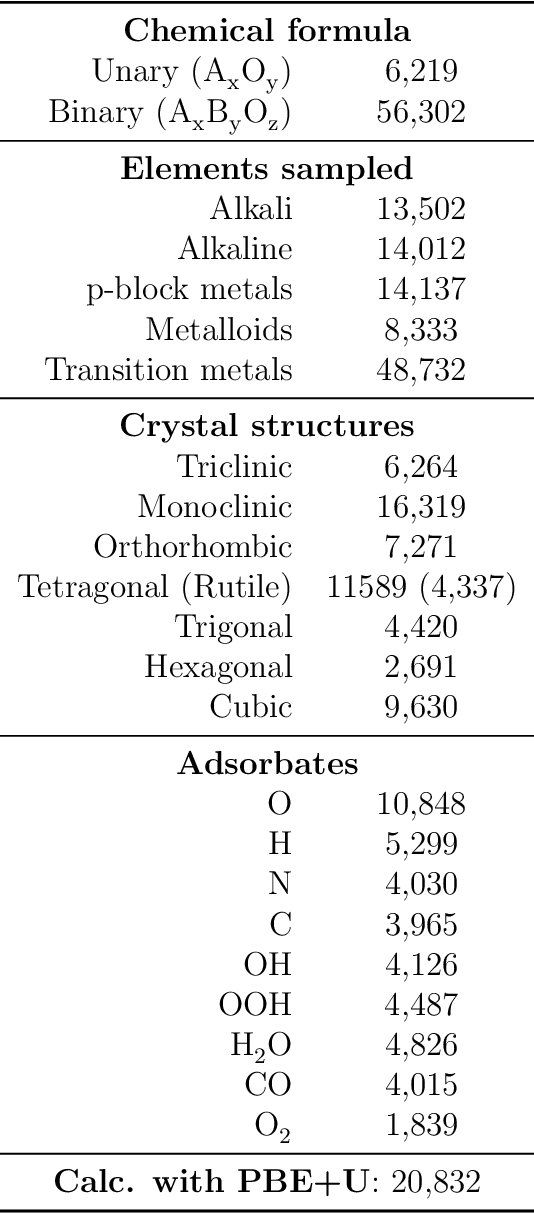
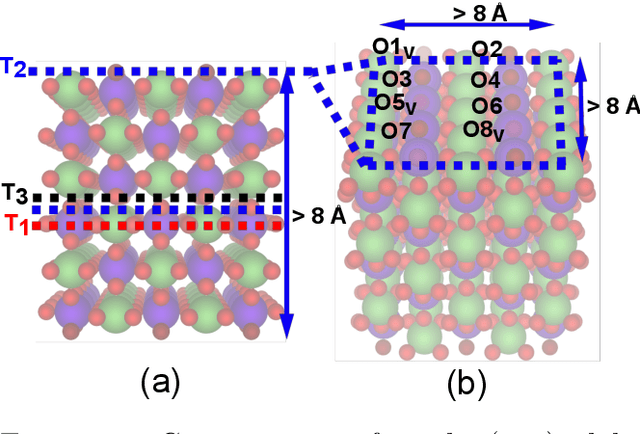

Computational catalysis and machine learning communities have made considerable progress in developing machine learning models for catalyst discovery and design. Yet, a general machine learning potential that spans the chemical space of catalysis is still out of reach. A significant hurdle is obtaining access to training data across a wide range of materials. One important class of materials where data is lacking are oxides, which inhibits models from studying the Oxygen Evolution Reaction and oxide electrocatalysis more generally. To address this we developed the Open Catalyst 2022(OC22) dataset, consisting of 62,521 Density Functional Theory (DFT) relaxations (~9,884,504 single point calculations) across a range of oxide materials, coverages, and adsorbates (*H, *O, *N, *C, *OOH, *OH, *OH2, *O2, *CO). We define generalized tasks to predict the total system energy that are applicable across catalysis, develop baseline performance of several graph neural networks (SchNet, DimeNet++, ForceNet, SpinConv, PaiNN, GemNet-dT, GemNet-OC), and provide pre-defined dataset splits to establish clear benchmarks for future efforts. For all tasks, we study whether combining datasets leads to better results, even if they contain different materials or adsorbates. Specifically, we jointly train models on Open Catalyst 2020 (OC20) Dataset and OC22, or fine-tune pretrained OC20 models on OC22. In the most general task, GemNet-OC sees a ~32% improvement in energy predictions through fine-tuning and a ~9% improvement in force predictions via joint training. Surprisingly, joint training on both the OC20 and much smaller OC22 datasets also improves total energy predictions on OC20 by ~19%. The dataset and baseline models are open sourced, and a public leaderboard will follow to encourage continued community developments on the total energy tasks and data.
Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale
Apr 08, 2022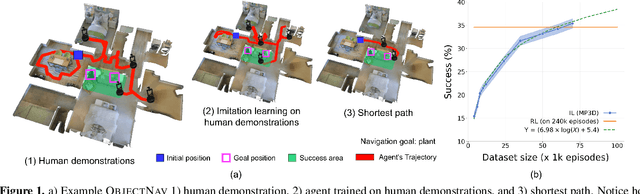

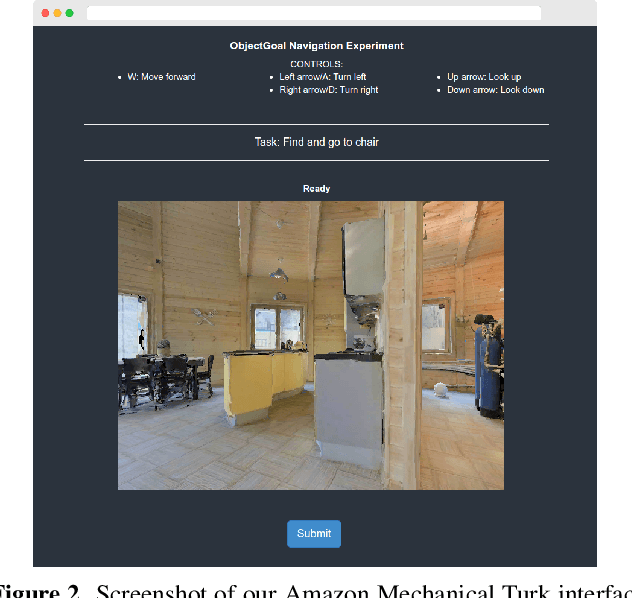
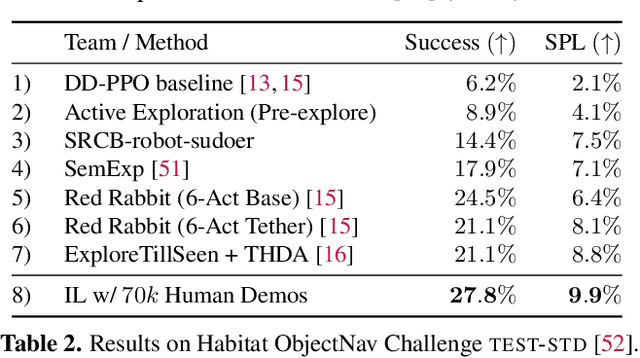
We present a large-scale study of imitating human demonstrations on tasks that require a virtual robot to search for objects in new environments -- (1) ObjectGoal Navigation (e.g. 'find & go to a chair') and (2) Pick&Place (e.g. 'find mug, pick mug, find counter, place mug on counter'). First, we develop a virtual teleoperation data-collection infrastructure -- connecting Habitat simulator running in a web browser to Amazon Mechanical Turk, allowing remote users to teleoperate virtual robots, safely and at scale. We collect 80k demonstrations for ObjectNav and 12k demonstrations for Pick&Place, which is an order of magnitude larger than existing human demonstration datasets in simulation or on real robots. Second, we attempt to answer the question -- how does large-scale imitation learning (IL) (which hasn't been hitherto possible) compare to reinforcement learning (RL) (which is the status quo)? On ObjectNav, we find that IL (with no bells or whistles) using 70k human demonstrations outperforms RL using 240k agent-gathered trajectories. The IL-trained agent demonstrates efficient object-search behavior -- it peeks into rooms, checks corners for small objects, turns in place to get a panoramic view -- none of these are exhibited as prominently by the RL agent, and to induce these behaviors via RL would require tedious reward engineering. Finally, accuracy vs. training data size plots show promising scaling behavior, suggesting that simply collecting more demonstrations is likely to advance the state of art further. On Pick&Place, the comparison is starker -- IL agents achieve ${\sim}$18% success on episodes with new object-receptacle locations when trained with 9.5k human demonstrations, while RL agents fail to get beyond 0%. Overall, our work provides compelling evidence for investing in large-scale imitation learning. Project page: https://ram81.github.io/projects/habitat-web.