 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHM3D-OVON: A Dataset and Benchmark for Open-Vocabulary Object Goal Navigation
Sep 22, 2024



We present the Habitat-Matterport 3D Open Vocabulary Object Goal Navigation dataset (HM3D-OVON), a large-scale benchmark that broadens the scope and semantic range of prior Object Goal Navigation (ObjectNav) benchmarks. Leveraging the HM3DSem dataset, HM3D-OVON incorporates over 15k annotated instances of household objects across 379 distinct categories, derived from photo-realistic 3D scans of real-world environments. In contrast to earlier ObjectNav datasets, which limit goal objects to a predefined set of 6-20 categories, HM3D-OVON facilitates the training and evaluation of models with an open-set of goals defined through free-form language at test-time. Through this open-vocabulary formulation, HM3D-OVON encourages progress towards learning visuo-semantic navigation behaviors that are capable of searching for any object specified by text in an open-vocabulary manner. Additionally, we systematically evaluate and compare several different types of approaches on HM3D-OVON. We find that HM3D-OVON can be used to train an open-vocabulary ObjectNav agent that achieves both higher performance and is more robust to localization and actuation noise than the state-of-the-art ObjectNav approach. We hope that our benchmark and baseline results will drive interest in developing embodied agents that can navigate real-world spaces to find household objects specified through free-form language, taking a step towards more flexible and human-like semantic visual navigation. Code and videos available at: naoki.io/ovon.
VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation
Dec 06, 2023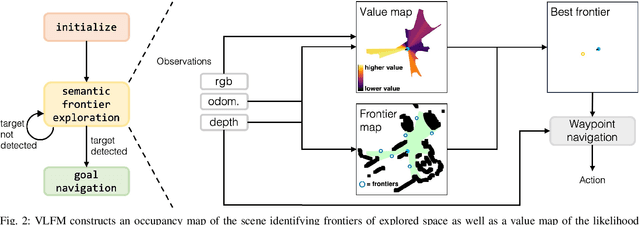
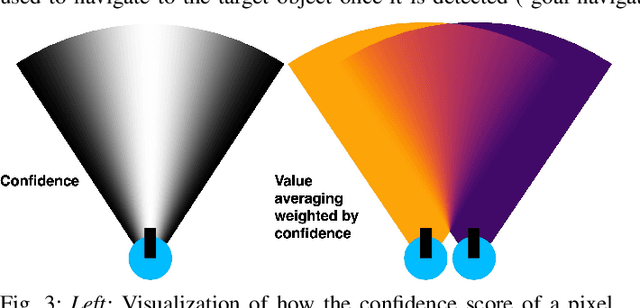
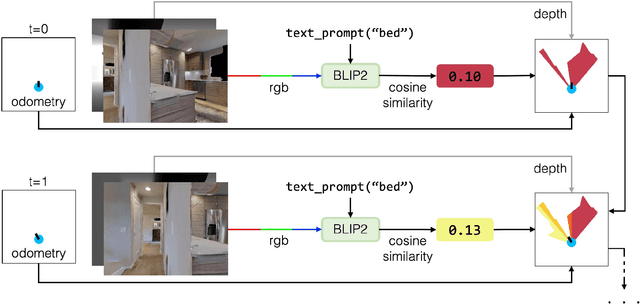
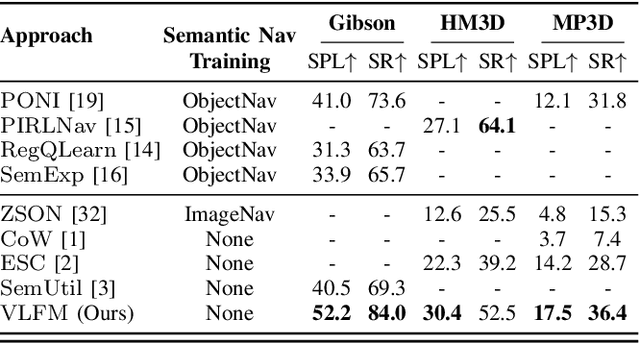
Understanding how humans leverage semantic knowledge to navigate unfamiliar environments and decide where to explore next is pivotal for developing robots capable of human-like search behaviors. We introduce a zero-shot navigation approach, Vision-Language Frontier Maps (VLFM), which is inspired by human reasoning and designed to navigate towards unseen semantic objects in novel environments. VLFM builds occupancy maps from depth observations to identify frontiers, and leverages RGB observations and a pre-trained vision-language model to generate a language-grounded value map. VLFM then uses this map to identify the most promising frontier to explore for finding an instance of a given target object category. We evaluate VLFM in photo-realistic environments from the Gibson, Habitat-Matterport 3D (HM3D), and Matterport 3D (MP3D) datasets within the Habitat simulator. Remarkably, VLFM achieves state-of-the-art results on all three datasets as measured by success weighted by path length (SPL) for the Object Goal Navigation task. Furthermore, we show that VLFM's zero-shot nature enables it to be readily deployed on real-world robots such as the Boston Dynamics Spot mobile manipulation platform. We deploy VLFM on Spot and demonstrate its capability to efficiently navigate to target objects within an office building in the real world, without any prior knowledge of the environment. The accomplishments of VLFM underscore the promising potential of vision-language models in advancing the field of semantic navigation. Videos of real-world deployment can be viewed at naoki.io/vlfm.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Adaptive Skill Coordination for Robotic Mobile Manipulation
Apr 01, 2023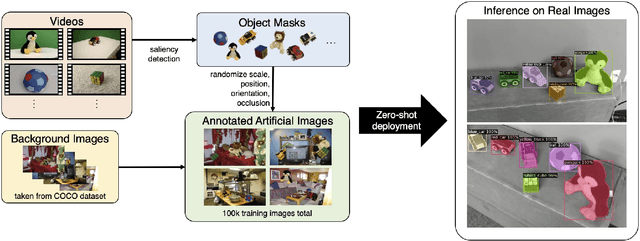
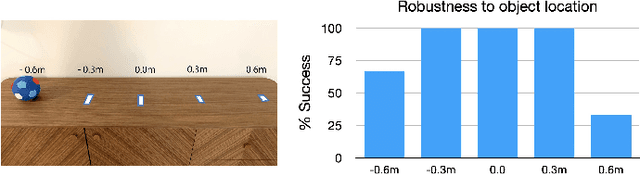
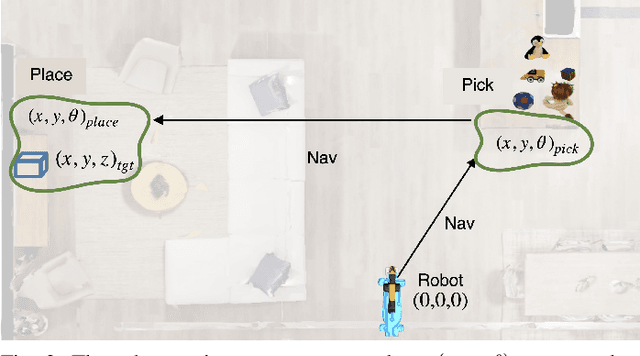

We present Adaptive Skill Coordination (ASC) - an approach for accomplishing long-horizon tasks (e.g., mobile pick-and-place, consisting of navigating to an object, picking it, navigating to another location, placing it, repeating). ASC consists of three components - (1) a library of basic visuomotor skills (navigation, pick, place), (2) a skill coordination policy that chooses which skills are appropriate to use when, and (3) a corrective policy that adapts pre-trained skills when out-of-distribution states are perceived. All components of ASC rely only on onboard visual and proprioceptive sensing, without access to privileged information like pre-built maps or precise object locations, easing real-world deployment. We train ASC in simulated indoor environments, and deploy it zero-shot in two novel real-world environments on the Boston Dynamics Spot robot. ASC achieves near-perfect performance at mobile pick-and-place, succeeding in 59/60 (98%) episodes, while sequentially executing skills succeeds in only 44/60 (73%) episodes. It is robust to hand-off errors, changes in the environment layout, dynamic obstacles (e.g., people), and unexpected disturbances, making it an ideal framework for complex, long-horizon tasks. Supplementary videos available at adaptiveskillcoordination.github.io.
OVRL-V2: A simple state-of-art baseline for ImageNav and ObjectNav
Mar 14, 2023We present a single neural network architecture composed of task-agnostic components (ViTs, convolutions, and LSTMs) that achieves state-of-art results on both the ImageNav ("go to location in <this picture>") and ObjectNav ("find a chair") tasks without any task-specific modules like object detection, segmentation, mapping, or planning modules. Such general-purpose methods offer advantages of simplicity in design, positive scaling with available compute, and versatile applicability to multiple tasks. Our work builds upon the recent success of self-supervised learning (SSL) for pre-training vision transformers (ViT). However, while the training recipes for convolutional networks are mature and robust, the recipes for ViTs are contingent and brittle, and in the case of ViTs for visual navigation, yet to be fully discovered. Specifically, we find that vanilla ViTs do not outperform ResNets on visual navigation. We propose the use of a compression layer operating over ViT patch representations to preserve spatial information along with policy training improvements. These improvements allow us to demonstrate positive scaling laws for the first time in visual navigation tasks. Consequently, our model advances state-of-the-art performance on ImageNav from 54.2% to 82.0% success and performs competitively against concurrent state-of-art on ObjectNav with success rate of 64.0% vs. 65.0%. Overall, this work does not present a fundamentally new approach, but rather recommendations for training a general-purpose architecture that achieves state-of-art performance today and could serve as a strong baseline for future methods.
ViNL: Visual Navigation and Locomotion Over Obstacles
Oct 26, 2022We present Visual Navigation and Locomotion over obstacles (ViNL), which enables a quadrupedal robot to navigate unseen apartments while stepping over small obstacles that lie in its path (e.g., shoes, toys, cables), similar to how humans and pets lift their feet over objects as they walk. ViNL consists of: (1) a visual navigation policy that outputs linear and angular velocity commands that guides the robot to a goal coordinate in unfamiliar indoor environments; and (2) a visual locomotion policy that controls the robot's joints to avoid stepping on obstacles while following provided velocity commands. Both the policies are entirely "model-free", i.e. sensors-to-actions neural networks trained end-to-end. The two are trained independently in two entirely different simulators and then seamlessly co-deployed by feeding the velocity commands from the navigator to the locomotor, entirely "zero-shot" (without any co-training). While prior works have developed learning methods for visual navigation or visual locomotion, to the best of our knowledge, this is the first fully learned approach that leverages vision to accomplish both (1) intelligent navigation in new environments, and (2) intelligent visual locomotion that aims to traverse cluttered environments without disrupting obstacles. On the task of navigation to distant goals in unknown environments, ViNL using just egocentric vision significantly outperforms prior work on robust locomotion using privileged terrain maps (+32.8% success and -4.42 collisions per meter). Additionally, we ablate our locomotion policy to show that each aspect of our approach helps reduce obstacle collisions. Videos and code at http://www.joannetruong.com/projects/vinl.html
Rethinking Sim2Real: Lower Fidelity Simulation Leads to Higher Sim2Real Transfer in Navigation
Jul 21, 2022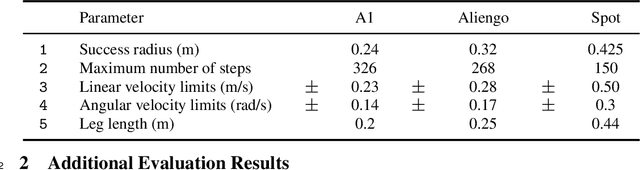
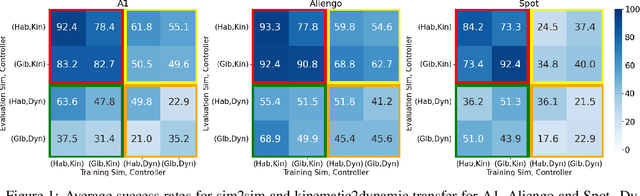


If we want to train robots in simulation before deploying them in reality, it seems natural and almost self-evident to presume that reducing the sim2real gap involves creating simulators of increasing fidelity (since reality is what it is). We challenge this assumption and present a contrary hypothesis -- sim2real transfer of robots may be improved with lower (not higher) fidelity simulation. We conduct a systematic large-scale evaluation of this hypothesis on the problem of visual navigation -- in the real world, and on 2 different simulators (Habitat and iGibson) using 3 different robots (A1, AlienGo, Spot). Our results show that, contrary to expectation, adding fidelity does not help with learning; performance is poor due to slow simulation speed (preventing large-scale learning) and overfitting to inaccuracies in simulation physics. Instead, building simple models of the robot motion using real-world data can improve learning and generalization.
Is Mapping Necessary for Realistic PointGoal Navigation?
Jun 07, 2022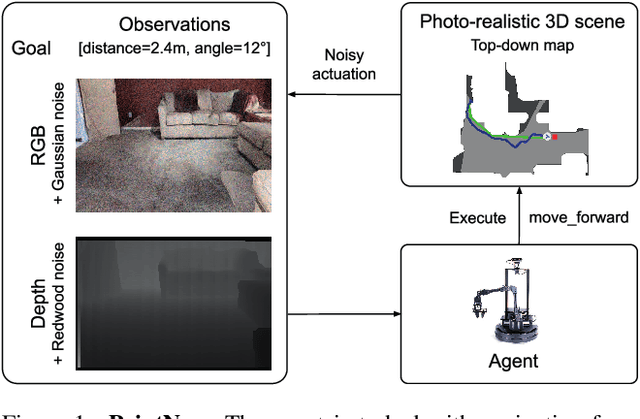
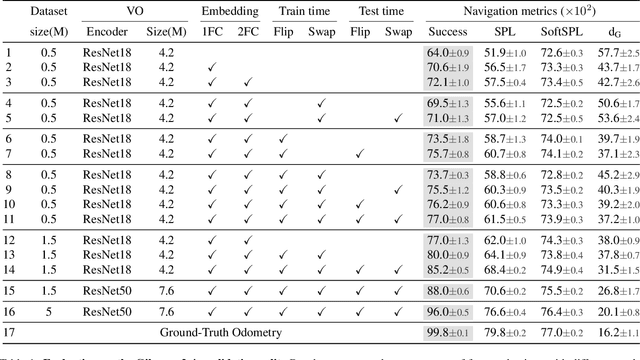
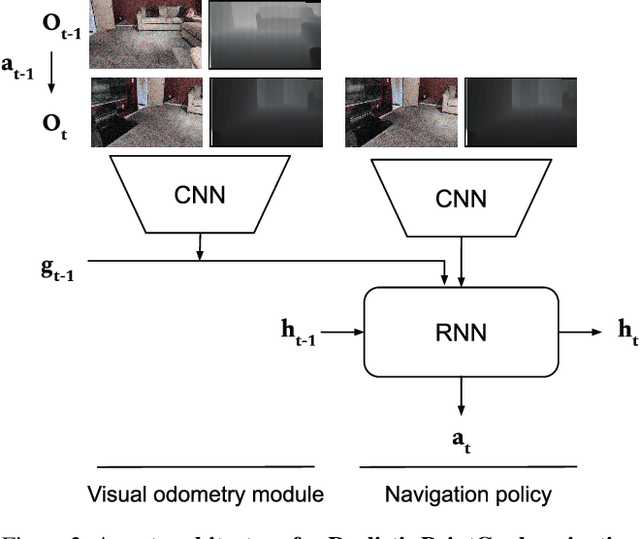
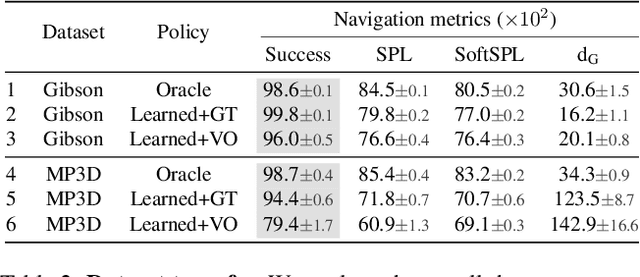
Can an autonomous agent navigate in a new environment without building an explicit map? For the task of PointGoal navigation ('Go to $\Delta x$, $\Delta y$') under idealized settings (no RGB-D and actuation noise, perfect GPS+Compass), the answer is a clear 'yes' - map-less neural models composed of task-agnostic components (CNNs and RNNs) trained with large-scale reinforcement learning achieve 100% Success on a standard dataset (Gibson). However, for PointNav in a realistic setting (RGB-D and actuation noise, no GPS+Compass), this is an open question; one we tackle in this paper. The strongest published result for this task is 71.7% Success. First, we identify the main (perhaps, only) cause of the drop in performance: the absence of GPS+Compass. An agent with perfect GPS+Compass faced with RGB-D sensing and actuation noise achieves 99.8% Success (Gibson-v2 val). This suggests that (to paraphrase a meme) robust visual odometry is all we need for realistic PointNav; if we can achieve that, we can ignore the sensing and actuation noise. With that as our operating hypothesis, we scale the dataset and model size, and develop human-annotation-free data-augmentation techniques to train models for visual odometry. We advance the state of art on the Habitat Realistic PointNav Challenge from 71% to 94% Success (+23, 31% relative) and 53% to 74% SPL (+21, 40% relative). While our approach does not saturate or 'solve' this dataset, this strong improvement combined with promising zero-shot sim2real transfer (to a LoCoBot) provides evidence consistent with the hypothesis that explicit mapping may not be necessary for navigation, even in a realistic setting.
Learning Robust Agents for Visual Navigation in Dynamic Environments: The Winning Entry of iGibson Challenge 2021
Sep 22, 2021
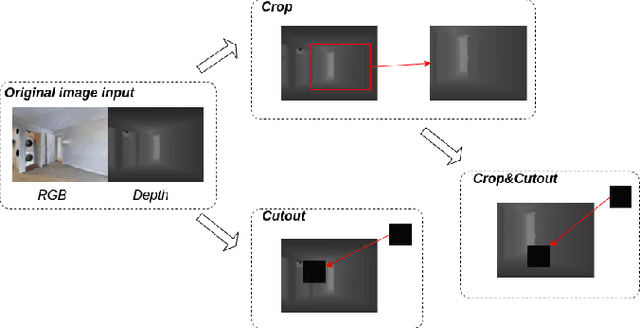
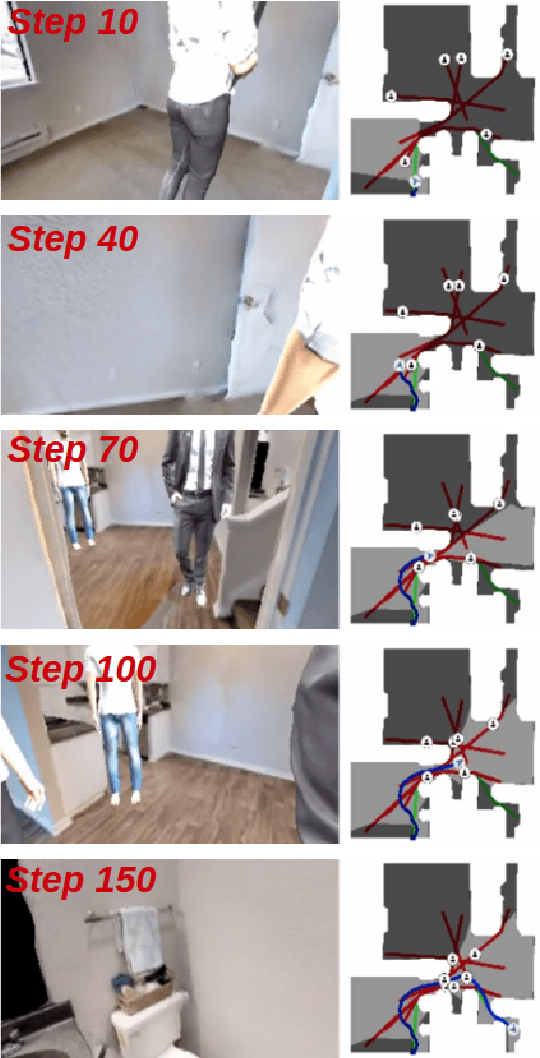
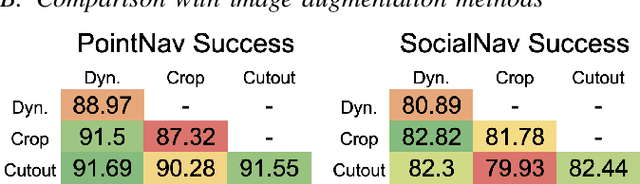
This paper presents an approach for improving navigation in dynamic and interactive environments, which won the 1st place in the iGibson Interactive Navigation Challenge 2021. While the last few years have produced impressive progress on PointGoal Navigation in static environments, relatively little effort has been made on more realistic dynamic environments. The iGibson Challenge proposed two new navigation tasks, Interactive Navigation and Social Navigation, which add displaceable obstacles and moving pedestrians into the simulator environment. Our approach to study these problems uses two key ideas. First, we employ large-scale reinforcement learning by leveraging the Habitat simulator, which supports high performance parallel computing for both simulation and synchronized learning. Second, we employ a new data augmentation technique that adds more dynamic objects into the environment, which can also be combined with traditional image-based augmentation techniques to boost the performance further. Lastly, we achieve sim-to-sim transfer from Habitat to the iGibson simulator, and demonstrate that our proposed methods allow us to train robust agents in dynamic environments with interactive objects or moving humans. Video link: https://www.youtube.com/watch?v=HxUX2HeOSE4
Success Weighted by Completion Time: A Dynamics-Aware Evaluation Criteria for Embodied Navigation
Mar 14, 2021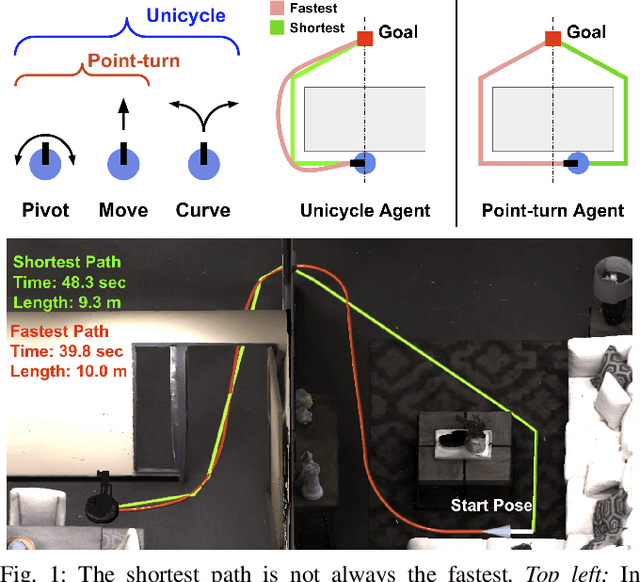
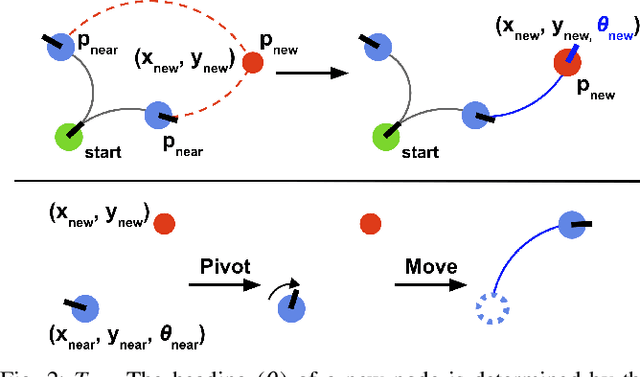

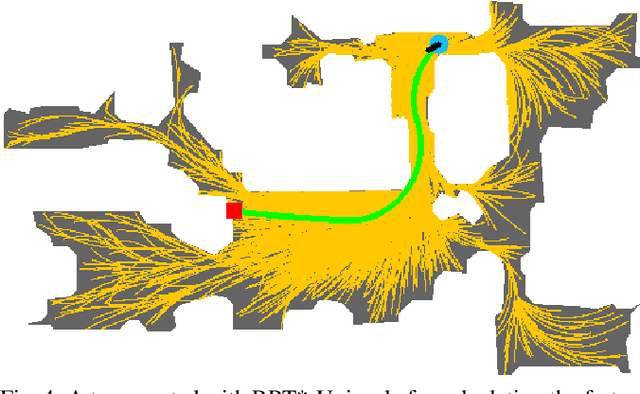
We present Success weighted by Completion Time (SCT), a new metric for evaluating navigation performance for mobile robots. Several related works on navigation have used Success weighted by Path Length (SPL) as the primary method of evaluating the path an agent makes to a goal location, but SPL is limited in its ability to properly evaluate agents with complex dynamics. In contrast, SCT explicitly takes the agent's dynamics model into consideration, and aims to accurately capture how well the agent has approximated the fastest navigation behavior afforded by its dynamics. While several embodied navigation works use point-turn dynamics, we focus on unicycle-cart dynamics for our agent, which better exemplifies the dynamics model of popular mobile robotics platforms (e.g., LoCoBot, TurtleBot, Fetch, etc.). We also present RRT*-Unicycle, an algorithm for unicycle dynamics that estimates the fastest collision-free path and completion time from a starting pose to a goal location in an environment containing obstacles. We experiment with deep reinforcement learning and reward shaping to train and compare the navigation performance of agents with different dynamics models. In evaluating these agents, we show that in contrast to SPL, SCT is able to capture the advantages in navigation speed a unicycle model has over a simpler point-turn model of dynamics. Lastly, we show that we can successfully deploy our trained models and algorithms outside of simulation in the real world. We embody our agents in an real robot to navigate an apartment, and show that they can generalize in a zero-shot manner.